

Den 19.-20. november 2025 udgav OpenAI to relaterede, men forskellige opgraderinger: GPT-5.1-Codex-Max, en ny agentisk kodningsmodel til Codex, der lægger vægt på langsigtet kodning, token-effektivitet og "komprimering" for at understøtte sessioner med flere vinduer; og GPT-5.1 Pro, en opdateret Pro-tier ChatGPT-model, der er tunet til klarere og mere effektive svar i komplekst og professionelt arbejde.
Hvad er GPT-5.1-Codex-Max, og hvilket problem forsøger det at løse?
GPT-5.1-Codex-Max er en specialiseret Codex-model fra OpenAI, der er tunet til kodningsarbejdsgange, der kræver vedvarende, langsigtet ræsonnement og udførelseHvor almindelige modeller kan blive udløst af ekstremt lange kontekster – for eksempel refaktorering af flere filer, komplekse agentløkker eller vedvarende CI/CD-opgaver – er Codex-Max designet til at komprimer og administrer automatisk sessionstilstand på tværs af flere kontekstvinduer, hvilket gør det muligt at fortsætte med at arbejde sammenhængende, da et enkelt projekt strækker sig over mange tusinde (eller flere) tokens. OpenAI positionerer Codex-Max som det næste skridt i at gøre kodekompatible agenter reelt nyttige til udvidet ingeniørarbejde.
Hvad er GPT-5.1-Codex-Max, og hvilket problem forsøger det at løse?
GPT-5.1-Codex-Max er en specialiseret Codex-model fra OpenAI, der er tunet til kodningsarbejdsgange, der kræver vedvarende, langsigtet ræsonnement og udførelseHvor almindelige modeller kan blive udløst af ekstremt lange kontekster – for eksempel refaktorering af flere filer, komplekse agentløkker eller vedvarende CI/CD-opgaver – er Codex-Max designet til at komprimer og administrer automatisk sessionstilstand på tværs af flere kontekstvinduer, hvilket gør det muligt for det at fortsætte med at fungere sammenhængende, da et enkelt projekt strækker sig over mange tusinde (eller flere) tokens.
Den beskrives af OpenAI som "hurtigere, mere intelligent og mere token-effektiv i alle faser af udviklingscyklussen" og er eksplicit beregnet til at erstatte GPT-5.1-Codex som standardmodellen i Codex-overflader.
Funktionsøjebliksbillede
- Komprimering for kontinuitet i flere vinduer: beskærer og bevarer kritisk kontekst for at arbejde sammenhængende over millioner af tokens og timer. 0
- Forbedret token-effektivitet sammenlignet med GPT-5.1-Codex: op til ~30% færre tænketokens for lignende ræsonnementsindsats på nogle kodebenchmarks.
- Langtidsholdbarhed: internt observeret at opretholde agentløkker over flere timer/fler dage (OpenAI dokumenterede >24-timers interne kørsler).
- Platform integrationer: tilgængelig i dag i Codex CLI, IDE-udvidelser, cloud- og kodegennemgangsværktøjer; API-adgang er på vej.
- Understøttelse af Windows-miljøet: OpenAI bemærker specifikt, at Windows for første gang understøttes i Codex-arbejdsgange, hvilket udvider rækkevidden for udviklere i den virkelige verden.
Hvordan klarer det sig i forhold til konkurrerende produkter (f.eks. GitHub Copilot, andre AI'er til kodning)?
GPT-5.1-Codex-Max præsenteres som en mere autonom, langsigtet samarbejdspartner sammenlignet med værktøjer til færdiggørelse pr. anmodning. Mens Copilot og lignende assistenter udmærker sig ved kortsigtede færdiggørelser i editoren, ligger Codex-Max' styrker i at orkestrere flertrinsopgaver, opretholde en sammenhængende tilstand på tværs af sessioner og håndtere arbejdsgange, der kræver planlægning, test og iteration. Når det er sagt, vil den bedste tilgang i de fleste teams være hybrid: brug Codex-Max til kompleks automatisering og vedvarende agentopgaver og brug lettere assistenter til færdiggørelser på linjeniveau.
Hvordan fungerer GPT-5.1-Codex-Max?
Hvad er "komprimering", og hvordan muliggør det langvarigt arbejde?
Et centralt teknisk fremskridt er komprimering—en intern mekanisme, der beskærer sessionshistorikken, samtidig med at de vigtigste dele af konteksten bevares, så modellen kan fortsætte sammenhængende arbejde på tværs flere kontekstvinduer. I praksis betyder det, at Codex-sessioner, der nærmer sig deres kontekstgrænse, vil blive komprimeret (ældre eller lavere værdifulde tokens opsummeres/bevares), så agenten har et nyt vindue og kan fortsætte med at iterere gentagne gange, indtil opgaven er fuldført. OpenAI rapporterer interne kørsler, hvor modellen arbejdede kontinuerligt på opgaver i mere end 24 timer.
Adaptiv ræsonnement og tokeneffektivitet
GPT-5.1-Codex-Max anvender forbedrede ræsonnementsstrategier, der gør den mere token-effektiv: i OpenAIs rapporterede interne benchmarks opnår Max-modellen lignende eller bedre ydeevne end GPT-5.1-Codex, samtidig med at den bruger betydeligt færre "tænkende" tokens – OpenAI citerer omtrent 30% færre tænketokens på SWE-bench verificeret ved kørsel med samme ræsonnementindsats. Modellen introducerer også en "Ekstra høj (xhøj)" ræsonnementindsatstilstand til ikke-latensfølsomme opgaver, der giver den mulighed for at bruge mere intern ræsonnement for at få output af højere kvalitet.
Systemintegrationer og agentværktøjer
Codex-Max distribueres inden for Codex-arbejdsgange (CLI, IDE-udvidelser, cloud og kodegennemgangsflader), så det kan interagere med faktiske udviklerværktøjskæder. Tidlige integrationer inkluderer Codex CLI og IDE-agenter (VS Code, JetBrains osv.), med planlagt API-adgang. Designmålet er ikke kun smartere kodesyntese, men en AI, der kan køre arbejdsgange i flere trin: åbne filer, køre tests, rette fejl, refaktorere og genkøre.
Hvordan klarer GPT-5.1-Codex-Max sig på benchmarks og i virkeligheden?
Vedvarende ræsonnement og opgaver med lang horisont
Evalueringer peger på målbare forbedringer i vedvarende ræsonnement og opgaver med langsigtet perspektiv:
- OpenAI interne evalueringerCodex-Max kan arbejde på opgaver i "mere end 24 timer" i interne eksperimenter, og at integration af Codex med udviklerværktøjer øgede interne produktivitetsmålinger for ingeniører (f.eks. brug og pull request-gennemstrømning). Dette er OpenAI's interne påstande og indikerer forbedringer på opgaveniveau i den faktiske produktivitet.
- **Uafhængige evalueringer (METR)**METR's uafhængige rapport målte observeret 50% tidshorisont (en statistik, der repræsenterer den mediane tid, modellen sammenhængende kan opretholde en lang opgave) for GPT-5.1-Codex-Max på ca. 2 timer 40 minutter (med et bredt konfidensinterval), en stigning fra GPT-5's 2 timer og 17 minutter i sammenlignelige målinger – en meningsfuld trendmæssig forbedring i vedvarende kohærens. METR's metode og konfidensinterval understreger variabilitet, men resultatet understøtter fortællingen om, at Codex-Max forbedrer praktisk ydeevne på lang sigt.
Kode benchmarks
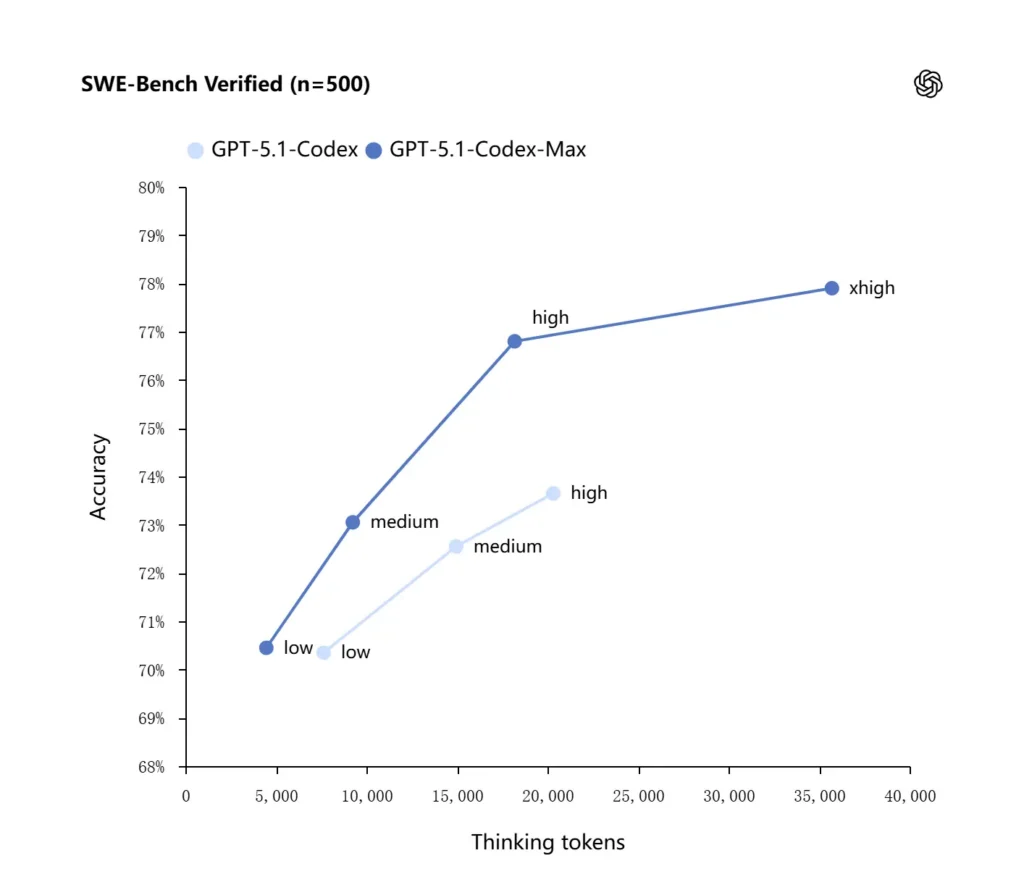
OpenAI rapporterer forbedrede resultater på evalueringer af frontier coding, især SWE-bench Verified, hvor GPT-5.1-Codex-Max overgår GPT-5.1-Codex med bedre token-effektivitet. Virksomheden fremhæver, at Max-modellen for den samme "medium" ræsonnementsindsats producerer bedre resultater, samtidig med at den bruger cirka 30 % færre tænketokens. For brugere, der tillader længere intern ræsonnement, kan xhigh-tilstanden yderligere forbedre svarene på bekostning af latenstid.
| GPT-5.1-Codex (høj) | GPT-5.1-Codex-Max (xhøj) | |
| SWE-bænk verificeret (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminalbænk 2.0 | 52.8% | 58.1% |
Hvordan er GPT-5.1-Codex-Max sammenlignet med GPT-5.1-Codex?
Forskelle i ydeevne og formål
- Anvendelsesområde: GPT-5.1-Codex var en højtydende kodningsvariant af GPT-5.1-familien; Codex Max er eksplicit en agentisk, langsigtet efterfølger, der er beregnet til at være den anbefalede standard for Codex og Codex-lignende miljøer.
- Token-effektivitet: Codex-Max viser betydelige gevinster i token-effektivitet (OpenAIs påstand om ~30% færre thinking tokens) på SWE-bench og i intern brug.
- Konteksthåndtering: Codex-Max introducerer komprimering og indbygget håndtering af flere vinduer for at understøtte opgaver, der overstiger et enkelt kontekstvindue; Codex leverede ikke denne funktion i samme skala.
- Værktøjsberedskab: Codex-Max leveres som standard Codex-model på tværs af CLI-, IDE- og kodegennemgangsflader, hvilket signalerer en migrering til produktionsudvikler-arbejdsgange.
Hvornår skal man bruge hvilken model?
- Brug GPT-5.1-Codex til interaktiv kodningshjælp, hurtige redigeringer, små refaktoreringer og use cases med lavere latenstid, hvor hele den relevante kontekst nemt passer ind i et enkelt vindue.
- Brug GPT-5.1-Codex-Max til refaktorering af flere filer, automatiserede agentopgaver, der kræver mange iterationscyklusser, CI/CD-lignende arbejdsgange, eller når du har brug for, at modellen holder et projektniveauperspektiv på tværs af mange interaktioner.
Praktiske promptmønstre og eksempler for de bedste resultater?
Opfordringsmønstre, der fungerer godt
- Vær tydelig omkring mål og begrænsninger: "Refaktorér X, bevar den offentlige API, behold funktionsnavne og sørg for at test A, B og C består."
- Angiv minimal reproducerbar kontekst: link til den fejlende test, inkluder stakspor og relevante filuddrag i stedet for at gemme hele arkiver. Codex-Max vil komprimere historikken efter behov.
- Brug trinvise instruktioner til komplekse opgaver: opdel store job i en rækkefølge af underopgaver, og lad Codex-Max iterere gennem dem (f.eks. "1) kør tests 2) reparer de 3 mest fejlende tests 3) kør linter 4) opsummer ændringer").
- Bed om forklaringer og forskelle: anmod om både programrettelsen og en kort begrundelse, så menneskelige anmeldere hurtigt kan vurdere sikkerhed og hensigt.
Eksempel på promptskabeloner
Refaktoreringsopgave
"Omstrukturér
payment/modul til at udtrække betalingsbehandling ipayment/processor.pyHold offentlige funktionssignaturer stabile for eksisterende opkaldere. Opret enhedstests forprocess_payment()der dækker succes, netværksfejl og ugyldigt kort. Kør testpakken, og returner fejlede tests og en programrettelse i samlet diff-format.
Fejlrettelse + test
"En prøve
tests/test_user_auth.py::test_token_refreshfejler med traceback . Undersøg rodårsagen, foreslå en løsning med minimale ændringer, og tilføj en enhedstest for at forhindre regression. Anvend patch og kør tests.
Iterativ PR-generering
"Implementer funktion X: tilføj slutpunkt"
POST /api/exportsom streamer eksportresultater og er autentificeret. Opret slutpunktet, tilføj dokumenter, opret tests, og åbn en PR med et resumé og en tjekliste over manuelle elementer.
For de fleste af disse, start med medium indsats; skift til xhøj når du har brug for, at modellen udfører dybdegående ræsonnement på tværs af mange filer og flere testiterationer.
Hvordan får du adgang til GPT-5.1-Codex-Max
Hvor det er tilgængeligt i dag
OpenAI har integreret GPT-5.1-Codex-Max i Codex-værktøj i dag: Codex CLI, IDE-udvidelser, cloud- og kodegennemgangsflows bruger Codex-Max som standard (du kan vælge Codex-Mini). API-tilgængelighed skal forberedes; GitHub Copilot har offentlige forhåndsvisninger, der inkluderer GPT-5.1 og Codex-seriens modeller.
Udviklere kan få adgang til GPT-5.1-Codex-Max og GPT-5.1-Codex API gennem CometAPI. For at begynde, udforsk modellens mulighederCometAPI i Legeplads og se API-vejledningen for detaljerede instruktioner. Før du får adgang, skal du sørge for at være logget ind på CometAPI og have fået API-nøglen. CometAPI tilbyde en pris, der er langt lavere end den officielle pris, for at hjælpe dig med at integrere.
Klar til at gå? → Tilmeld dig CometAPI i dag !
Hvis du vil vide flere tips, guider og nyheder om AI, følg os på VK, X og Discord!
Hurtig start (praktisk trin-for-trin)
- Sørg for at du har adgang til: Bekræft, at din ChatGPT/Codex-produktplan (Plus, Pro, Business, Edu, Enterprise) eller din udvikler-API-plan understøtter GPT-5.1/Codex-familiemodeller.
- Installer Codex CLI- eller IDE-udvidelsen: Hvis du vil køre kodeopgaver lokalt, skal du installere Codex CLI eller Codex IDE-udvidelsen til VS Code / JetBrains / Xcode, alt efter hvad der er relevant. Værktøjerne vil som standard være GPT-5.1-Codex-Max i understøttede opsætninger.
- Vælg ræsonnementsindsats: start med medium indsats for de fleste opgaver. Til dybdegående debugging, komplekse refaktoreringer, eller når du vil have modellen til at tænke mere, og du ikke er interesseret i responsforsinkelse, skal du skifte til høj or xhøj tilstande. Til hurtige små løsninger, lav er rimeligt.
- Angiv kontekst for arkivet: Giv modellen et klart udgangspunkt — en repo-URL eller et sæt filer og en kort instruktion (f.eks. "omstrukturer betalingsmodulet til at bruge asynkron I/O og tilføje enhedstests, beholde funktionsniveaukontrakter"). Codex-Max vil komprimere historikken, når den nærmer sig kontekstgrænser, og fortsætte jobbet.
- Iterer med tests: Når modellen producerer programrettelser, køre testpakker og give feedback om fejl som en del af den igangværende session. Komprimering og kontinuitet i flere vinduer gør det muligt for Codex-Max at bevare vigtig fejlende testkontekst og iterere.
konklusion:
GPT-5.1-Codex-Max repræsenterer et væsentligt skridt mod agentiske kodningsassistenter, der kan udføre komplekse, langvarige ingeniøropgaver med forbedret effektivitet og ræsonnement. De tekniske fremskridt (komprimering, ræsonnementsindsatstilstande, træning i Windows-miljøet) gør den exceptionelt velegnet til moderne ingeniørorganisationer - forudsat at teams kombinerer modellen med konservative driftskontroller, klare "human-in-the-loop"-politikker og robust overvågning. For teams, der anvender den omhyggeligt, har Codex-Max potentiale til at ændre, hvordan software designes, testes og vedligeholdes - og dermed forvandle repetitivt og krævende ingeniørarbejde til et samarbejde med højere værdi mellem mennesker og modeller.