

GLM-5-Turbo ist ein neues Foundation-LLM von Zhipu AI, das speziell für agentenartige Workflows trainiert und optimiert wurde (das Unternehmen bezeichnet das Ziel-Ökosystem als OpenClaw bzw. „Lobster“-Szenarien). Es bietet einen sehr langen Kontext (bis zu ~200K Token), Streaming und strukturierte Ausgaben, niedrigere Tool-Call-Fehlerraten (berichtet ~0,67 % in Tests von Drittanbietern) sowie deutlich niedrigere Preise pro Token. Das Modell zielt darauf ab, eine kleine Menge an maximalem Single-Turn-Durchsatz gegen deutlich bessere Stabilität, Tool-Zuverlässigkeit, geplante/persistente Aufgabenbearbeitung und Long-Chain-Ausführung einzutauschen — nützlich für autonome Agenten, Orchestrierungssysteme und Multi-Tool-Pipelines.
Was ist GLM-5-Turbo?
GLM-5-Turbo wird von Zhipu als Foundation-Modell präsentiert, das speziell für Agenten-Orchestrierung und komplexe automatisierte Workflows entwickelt wurde, und nicht als allgemeines Chat- oder multimodales Modell. Die Designentscheidungen betonen:
- Native agentenfreundliche Trainingsziele (Tool-Nutzung, Befolgung von Anweisungen, zeitgesteuerte/persistente Aufgaben).
- Sehr große Kontextfenster und Ausgabekapazität zur Unterstützung langer Sitzungen, von Speicher und Chain-of-Thought-Planung.
- Stabile Inferenz mit hohem Durchsatz für lange geschäftliche Abläufe und geplante Aufgaben.
Im Gegensatz zu traditionellen LLMs, die für Chat oder Textgenerierung optimiert sind, ist GLM-5-Turbo:
- Agent-first (nicht chat-first)
- Für OpenClaw- („Lobster“-)Umgebungen gebaut
- Für mehrstufige autonome Workflows konzipiert
🦞 Was bedeutet „Lobster Agent“?
Das „Lobster“-Konzept bezieht sich auf OpenClaw, Zhipus KI-Agenten-Ökosystem, in dem Modelle:
- Tools dynamisch verwenden
- Lange Aufgabenketten ausführen
- Persistenten Speicher aufrechterhalten
- Über Terminals, Apps und APIs hinweg arbeiten
GLM-5-Turbo ist tief auf dieses Paradigma optimiert und löst zentrale Agentenprobleme wie:
- Tool-Call-Zuverlässigkeit
- Aufgabenzerlegung
- Langfristige Planung
- Ausführungsstabilität
Hauptmerkmale und warum sie wichtig sind
Langer Kontext + enorme Ausgabekapazität (200K / 128K)
Ein Kontextfenster von 200K Token und eine Ausgabekapazität von 128K erlauben GLM-5-Turbo:
- Einen erweiterten Speicher des vorherigen Kontexts beizubehalten (Unterhaltungen, Tool-Ausgaben, Zwischenergebnisse).
- Sehr lange generierte Artefakte zu erzeugen (mehrstufige Pläne, lange Berichte, Codebasen), ohne wiederholt Kontext zusammenfügen zu müssen.
- Multi-Turn-Agenten zu hosten, die für präzise Entscheidungsfindung den vollständigen Ausführungsverlauf beibehalten müssen.
Dies ist eine bewusste technische Entscheidung für Agenten — statt Aufgaben in kurze Prompts aufzuteilen, können Agenten über Tausende von Gesprächsrunden oder Schritten hinweg einen kohärenten Zustand beibehalten.
In das Training integrierte Agenten-Primitiven
Anstatt ein Allzweckmodell nachträglich an Agentenaufgaben anzupassen, wurde GLM-5-Turbo mit agentenartigen Zielen trainiert (z. B. Verhalten bei Tool-Aufrufen, Parsing von Befehlen/Argumenten). Der behauptete Effekt sind weniger Halluzinationen bei Tool-Aufrufen, stabilere mehrstufige Pläne und verbesserte Latenz bei langen Läufen — alles wertvoll dort, wo Automatisierung viele externe APIs oder Tools zuverlässig verketten muss.
Durchsatz und Ausführungsstabilität
Die Variante GLM-5-Turbo verbessert Ausführungsstabilität und Durchsatz für lange geschäftliche Abläufe im Vergleich zu generalisierten großen Modellen — die Marketing-Sprache betont „Ausführung mit hohem Durchsatz“ und „führende Antwortstabilität“ unter ähnlichen Modellen. Das ist für Enterprise-Agent-Deployments relevant, bei denen ein fehlgeschlagener Schritt eine gesamte Pipeline unterbrechen kann. Unabhängige Benchmarks von Drittanbietern sind noch im Entstehen.
Benchmark-Daten von GLM-5-Turbo
Hinweis: Zhipu hat interne Evaluierungen veröffentlicht, und Benchmarks von Drittanbietern bzw. aus dem akademischen Bereich für GLM-5 sind verfügbar. GLM-5-Turbo wurde erst kürzlich veröffentlicht; unabhängige Community-Benchmarkläufe werden Zeit brauchen. Nachfolgend listen wir die belastbarsten veröffentlichten Kennzahlen und den Kontext auf.
GLM-5 (Referenz) — repräsentative veröffentlichte Kennzahlen
Zhipus GLM-5 (der Flaggschiff-Vorgänger von Turbo) berichtet starke Leaderboards in vielen Engineering-/Workflow-Aufgaben — zum Beispiel:
- SWE-bench Verified: 77,8 (in der GLM-5-Dokumentation als führender Open-Model-Score berichtet).
- Terminal Bench 2.0: 56,2 (als beste Open-Model-Leistung auf der angegebenen Verteilung berichtet).
Diese Zahlen etablieren GLM-5 als hohe Baseline für Software-Engineering- und Ausführungsaufgaben; GLM-5-Turbo ist so positioniert, dass es etwas Rohleistung bzw. Größen-/Parameterfokus gegen bessere Agenten-Zuverlässigkeit und höheren Durchsatz eintauscht. GLM-5-Turbo zeigte in ihren Vergleichsläufen ~0,67 % Tool-Call-Fehler, deutlich niedriger als vergleichbare GLM-5-Provider-Läufe mit ~2,33 % bis 6,41 %.
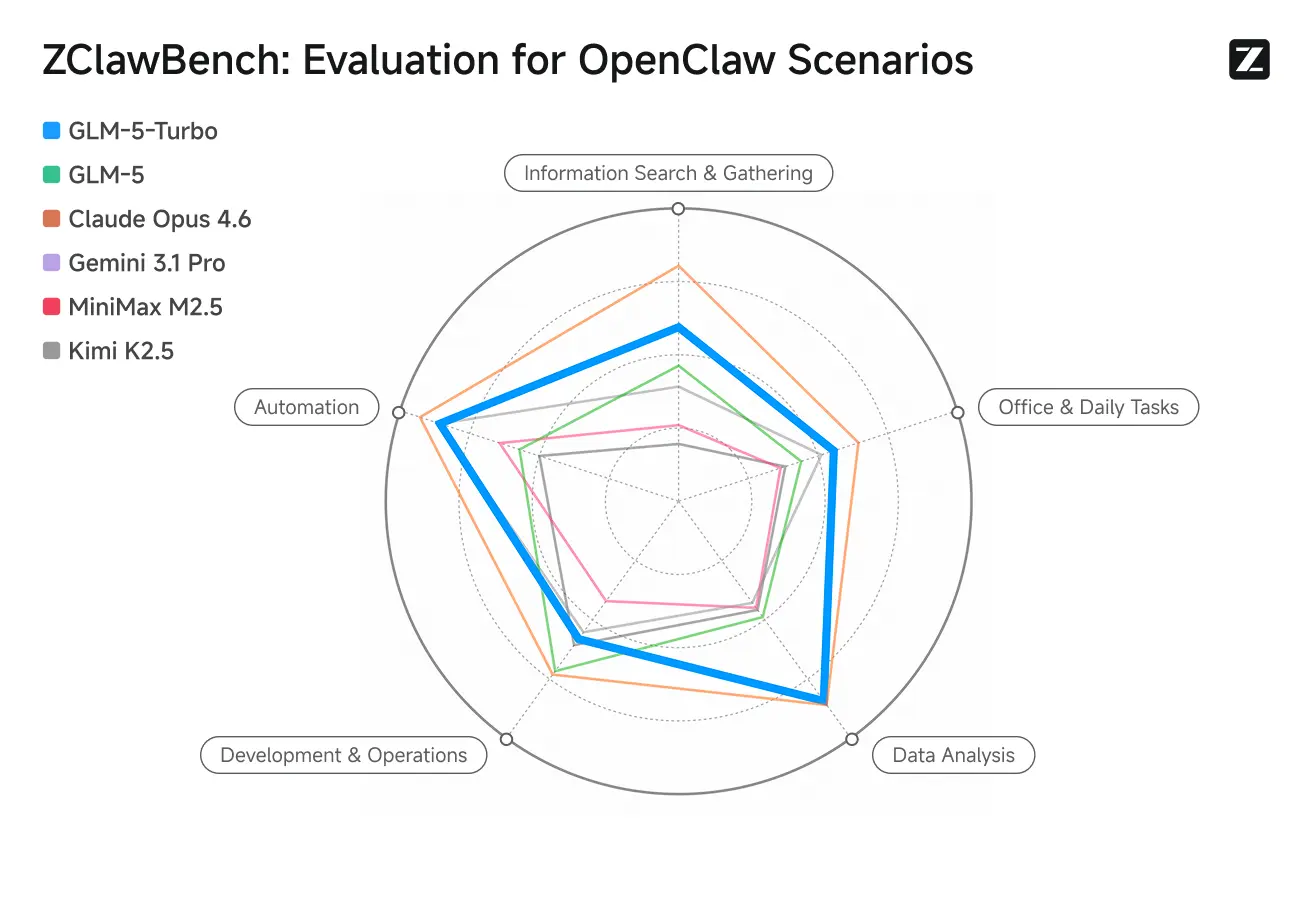
ZClawBench: Benchmark-Test für OpenClaw-Proxy-Szenarien
Zhipu hat außerdem den Benchmark ZClawBench zur Bewertung intelligenter Agenten veröffentlicht. In Blindtests, die verschiedene Bereiche wie Code-Entwicklung, Datenanalyse und Content-Erstellung abdeckten, gewann das neue Modell mit dem Codenamen Pony-Alpha-2 die Zustimmung von 90 % der Befragten.
Preise & Verfügbarkeit (wer es anbietet und wie viel es kostet)
Zhipu führte bei der Einführung für GLM-5-Turbo eine API-Preiserhöhung von ~20 % ein und stellte gleichzeitig Abonnementstufen namens „Lobster Package“ vor, die die Token-Preisgestaltung für Agenten-Deployments glätten sollen.
Berichtete Abonnementstufen (Beispielpakete)
Zwei beispielhafte Lobster-Pakete (die Preise sind berichtete Umrechnungen und ungefähr):
- Entry Lobster plan: ~39 CNY / Monat (~US$5,66) für 35.000.000 Token.
- Mid Lobster plan: ~99 CNY / Monat (~US$14,36) für 100.000.000 Token.
Auf Grundlage dieser veröffentlichten Zahlen betragen die Kosten pro 1 Million Token ungefähr:
- Entry-Plan: ~US$0,162 pro 1 Mio. Token.
- Mid-Plan: ~US$0,144 pro 1 Mio. Token.
Diese Werte pro 1 Mio. sind einfache Umrechnungen der veröffentlichten Abonnementkosten und Token-Obergrenzen und veranschaulichen die Ökonomie für Agenten-Workloads mit hohem Volumen. (Berechnungen basieren auf den in der Presse berichteten Währungs- und Tokenmengen.)
API-Preis
Repräsentative Marketplace-Auflistung (CometAPI): $0,96 pro 1 Mio. Eingabetoken und $3,20 pro 1 Mio. Ausgabetoken für GLM-5-Turbo.
Zhipus eigene Entwickler-Preisseite (Z.ai) listet einen etwas höheren Direktpreis für GLM-5-Turbo: $1,20 pro 1 Mio. Eingabetoken und $4,00 pro 1 Mio. Ausgabetoken (Preise für gecachte Eingaben sind niedriger).
GLM-5-Turbo vs. GLM-5 — Vergleich nebeneinander
Auf hohem Niveau:
- GLM-5 = Flaggschiff-Foundation-Modell für allgemeine Zwecke (stark in Reasoning, Coding, Benchmarks)
- GLM-5-Turbo = agentenoptimierte Variante von GLM-5 (fokussiert auf lange Workflows, Tool-Nutzung, Stabilität)
GLM-5-Turbo ist keine völlig neue Modellarchitektur, sondern eine spezialisierte, produktionsoptimierte Version von GLM-5, die für Agentensysteme wie OpenClaw entwickelt wurde.
Kernpositionierung
| Modell | Positionierung |
|---|---|
| GLM-5 | Flaggschiff-LLM für allgemeine Zwecke (Reasoning, Coding, Benchmarks) |
| GLM-5-Turbo | Agent-first-Modell (Automatisierung, Orchestrierung, Tool-Nutzung) |
👉 Einfach ausgedrückt:
- Verwende GLM-5 → wenn du maximale Intelligenz möchtest
- Verwende GLM-5-Turbo → wenn du stabile Automatisierung / Agenten möchtest
Vergleich der Agentenfähigkeiten (AM WICHTIGSTEN)
GLM-5 (Agentenfähigkeit) unterstützt bereits:
- Tool-Nutzung
- Mehrstufiges Reasoning
- Coding-Agenten
Aber Einschränkungen:
- Kann in langen Ketten den Kontext verlieren
- Tool-Aufrufe können sich mit der Zeit verschlechtern
- Erfordert mehr Orchestrierungslogik
GLM-5-Turbo ist explizit für Agenten optimiert:
Wichtige Verbesserungen:
- Tool-Calling-Zuverlässigkeit ↑
- Aufgabenzerlegung (Planung) ↑
- Konsistenz in langen Ketten ↑
- Unterstützung persistenter Ausführung ↑
Beispiel für eine Verbesserung:
- Stabile Ausführung über 10+ Schritte hinweg, ohne den Kontext zu verlieren
👉 Das ist entscheidend für:
- Systeme im Stil von AutoGPT
- Multi-Agent-Workflows
- SaaS-Automatisierung
Geschwindigkeit & Effizienz
| Aspekt | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inferenzgeschwindigkeit | Mittel | Schneller |
| Durchsatz | Standard | Höher |
| Latenz bei langen Aufgaben | Kann sich verschlechtern | Optimiert |
GLM-5-Turbo wurde entwickelt, um ein reales Branchenproblem zu lösen:
Große Modelle werden bei langen Workflows langsamer oder brechen zusammen
Preisvergleich
| Modell | Eingabe ($/1M Token) | Ausgabe ($/1M Token) |
|---|---|---|
| GLM-5 | ~$1,00 | ~$3,20 |
| GLM-5-Turbo | ~$1,20 | ~$4,00 |
👉 GLM-5-Turbo ist teurer (~20 % höher)
Warum teurer?
Weil es bietet:
- Bessere Orchestrierungszuverlässigkeit
- Höhere Produktionsstabilität
- Agentenspezifische Optimierungen
👉 Im Enterprise-Bereich:
- Du zahlst mehr pro Token
- reduzierst aber Fehlerkosten + Wiederholungsversuche
| Attribut | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primäres Ziel | Allgemeines Flaggschiff-Foundation-Modell (breite Fähigkeiten, starkes Coding/Benchmarks) | Agenten-/„OpenClaw“-/Lobster-optimiertes Foundation-Modell |
| Kontextfenster | (berichtet hoch; GLM-5 fokussiert ~200K (GLM-5 unterstützt ebenfalls langen Kontext) | 200.000 Token (explizit dokumentiert). |
| Maximale Ausgabetoken | (groß, modellabhängig) | 128.000 Token (dokumentiert). |
| Bemerkenswerte Benchmark-Scores | SWE-bench: 77,8; Terminal Bench 2.0: 56,2 (von GLM-5 berichtete Zahlen). | Interne Evaluierungen beanspruchen verbesserte Long-Chain-Stabilität und höheren Durchsatz für Agenten-Workflows; unabhängige öffentliche Benchmarks stehen noch aus. |
| Modalitäten | Text (primär), die GLM-Familie hat Vision-Varianten in Schwester-Modellen | Nur Text (laut Dokumentation) — optimiert für toolbasierte Agenten. |
| Empfohlene Anwendungsfälle | Breit: Chat, Code, Reasoning, Inhalte | Agenten-Orchestrierung, Tool-Aufruf, Automatisierung mit langem Horizont |
| Preisgestaltung | Bestehende GLM-5-Preise (je nach Tarif unterschiedlich) | Neuer Launch — berichtete API-Preiserhöhung von ~20 %; neue Lobster-Abonnementstufen eingeführt |
So verwendest du GLM-5-Turbo
CometAPI — ein einzelner API-Zugang zu vielen Modellen (OpenAI-kompatibel)
CometAPI listet GLM-5-Turbo als verfügbar und stellt eine OpenAI-kompatible Base-URL sowie ein SDK bereit. Verwende den von ihnen veröffentlichten Modell-String (ihre Website listet GLM-5-Turbo zu ähnlichen Preisen). Beispiele, angepasst aus den CometAPI-Dokumenten:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
Der Mehrwert von CometAPI liegt in der Aggregator-Bequemlichkeit (eine einzige Integration für viele Modelle). Bestätige vor dem Aufruf den genauen Modell-Slug im CometAPI-Dashboard.
Best Practices beim Aufbau von Lobster-/OpenClaw-Agenten mit GLM-5-Turbo
- Für Zuverlässigkeit entwerfen, nicht für rohe Latenz: Turbos Vorteil liegt in geringeren Tool-Call-Fehlern in langen Ketten. Strukturiere Agentenläufe so, dass robuste Abschlüsse bevorzugt werden (Wiederholungsversuche, idempotente Tool-Aufrufe) statt minimaler Vorteile bei der Time-to-First-Token.
- Streaming und inkrementelle Tool-Aufrufe verwenden: Nutze Streaming/segmentierte Ausgaben, um Nacharbeit zu reduzieren und frühe Tool-Aufrufe dort zu ermöglichen, wo es sinnvoll ist. GLM-5-Turbo unterstützt Streaming.
- Strukturierte Ausgaben für Parser: Bevorzuge JSON oder gut formatierte Ergebnisse für deterministisches nachgelagertes Tool-Parsing. Turbo unterstützt strukturierte Ausgaben.
- Für Planung / Persistenz planen: Wenn dein Agent periodisch prüfen oder Hintergrundaufgaben ausführen muss, nutze Turbos bessere Zeitsemantik und Caching-Funktionen, um in jedem Zyklus eine Neuplanung zu vermeiden.
- Tool-Aufrufe und Fallbacks instrumentieren: Protokolliere Tool-Aufrufe und entwerfe elegante Fallbacks (z. B. erneuter Versuch mit leicht veränderter Temperatur oder Aufruf eines Backup-Tools), da agentische Workflows fragil sind, wenn eine einzelne externe API ausfällt. Turbo reduziert Fehlerraten, beseitigt externe Ausfälle jedoch nicht.
Entwickler können jetzt über CometAPI auf die APIs von GLM-5 und GLM-5 turbo zugreifen. Konsultiere zunächst den API guide für detaillierte Anweisungen. Bevor du zugreifst, stelle bitte sicher, dass du dich bei CometAPI angemeldet und den API-Schlüssel erhalten hast. CometAPI offer einen Preis weit unter dem offiziellen Preis, um dir die Integration zu erleichtern.
Bereit loszulegen?→ Melde dich noch heute für GLM-5 und GLM-5 turbo an !