
.png&w=3840&q=75)
GPT-5.4 Mini und GPT-5.4 Nano sind OpenAIs neue kompakte Varianten seiner GPT-5.4-Frontier-Familie: Mini zielt auf ein klassenbestes Verhältnis von Leistung zu Latenz für Coding, multimodale UI-Aufgaben und Subagenten-Workloads; Nano zielt auf extrem niedrige Kosten und Latenz für Klassifizierung, Extraktion, Ranking und massiv parallelisierte Subagenten. Mini bietet auf vielen Entwickler-Benchmarks eine Genauigkeit nahe dem Frontier-Niveau und läuft dabei >2× schneller als frühere Minis; Nano ist pro Token deutlich günstiger und ideal, wenn Durchsatz und Reaktionsfähigkeit am wichtigsten sind. Diese Modelle sind in der API live (GPT 5.4 Mini und Nano sind in CometAPI verfügbar).
Was sind GPT-5.4 Mini und GPT-5.4 Nano?
Kurze Definition: GPT-5.4 Mini und GPT-5.4 Nano sind kompakte, technisch optimierte Varianten der GPT-5.4-Familie, die entwickelt wurden, um die Kernstärken des großen GPT-5.4 (Reasoning, Coding, multimodale Wahrnehmung, Tool-Nutzung) in schnellere, kostengünstigere Modelle zu übertragen, die auf hochvolumige Workloads mit niedriger Latenz ausgerichtet sind. Die Modelle wurden von OpenAI im Rahmen der Einführung von GPT-5.4 angekündigt.
- GPT-5.4 Mini — Ein leistungsstarkes kleines Modell, das „bei mehreren Evaluierungen an die Leistung von GPT-5.4 heranreicht“, während es für Geschwindigkeit und geringere Kosten optimiert ist. Es wird speziell für Coding, Reasoning, multimodale UI-Interpretation (Screenshots) und als Subagent in agentischen Systemen hervorgehoben. OpenAI berichtet, dass es mehr als 2× schneller läuft als frühere „Mini“-Varianten.
- GPT-5.4 Nano — Die kleinste und günstigste GPT-5.4-Variante; empfohlen für Klassifizierung, Extraktion, Ranking und „unterstützende“ Subagenten, die eng umrissene, repetitive Aufgaben mit sehr hohem Durchsatz erledigen. Es tauscht tieferes Reasoning gegen geringere Latenz und niedrigere Kosten ein.
Verfügbarkeit und Preis
OpenAI liefert zwei konkrete Vergleichswerte, mit denen sich die Kosten einordnen lassen:
- GPT-5.4 (vollständiges Flaggschiff) API-Eingabepreis: 2,50 $ / 1 Mio. Tokens (und höhere Ausgabepreise beim Flaggschiff).
- GPT-5.4 mini API-Eingabepreis: 0,75 $ / 1 Mio. Tokens und Ausgabe 4,50 $ / 1 Mio. Tokens.
- GPT-5.4 nano API-Eingabepreis: 0,20 $ / 1 Mio. und Ausgabe 1,25 $ / 1 Mio..
Nebeneinandergestellt bedeutet das: Minis Eingabe-Token-Preis (0,75) beträgt 30 % des Flaggschiffs (2,50), also ungefähr ein Drittel der Eingabekosten; Minis Ausgabepreis (4,50) liegt bei etwa 32 % eines im API-Preisblatt genannten Flaggschiff-Ausgabepreises, also ebenfalls ungefähr bei einem Drittel. Nano ist noch günstiger: Seine Eingabekosten betragen rund 8 % der Flaggschiff-Eingabekosten, und seine Ausgabekosten liegen bei unter 10 % der Flaggschiff-Ausgabekosten. Genau diese Verhältnisse sind der Grund, warum OpenAI Mini/Nano als „etwa ein Drittel“ (Mini) bzw. „einen Bruchteil“ (Nano) der Kosten der größten Modelle für hochvolumige Aufgaben einordnet. Der Preis des Nano-Tokens stieg von 0,05 $ auf 0,20 $, und der Preis des Mini-Tokens stieg von 0,25 $ auf 0,75 $ (für Eingabe-Tokens).
Auf der OpenAI-Plattform
GPT-5.4 mini ist an drei Stellen verfügbar: in der OpenAI API, in Codex (OpenAIs Entwickler-IDE/App-Plattform) und in ChatGPT (verfügbar für Free- und Go-Nutzer über die Option „Thinking“ sowie als Rate-Limit-Fallback für kostenpflichtige Tarife). In der API unterstützt es Text- und Bildeingaben, Tool-Nutzung (Function Calling), Web-/Dateisuche, Computer Use und Skills — und es bietet ein sehr großes Kontextfenster (400k Tokens), um dokumentenlastige und Multi-Screenshot-Workflows zu bedienen. Die API-Preise betragen 0,75 $ pro 1 Mio. Eingabe-Tokens und 4,50 $ pro 1 Mio. Ausgabe-Tokens.
GPT-5.4 nano ist nur über die API verfügbar. Seine Listenpreise betragen 0,20 $ pro 1 Mio. Eingabe-Tokens und 1,25 $ pro 1 Mio. Ausgabe-Tokens — damit ist es der günstigste Einstieg in die GPT-5.4-Familie. Das Nano-Modell tauscht Leistungsfähigkeit bewusst gegen Kosten- und Geschwindigkeitsvorteile ein.
Auf Drittplattformen
CometAPI ist eine multimodale KI-API-Aggregationsplattform, die nun die GPT 5.4 Series API eingeführt hat, darunter GPT 5.4 Mini und GPT 5.4 Nano, mit 20 % Rabatt auf den OpenAI-Preis.
GPT 5.4 Nano:
| Comet-Preis (USD / Mio. Tokens) | Offizieller Preis (USD / Mio. Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet-Preis (USD / Mio. Tokens) | Offizieller Preis (USD / Mio. Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Hauptfunktionen und Neuerungen
Nachfolgend die wichtigsten Fähigkeiten — und warum Ingenieure und Produktteams darauf achten werden.
Encoding und Long-Context-Unterstützung
Kontextfenster: GPT-5.4 mini unterstützt ein Kontextfenster von 400k Tokens (OpenAI listet Mini ausdrücklich mit einem 400k-Kontext). Das ist groß genug für Codebasen mit mehreren Dateien, umfangreiche Dokumente oder Multi-Turn-Agent-Sitzungen, in denen Kontext wichtig ist. Nanos Kontext ist im Vergleich zum vollständigen GPT-5.4 kleiner, aber für schnelle kurze Aufgaben immer noch beträchtlich.
Reasoning
Reasoning-Stufen: OpenAI stellt konfigurierbares reasoning_effort (none → xhigh) bereit; Mini und Nano können mit unterschiedlichem Aufwand laufen, aber Mini verringert bei höherem Aufwand auf vielen Reasoning-Benchmarks den Abstand zum vollständigen GPT-5.4. Auf mehreren Intelligenz-Benchmarks (z. B. GPQA Diamond) erreicht Mini 88,0 % gegenüber 93,0 % für GPT-5.4, und Nano kommt auf 82,8 %, was auf beachtliches Reasoning für ein kleines Modell hinweist. Dies sind die Ergebnisse, die OpenAI in seinem Launch-Post veröffentlicht hat.
Multimodales Verständnis (Vision und UI)
Visuelle Wahrnehmung und UI-Aufgaben: GPT-5.4 mini zeigt eine sehr starke multimodale Leistung bei UI-Aufgaben (Screenshots, dichte Dokumentbilder). Auf OSWorld-Verified (einem Computer-Use-Benchmark) erreicht Mini 72,1 %, also sehr nahe an GPT-5.4 mit 75,0 % und deutlich über früheren Minis — deshalb wird Mini für screenshotgetriebene Automatisierungen und reaktionsschnelle multimodale Assistenten positioniert. Nano schneidet bei visuellen Benchmarks schwächer ab, ist aber für einfachere Bildaufgaben weiterhin nützlich.
Tool-Aufrufe und Computer Use
Native Tool-/Klick-Fähigkeiten: GPT-5.4 führt native Computer-Use-Tools ein bzw. erweitert sie; Mini übernimmt die Fähigkeit, Tools aufzurufen, Function Calls auszuführen, Screenshots zu interpretieren und Subagenten zu orchestrieren. Tool-Call-Benchmarks (Toolathlon, MCP Atlas) zeigen, dass Mini und Nano respektable Werte erzielen (Toolathlon: Mini 42,9 %, Nano 35,5 %) — das quantifiziert ihre Fähigkeit, externe Tools aufzurufen und zu koordinieren. Diese Kennzahlen stammen aus OpenAIs Ankündigung.
Halluzinationen / Faktentreue / Fehlerraten
OpenAI berichtet, GPT-5.4 sei das „bisher faktentreueste Modell“ und zeige weniger Halluzinationen als GPT-5.2; Mini und Nano weisen eine geringere absolute Faktentreue auf als das vollständige Modell (z. B. HLE mit Tools: GPT-5.4 52,1 %, Mini 41,5 %, Nano 37,7 %), was auf einen erhöhten Verifizierungsbedarf hindeutet, wenn kleinere Modelle bei faktenkritischen Aufgaben eingesetzt werden. Verwenden Sie toolbasierte Verifikation (Tool Calls, Citation Recall), wenn Korrektheit entscheidend ist.
Geschwindigkeit
OpenAI berichtet, dass GPT-5.4 mini bei typischen produktionsnahen Latenzschätzungen mehr als 2× schneller läuft als das frühere GPT-5 mini (diese basieren auf simuliertem Produktionsverhalten, das Tool-Call-Dauern und gesampelte Tokens einschließt). Diese Beschleunigung ist eine zentrale Aussage zur neuen Familie und der Grund, warum Mini als reaktionsschneller Subagent in interaktiven Apps wie Coding-Assistenten eingesetzt werden kann.
Wie schneiden Mini und Nano ab — kommen sie dem vollständigen GPT-5.4 „nahe“?
OpenAI hat eine umfassende Reihe von Benchmark-Vergleichen über Coding, Tool-Nutzung, multimodale Computer-Use-Aufgaben, Intelligenztests und Long-Context-Evaluierungen veröffentlicht. Die wichtigsten Zahlen (xhigh reasoning effort, wo anwendbar) umfassen:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (alt) | Hinweise |
|---|---|---|---|---|---|
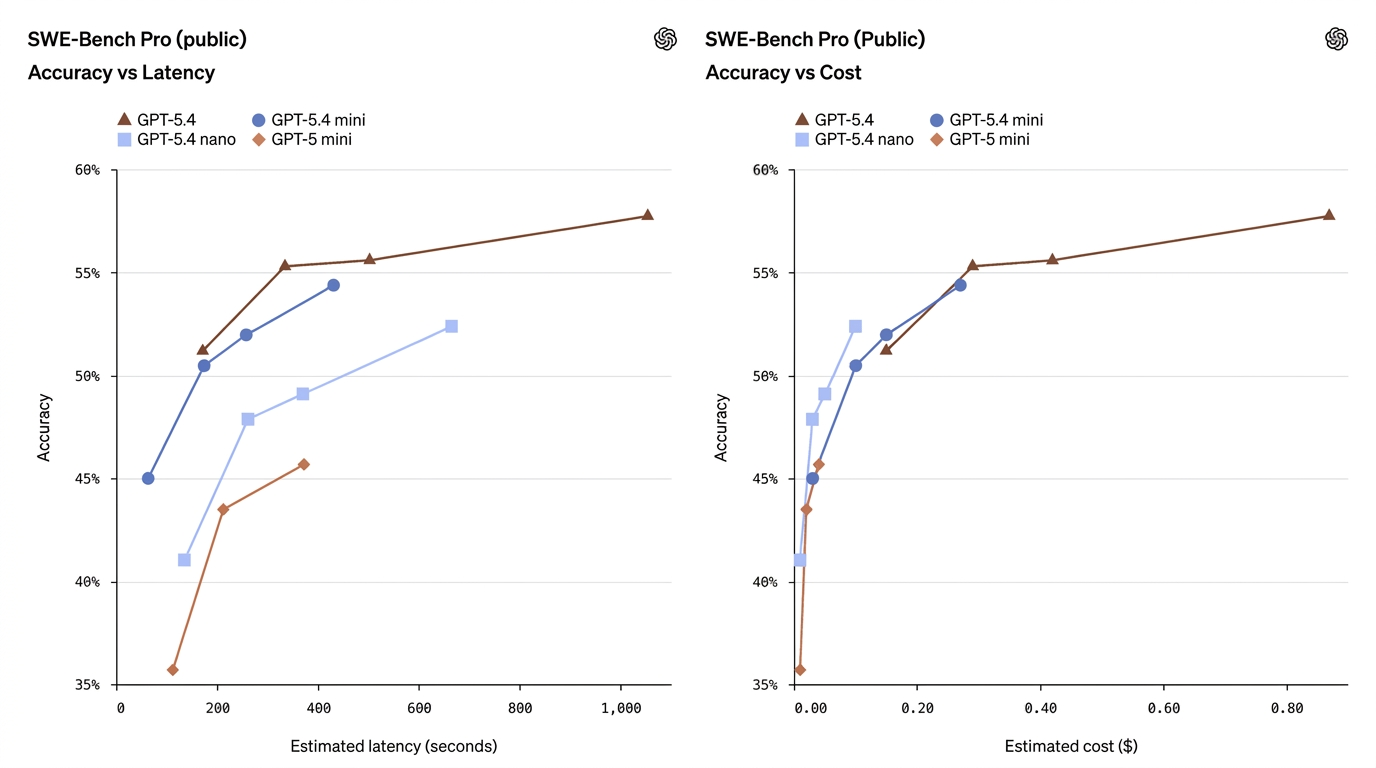
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini nähert sich der Coding-Leistung des Vollmodells |
| Terminal-Bench 2.0 (interaktives Coding) | 75.1% | 60.0% | 46.3% | — | Starke Echtzeit-Coding-Fähigkeit für Mini |
| Toolathlon (Tool-Nutzung) | 54.6% | 42.9% | 35.5% | — | Misst Orchestrierung und Tool-Calling |
| GPQA Diamond (fortgeschrittenes QA) | 93.0% | 88.0% | 82.8% | — | Intelligenz- und Reasoning-Benchmark |
| OSWorld-Verified (GUI-Aufgaben) | 75.0% | 72.1% | 39.0% | 42.0% | UI-/Computer-Use-Fähigkeit |
Diese Zahlen zeigen, dass Mini die Lücke häufig deutlich verkleinert — insbesondere bei Coding- und Computer-Use-Aufgaben — während Nano einen nützlichen Mittelweg zwischen Leistungsfähigkeit und Kosten einnimmt.
Was bedeuten diese Zahlen auf gut Deutsch?
- GPT-5.4 Mini ≈ „nahezu Flaggschiff“ bei vielen Produktionsaufgaben. Auf SWE-Bench Pro (einer Coding-Pass-Rate-Metrik) erreicht Mini 54,4 % gegenüber 57,7 % des Flaggschiffs — eine kleine relative Lücke für viele reale Coding-Aufgaben, insbesondere wenn Latenz wichtig ist. Auf OSWorld (Computer Use) erzielt Mini 72,1 % gegenüber 75,0 % des Flaggschiffs — ebenfalls sehr nah bei UI-/Screenshot-Aufgaben.
- GPT-5.4 Nano tauscht mehr Leistungsfähigkeit gegen Geschwindigkeit/Kosten. Nanos Coding-Score (52,4 % auf SWE-Bench Pro) ist im Vergleich zu älteren Minis respektabel, aber sein OSWorld-Score fällt auf 39,0 %, was zeigt, dass Nano für Aufgaben mit komplexem mehrstufigem UI-Verständnis oder agentischen Tool-Sequenzen weniger geeignet ist. Nano glänzt bei Single-Turn-Klassifizierung, Extraktion und kleinen Hilfsaufgaben.
- Tool-Nutzung verbessert sich, bleibt aber empfindlich. Toolathlon und andere Tool-Use-Metriken steigen beim Wechsel von GPT-5 mini auf GPT-5.4 mini/nano deutlich an, was zeigt, dass OpenAIs Engineering die Zuverlässigkeit von Tool-Aufrufen in kleineren Modellen verbessert hat — aber das vollständige Modell bleibt bei komplexer Tool-Orchestrierung führend.
Wie sie in der Produktion funktionieren
Kompression, Distillation und technische Optimierungen
Kompakte Modelle wie Mini/Nano nutzen typischerweise eine Kombination aus Model Distillation, Quantisierung und architektonischem Pruning, um hochwertige Fähigkeiten (Coding-Heuristiken, visuelle Wahrnehmungen) zu erhalten und gleichzeitig den Inferenzaufwand zu reduzieren. OpenAIs Formulierung deutet auf gezieltes Engineering hin, um bestimmte Fähigkeiten (Coding, multimodales UI-Verständnis) in kleineren Modellgrößen zu bewahren.
Empfohlene Muster
- Orchestrator- + Subagent-Muster: Verwenden Sie GPT-5.4 (groß) als Planer/Judge und delegieren Sie Arbeit an GPT-5.4 mini / nano-Subagenten zur schnellen Ausführung (Suche, Parsing, Bearbeitung). Das senkt die Gesamtkosten und reduziert die Latenz für den Nutzer. OpenAI empfiehlt dieses Designmuster ausdrücklich.
- Fallback- und Rate-Limit-Handling: Stellen Sie Mini in ChatGPT oder Codex als Rate-Limit-Fallback bereit, damit zeitkritische Anfragen weiterhin eine leistungsfähige Antwort erhalten, wenn das vollständige Modell nicht verfügbar ist.
- Mehrstufige Architektur zur Kostenkontrolle: Bulk-Pipelines (Indexierung, Extraktion) → GPT-5.4 nano; interaktive UI-Komponenten → GPT-5.4 mini; finale redaktionelle Bewertung / komplexe Chains → vollständiges GPT-5.4. Dieser mehrstufige Ansatz schafft ein Gleichgewicht zwischen Kosten und Leistungsfähigkeit.
Latenz und Parallelisierung
Mini und Nano sind für parallelisierte Subagenten optimiert, bei denen viele kleine Worker gleichzeitig laufen — z. B. beim parallelen Scannen von Tausenden PDFs. OpenAIs Konzept der „tool yields“ misst, wie parallele Tool-Aufrufe die Wall-Clock-Latenz verringern; Mini/Nano wurden so entwickelt, dass diese Muster kosteneffizient werden.
Wie würde ich Mini und Nano in der Praxis einsetzen?
Sollte ich meine Flaggschiff-Aufrufe überall durch Mini/Nano ersetzen?
Nicht automatisch. Das richtige Muster, das OpenAI ausdrücklich empfiehlt, ist Delegation: Verwenden Sie ein größeres Modell für Planung, komplexe Beurteilung oder finale Verifikation, und delegieren Sie viele unterstützende, kürzere Teilaufgaben an Mini- oder Nano-Subagenten. Dieses Muster reduziert Kosten und Latenz, während die Guardrails des größeren Modells dort erhalten bleiben, wo sie am wichtigsten sind. Anwendungsfälle:
- Interaktive Coding-Assistenten: Das Flaggschiff plant und prüft; Mini übernimmt schnelle Codesuche, Bearbeitungen und kurze Unit-Tests.
- Screenshotgetriebene „Computer Use“-Agenten: Mini kann dichte Oberflächen schnell analysieren; das Flaggschiff löst mehrdeutige mehrstufige Planung.
- Hochvolumige Extraktions- und Klassifizierungs-Pipelines: Nano verarbeitet riesige Batch-Eingaben (Formulare, Logs) und liefert strukturierte Ergebnisse; das Flaggschiff übernimmt Ausnahmen und komplexe Randfälle.
Können Mini oder Nano für multimodale oder Bildaufgaben verwendet werden?
Ja — Mini unterstützt Bildeingaben und schneidet bei multimodalen/visiongetriebenen Benchmarks (MMMUPro/OmniDocBench) gut ab und nähert sich in einigen Tests dem Flaggschiff an. Nanos multimodale Stärke ist begrenzter: Obwohl es sich gegenüber früheren Nanos verbessert, ist es nicht die beste Wahl für tiefes multimodales Reasoning oder agentische bildbasierte Aufgaben.
Das Rennen um kleine Modellfähigkeiten hat sich verschärft
Vor drei Monaten galten kleine Modelle als „gut genug“. Jetzt nähert sich GPT-5.4 mini bei Programmier-Benchmarks den Flaggschiff-Modellen an und erreicht beinahe deren Rechenleistung.
Der Trend dahinter ist klar: Die Fähigkeiten von Flaggschiff-Modellen werden rasch auf kleinere Modelle übertragen. OpenAI, Google und Anthropic tun im Wesentlichen dasselbe: Sie destillieren die Kernfähigkeiten großer Modelle in kleinere, schnellere und günstigere Versionen.
Fazit
Die Einführung dieser beiden Modelle signalisiert eine Verschiebung in KI-Anwendungen: weg vom Fokus auf Skalierung hin zu praktischer Effizienz. Durch schnelle Reaktionsfähigkeiten bieten sie eine verlässlichere Grundlage für Echtzeit-KI-Interaktionen und die Aufteilung komplexer Aufgabenabläufe.
Für Entwickler bedeutet das, dass die Kostenstruktur von Agentensystemen neu definiert wird. Wenn die Kosten auf dieses Niveau sinken, werden viele Agentenszenarien, die zuvor „theoretisch machbar, aber wirtschaftlich nicht tragfähig“ waren, realisierbar.
Entwickler können jetzt über GPT 5.4 Mini und GPT-5.4 Nano über CometAPI zugreifen (CometAPI ist eine zentrale Aggregationsplattform für große Modell-APIs wie GPT APIs, Nano Banana APIs usw.). Stellen Sie vor dem Zugriff bitte sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben. CometAPI bietet einen Preis, der deutlich unter dem offiziellen Preis liegt, um Ihre Integration zu erleichtern.
Bereit loszulegen?