

Alibabas Wan2.7-Image, veröffentlicht am 1. April 2026, stellt einen großen Sprung in der KI-basierten Bildgenerierung dar. Dieses einheitliche Modell integriert Text-zu-Bild-Erstellung, interaktives Editieren, Mehrbild-Komposition und semantisches Verständnis in eine einzige Architektur. Anders als traditionelle, getrennte Pipelines für Generierung und Bearbeitung beseitigt es Inkonsistenzen wie „standardisierte KI-Gesichter“, verzerrten oder unleserlichen Text und unvorhersehbare Farben.
Kreative, Designer, Marketer und Unternehmen erzielen nun fotorealistische, anweisungsgetreue Ergebnisse mit weniger Iterationen. Das Modell unterstützt bis zu 12 sequentielle Bilder, 9 Referenz-Fusionen, 12-sprachiges Textrendering (bis zu 3.000 Token) und pixelgenaue Kontrolle.
Was ist Wan2.7-Image?
Wan2.7-Image ist das Flaggschiff-Universalbildmodell von Alibabas Tongyi Lab innerhalb der Wan- (Tongyi Wanxiang-) Serie. Es deckt End-to-End-Workflows für visuelle Inhalte ab: Text-zu-Bild-Generierung, Bild-zu-Bild-Transformation, befehlsbasiertes Editieren und interaktive, pixelgenaue Verfeinerungen – alles in einem gemeinsamen latenten Raum.
Veröffentlicht am 1. April 2026, baut es auf früheren Wan-2.x-Videomodellen (die die VBench-Benchmarks anführten) auf und verlagert den Fokus auf Bildpräzision. Es geht direkt die „ästhetische Ermüdung“ durch repetitive Gesichter, instabile Farben und schwache Prompt-Ausrichtung an, wie sie in früheren KI-Tools üblich war. Die Modellfamilie umfasst zwei für Nutzer besonders relevante Namen: wan2.7-image und wan2.7-image-pro. Die Standardversion ist auf höhere Generationsgeschwindigkeit optimiert, während die Pro-Version auf professionelle Ausgabe abzielt und 4K-High-Definition unterstützt.
Wichtigster Unterschied: einheitliche Architektur. Traditionelle Modelle verwenden voneinander getrennte Stufen (Encoder → Diffusion → Decoder) und benötigen für Bearbeitungen separates Inpainting. Wan2.7-Image verankert Semantik direkt in einem gemeinsamen Raum, was echtes Verständnis ermöglicht statt bloßes Pixelmuster-Matching.
Warum Wan2.7-Image wichtig ist (Brancheneinordnung)
Traditionelle KI-Bildtools leiden unter:
| Problem | Erklärung |
|---|---|
| Fragmentierter Workflow | Getrennte Tools für Generierung, Bearbeitung, Inpainting |
| „AI-Gesichtssyndrom“ | Repetitive, unrealistische Menschengesichter |
| Schwache Instruktionsausrichtung | Prompts werden nicht genau befolgt |
| Schwaches Textrendering | Verzerrter oder unleserlicher Text |
| Inkonsistente Mehrbild-Ausgabe | Figuren variieren zwischen Frames |
Wan2.7-Image adressiert diese Einschränkungen direkt mit einer einheitlichen Architektur + semantischer Verständnisschicht.
5 Kernfunktionen von Wan2.7-Image
1. Avatar-Anpassung auf Knochenebene für wirklich einzigartige Gesichter
Wan2.7-Image glänzt bei „ein einzigartiges Gesicht für jede Person“. Es unterstützt feingranulare Kontrolle über Knochenstruktur, Augenform (mandelförmig, phönixförmig, tief liegend, geschwollen, lächelnd), Gesichtskonturen und subtile Details. Das eliminiert das Problem der „standardisierten KI-Gesichter“, das frühere Modelle plagte.

Beispiel-Prompt: „Photorealistic portrait of a 28-year-old East Asian woman, oval face, almond-shaped eyes, subtle smile, detailed skin texture, natural lighting.“ Die Ergebnisse zeigen lebensechte Vielfalt – ideal für virtuelle Influencer, Spiel-NPCs oder personalisiertes Branding.
2. Präzise Farbpalettensteuerung
Eine der praxisnahesten Funktionen ist die neue Farbpaletten-Steuerung. Alibaba sagt, Nutzer können spezifische Farbcodes und -anteile eingeben, um künstlerische Stile zu replizieren oder Markenfarben zu fixieren. Die API-Dokumentation formalisiert dies mit einem Parameter color_palette, der 3 bis 10 Farben akzeptiert, wobei 8 empfohlen werden. Für Markenteams ist dies eine der klarsten, unternehmensorientierten Funktionen dieses Releases. Keine zufälligen Farbwechsel mehr – perfekte Konsistenz über Kampagnen hinweg.
Offizielles Zitat: „Verabschieden Sie sich von zufälliger Farbgenerierung. Erzielen Sie präzise Farbverhältnisse und erwecken Sie Ihre kreative Vision zum Leben.“ — Tongyi Wanxiang.
3. Fortgeschrittenes mehrsprachiges Textrendering (12 Sprachen, 3.000 Token)
Rendert ultralangen Text, Tabellen, Formeln, Diagramme und Infografiken mit druckreifer Schärfe (A4-äquivalent). Unterstützt Chinesisch, Englisch, Japanisch, Koreanisch und 8 weitere Sprachen. Fachartikel, Poster, Produktetiketten und mehrsprachige Banner erreichen nahezu perfekte Lesbarkeit – damit wird eine historische Schwäche von KI adressiert.
4. Pixelgenaue interaktive Bearbeitung mit Auswahlrahmen
Nutzen Sie Begrenzungsrahmen (editRegions) oder Auswahlwerkzeuge für zielgerichtete Änderungen. Laden Sie bis zu 9 Referenzen hoch und geben Sie Anweisungen wie „Hintergrund in Strandsonnenuntergang ändern, dabei Gesicht, Pose und Kleidung beibehalten“. Pixelgenaue Präzision gewährleistet Identitätswahrung.
5. Kompositionelle Mehrbild-Generierung (bis zu 12 sequentielle Bilder)
Das Modell ist für mehr als die Einmal-Generierung per Einzel-Prompt ausgelegt. Alibaba sagt, Nutzer können mit bis zu neun Referenzbildern arbeiten und bis zu 12 Bilder auf einmal erzeugen – ideal für kohärente Storyboards, Architektur und E‑Commerce-Serien. Der „Klick-zum-Editieren“-Flow erlaubt die Auswahl spezifischer Bereiche und Änderungen mit Pixelgenauigkeit, und die API-Dokumentation ergänzt interaktives, präzises Editieren über einen Begrenzungsrahmen-Parameter für lokale Bearbeitungen.
Wie funktioniert Wan2.7-Image? (Technischer Deep Dive)
Alibaba beschreibt Wan2.7-Image als ein Framework, das Sprache und visuelle Inhalte durch Training auf großen, diversen Datensätzen verbindet. Einfach gesagt lernt das Modell nicht nur, wie man Bilder zeichnet; es lernt auch, wie Prompts auf visuelle Struktur, Komposition, Beleuchtung und Textplatzierung abgebildet werden. Das ermöglicht eine genauere Interpretation der Nutzerintention als bei einem einfachen Text-zu-Bild-System.
Die API zeigt zudem, dass das Modell für multimodale Eingaben gebaut ist. In der Praxis werden Anfragen über eine Ein-Turn-Nachrichtenstruktur gesendet, und der Inhalt kann sowohl Text- als auch Bild-Elemente enthalten. Für Bearbeitungen können Nutzer mehrere Bilder plus Anweisungen wie „verschieben“, „ersetzen“ oder „mischen“ übergeben, um das Ergebnis zu steuern. Das ist ein klarer Hinweis darauf, dass Wan2.7 als Prompt-und-Referenz-System entworfen ist, nicht als einfacher One-Shot-Generator.
Die Doku legt außerdem eine Einstellung für den Thinking-Mode offen. Er ist standardmäßig aktiviert und kann die Ausgabequalität verbessern, erhöht aber die Generationszeit. Das ist ein nützlicher Hinweis auf den Workflow des Modells: Höherwertige Ausgaben können mehr interne Inferenzzeit erfordern, besonders wenn die Anfrage textlastig oder visuell komplex ist.
Wan2.7-Image nutzt ein vereinheitlichtes Generierungs-/Editier-Framework in einem gemeinsamen latenten Raum:
- Eingabestufe: Text-Prompt (bis zu 3.000 Token) + optionale Referenzbilder (bis zu 9).
- Semantisches Parsing & Thinking-Mode (im Pro erweitert): Chain-of-Thought-Reasoning analysiert Komposition, räumliche Beziehungen, Beleuchtung und Logik, bevor Pixel generiert werden.
- Abbildung in den gemeinsamen latenten Raum: Semantik wird direkt auf visuelle Merkmale gemappt – ohne voneinander getrennte Encoder/Decoder-Lücken.
- Vereinheitlichte Inferenz: Generierung oder Bearbeitung erfolgt in einem optimierten Ablauf. Bearbeitungsbereiche nutzen Begrenzungsrahmen; Farbpaletten erzwingen Verhältnisse.
- Ausgabe: Hochwertige Bilder (768–2048×2048 Standard; 4K in Pro) mit Optionen für JPG/PNG/WEBP, Seeds für Reproduzierbarkeit und Sicherheitsprüfungen.
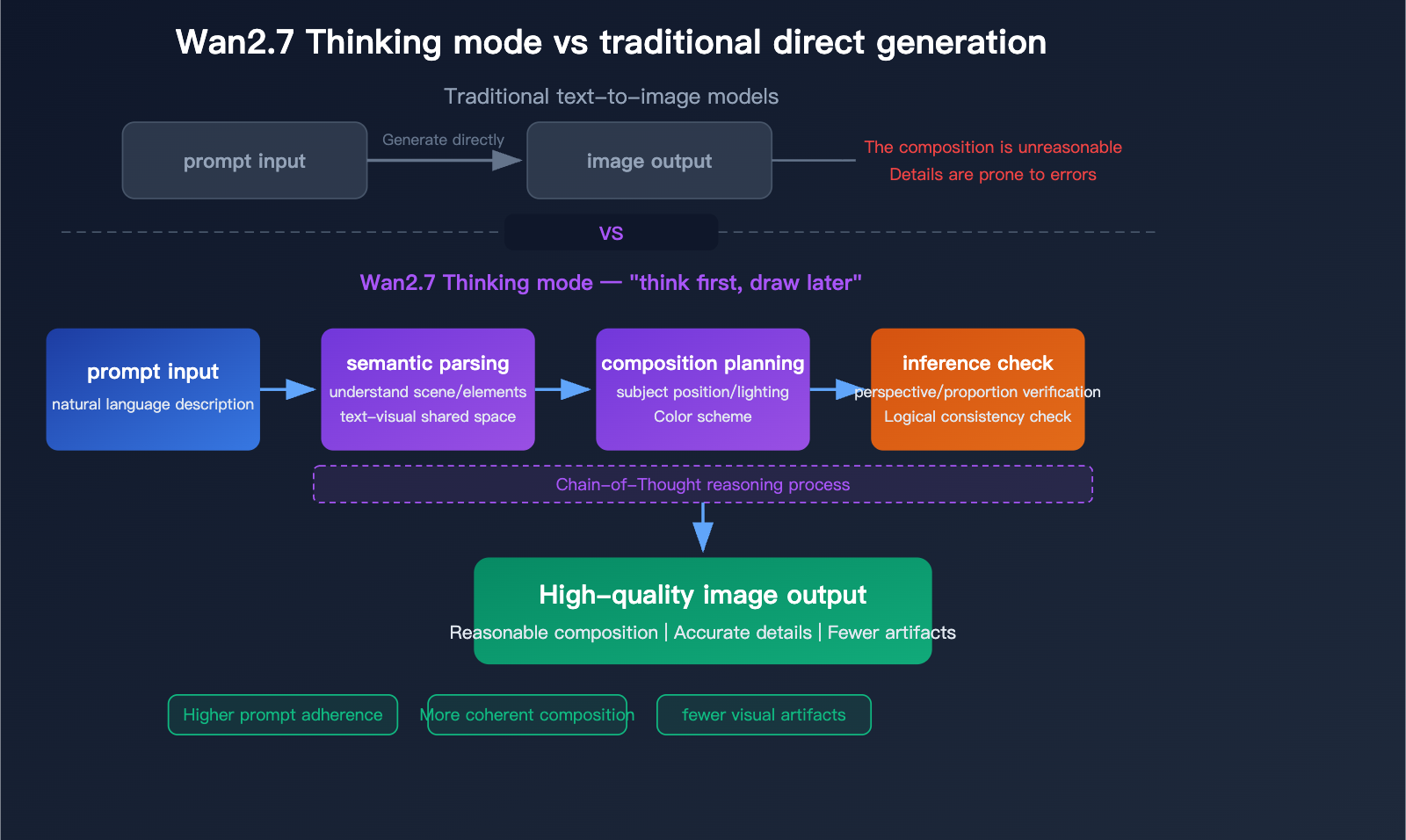
Tiefgehende Analyse von Wan2.7-Image-Pro: Eine neue Benchmark für KI-Bildgenerierung mit 4K-Qualität, Reasoning-Mode und 12-sprachigem Textrendering – Apiyi.com Blog
Das Flussdiagramm des Thinking-Mode (Pro) zeigt semantisches Parsing → Kompositionsplanung → Inferenz-Check, was zu weniger Artefakten und höherer Prompt-Compliance gegenüber direkter Generierung führt.
Training auf diversen Datensätzen ermöglicht ein tiefes Verständnis von Intention, Beleuchtung und Layout. Langkontext-Lernen (in arXiv-Studien referenziert) treibt die erweiterte Textverarbeitung.
Wan2.7-Image vs. Wan2.7-Image-Pro: Zentrale Unterschiede
Beide Versionen starten gleichzeitig, aber Pro zielt auf professionelle Bedürfnisse.
| Funktion | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Am besten geeignet für |
|---|---|---|---|
| Maximale Auflösung | 2048×2048 | 4096×4096 (4K) | Druck/Produktion (Pro) |
| Thinking-Mode | Verfügbar (schnelleres Default) | Erweitert/Standard mit tieferem Reasoning | Komplexe Szenen (Pro) |
| Kompositionsstabilität | Stark | Überlegenes semantisches Verständnis | Kommerzielle Projekte (Pro) |
| Geschwindigkeit vs. Qualität | Schnellere Iteration | Höhere Wiedergabetreue, etwas längere Zeit | Prototyping (Standard) |
| Anwendungsfall | Allgemeine Creator, Social-Content | Enterprise-Design, akademisch/Druck | Skalierbarkeit vs. Präzision |
Standard eignet sich für schnelles Prototyping; Pro liefert druckfertiges 4K mit überlegener Konsistenz.
So verwenden Sie Wan2.7-Image (Schritt für Schritt)
1. Plattformzugang
Verfügbar über:
- Alibaba Cloud (BaiLian-Plattform)
- Offizielle Wanxiang-Tools
- CometAPI
2. Workflow-Modus wählen
Modus A: Text-zu-Bild
Prompt-Beispiel:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Modus B: Bildbearbeitung
- Bild hochladen
- Bereich auswählen
- Anweisung eingeben
Beispiel:
Replace background with a futuristic city
Mode C: Mehrbild-Komposition
- Mehrere Referenzen hochladen
- Kompositionsregeln definieren
3. Parameter feinabstimmen
- Farbpalette
- Stil-Konsistenz
- Textrendering
4. Ausgabe exportieren
- Hochauflösende Bilder
- Kommerzfertige Assets
Benchmark-Leistung und Wettbewerbsvergleich
In verblindeten Präferenztests mit Menschen übertrifft Wan2.7-Image GPT-Image-1.5 in der Text-zu-Bild-Qualität und erreicht oder übertrifft Nano Banana Pro beim Textrendering, der Fotorealistik und dem Weltwissen.
Vergleichstabelle:
| Modell | Textrendering | Anweisungsbefolgung | Avatar-Anpassung | Mehrbild-Referenzen | Vereinheitlichte Generierung/Bearbeitung | Auflösung | Open-Source/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Exzellent (12 Sprachen) | Überlegen (Thinking-Mode) | Knochenebene | 9 | Ja | 2K–4K | Ja/API |
| Midjourney V8 | Gut | Mittel | Stark künstlerisch | Begrenzt | Nein | Hoch | Nur Discord |
| FLUX | Gut | Stark (einfach) | Gut | Begrenzt | Nein | Hoch | Ja |
| DALL-E 3 | Mittel | Gut | Mittel | Nein | Nein | 2K | API |
| Nano Banana Pro | Stark | Starke Bearbeitung | Gut | Stark | Teilweise | Hoch | Geschlossen |
Wan2.7-Image führt bei vereinheitlichtem Workflow, mehrsprachigem Text und präziser Kontrolle – besonders wertvoll für nicht-englische Märkte und professionelle Pipelines.
CometAPI ist eine One-Stop-Aggregationsplattform für große Modell-APIs, die nahtlose Integration und Verwaltung von API-Services bietet. Sie unterstützt mehrere Bildgenerierungs-APIs, wie GPT-image-1.5, Nano Banana series, Midjourney und Qwen Image Series usw., zu einem günstigeren Preis als auf der offiziellen Website.
Wer sollte Wan2.7-Image verwenden
Wan2.7-Image ist besonders relevant für Teams, die Geschwindigkeit und Flexibilität benötigen statt nur einmaliger Kunstgenerierung. Dazu gehören Performance-Marketer, Produktdesigner, E‑Commerce-Studios, Social-Content-Teams und Agenturen, die viele Varianten aus dem gleichen Briefing produzieren. Die Unterstützung für Mehrbildeingaben, Mehrfachausgaben und anweisungsbasiertes Editieren macht das Modell besonders attraktiv für Workflows, in denen Konsistenz, Geschwindigkeit und Prompt-Kontrolle zählen.
Praxisnahe Einsatzszenarien
- Gaming/Entertainment: In Minuten 100 einzigartige NPCs generieren.
- Marketing/E-Commerce: Marken-konsistente Karussells mit exakten Farbpaletten.
- Bildung/Akademia: Druckfertige Poster mit Formeln und Tabellen.
- Designagenturen: Storyboards und Kundenrevisionen via interaktivem Editieren.
Produktivitätsgewinne resultieren aus weniger Iterationen und nahtloser Referenzintegration.
Fazit:
Alibaba Wan2.7-Image definiert kreative KI neu, indem es Generierung, Bearbeitung und Verständnis vereint. Seine 5 Kernfunktionen, der geteilte latente Raum und die Pro-Verbesserungen liefern professionelle Ergebnisse, an denen Wettbewerber weiterhin zu knabbern haben. Ob beim Prototyping von Social-Content oder bei der Produktion druckreifer akademischer Visuals: Es bietet unerreichte Präzision und Effizienz.
Starten Sie noch heute auf wan.video oder per API über CometAPI. Für Entwickler und Unternehmen macht die Kombination aus Leistung, Zugänglichkeit und datenbasiert belegter Überlegenheit Wan2.7-Image zum klaren Marktführer unter den einheitlichen KI-Bildmodellen für 2026 und darüber hinaus.