

xAI wurde stillschweigend veröffentlicht Grok 4.1 (17.–18. November 2025) – ein gezieltes Upgrade auf Grok 4 mit Schwerpunkt auf emotionale Intelligenz, kreativer Ausdruck und reduzierte Halluzinationen Dabei behält es die messerscharfe Logik früherer Grok-Versionen bei. Es ist in zwei Modi verfügbar (Denkend/Nicht-Denken), wurde Anfang November stillschweigend eingeführt, zeigt die Top-Platzierungen in der LMArena an und ist über grok.com, die Grok-Apps und die API zugänglich.
Was ist Grok 4.1?
Grok 4.1 ist der inkrementelle, produktionsorientierte Nachfolger von Grok 4: ein Familienmitglied, das auf derselben Grundlage des groß angelegten Reinforcement Learnings aufbaut, jedoch durch umfangreiche Nachbearbeitungsoptimierungen hinsichtlich Stil, Persönlichkeit, Übereinstimmung und Zuverlässigkeit im realen Einsatz feinabgestimmt und neu trainiert wurde. Es positioniert sich als pragmatischer, praxisnaher Fortschritt: intelligenter in Blindtests mit menschlichen Präferenz, emotional intelligenter, besser im kreativen Schreiben und messbar weniger anfällig für die Art von selbstsicheren, aber falschen „Halluzinationen“, die frühere leistungsstarke LLMs geplagt haben.
Grok 4.1 erzielt qualitative Veränderungen in den folgenden vier Dimensionen:
- Kreativität: Zeigt einen ausgeprägteren Sprachstil und mehr Fantasie beim Schreiben, Geschichtenerzählen und im sozialen Kontext;
- Emotionale Intelligenz: Erkennt Tonfall- und Gefühlsveränderungen, reagiert mit einer menschenähnlicheren emotionalen Logik und erzeugt tröstliche und verständnisvolle Reaktionen;
- Persönlichkeitskohärenz: Behält in längeren Gesprächen einen einheitlichen Tonfall und eine einheitliche Persönlichkeit bei und zeigt nicht mehr das inkonsistente Verhalten früherer Modelle;
- Kollaborativ: Sorgt für Kohärenz und Zielbewusstsein in mehrstufigen Dialogen oder bei der Zusammenarbeit an Aufgaben.
xAI fasst seine Eigenschaften in einem Satz zusammen: „Es ist aufmerksamer, empathischer und ähnelt eher einer kohärenten Person.“
Wie funktioniert Grok 4.1 im Detail?
Grok 4.1 lässt sich am besten als das gleiche vortrainierte Backbone verstehen, das in der gesamten Grok 4-Familie verwendet wird, plus eine mehrschichtige Post-Training-Pipeline, die sich auf Folgendes konzentriert Belohnungsmodellierung, Stilanpassung und agentische Evaluatoren.
Welche Schulungs- und Ausrichtungsphasen gibt es?
Grok 4.1 arbeitet mit einer mehrstufigen Pipeline, wie sie für moderne Frontier-LLMs typisch ist, wurde jedoch für Version 4.1 mit zwei wichtigen Änderungen angepasst:
- Vor dem Training + während des Trainings: Vortraining mit einem großen Korpus an Webdaten + gezieltes Zwischentraining zur Steigerung des Domänenwissens und der multimodalen Fähigkeiten.
- Überwachtes Feintuning (SFT): Menschliche Demonstrationen erwünschter Verhaltensweisen (Reaktionen, Ablehnungsstrategien).
- Belohnungsmodellierung (neue Anwendung): xAI trainierte Belohnungsmodelle nicht nur anhand menschlicher Präferenzbezeichnungen, sondern verwendete auch Frontier-Agenten-Reasoning-Modelle als Belohnungsbewerter – wodurch leistungsstarke, modellbasierte Evaluatoren die Ergebnisse von Kandidaten in großem Umfang bewerten können. Dies ermöglichte die Optimierung nicht verifizierbarer Attribute wie Stil, Persönlichkeitskohäsion, Empathie und Hilfsbereitschaft ohne dass dafür ein unvorstellbar großes Budget für die manuelle Kennzeichnung benötigt wird.
- Richtlinienoptimierung (RLHF / RL aus Modellbelohnungen): Standard-Richtlinienoptimierung unter Verwendung der gelernten Belohnungssignale zur Erzeugung der eingesetzten Richtlinie (das Modell, mit dem die Konsumenten interagieren).
Was ist neu am Ansatz der Belohnungsmodellierung?
Im traditionellen RLHF werden menschliche Präferenzbezeichnungen (A/B) erfasst, ein Belohnungsmodell zur Vorhersage dieser Bezeichnungen trainiert und anschließend das Basismodell mithilfe von Reinforcement Learning (RL) (oder Rejection Sampling) anhand der gelernten Belohnung optimiert. Zwei praktische Innovationen, die xAI hervorhebt, sind:
- Agentische Belohnungsmodelle: Anstelle rein menschlicher Beurteilungen nutzte xAI leistungsfähige, „agentische“ Denkmodelle als Bewertungsinstrumente, um subtilere Eigenschaften (Tonfall, emotionale Nuancen, Kreativität) zu bewerten. Die Bewertungsinstrumente können Tausende von Paarvergleichen schnell durchführen, wodurch Entwickler schneller iterieren können. Dies ist der Mechanismus für deutliche Verbesserungen in Stil und emotionaler Intelligenz.
- Ausrichtung nach dem Training für nicht verifizierbare Signale: Für Attribute, die sich nicht mit einer deterministischen Metrik messen lassen (z. B. „Wärme“ oder „kohärente Persönlichkeit“), wurden spezielle Belohnungsziele und Skalierungsprogramme eingeführt, damit das Modell lernt, Stil Ergebnisse zu erzielen, ohne die inhaltliche Richtigkeit zu beeinträchtigen.
Wie funktioniert „Denken“ im Gegensatz zu „Nicht-Denken“ technisch gesehen?
- Grok 4.1 Denken (Codename)
quasarflux) — Legt die einzelnen Denkschritte (Denkbausteine) offen, bevor die endgültige Antwort ausgegeben wird; optimiert für komplexe Aufgaben und höhere Elo-Werte in LMArena. Die zusätzlichen Bausteine verlängern zwar die Berechnungszeit, erleichtern aber mehrstufige Denkprozesse, das Debuggen und die Erklärbarkeit. - Grok 4.1 Nicht-Denken (Codename)
tensor) Umgeht explizite Zwischentoken und liefert stattdessen eine einzige, sofortige Endantwort. Dies reduziert Latenz und Tokenkosten, während gleichzeitig die gleichen optimierten Policy-Gewichtungen beibehalten werden. Der Modus ohne Denkprozess wurde für extrem niedrige Latenz und gleichzeitig hohe Leistungsfähigkeit optimiert.
Ausrichtungsoptimierung von Stimmung und Stil
Über einfache „Wahrhaftigkeitssignale“ hinaus optimiert Grok 4.1 gezielt die Abstimmung von Stimmung, Tonfall und zwischenmenschlichem Stil. Das bedeutet, dass der Trainingsablauf Belohnungs- und Bestrafungskomponenten enthält, die einen unpassenden Tonfall (z. B. unnötige Kürze, wo Empathie angebracht wäre) explizit bestrafen und Reaktionen belohnen, die einem gewünschten Stil- oder Stimmungsprofil entsprechen. In Grok 4.1 wurde das Optimierungsziel der „Persönlichkeitsabstimmung“ erstmals eingeführt.
Ziel ist es, dem Modell zu helfen, ein konsistentes und stabiles Identitätsgefühl zu bewahren. Im Vergleich zu Grok 4 ergänzt Version 4.1 die Trainingsziele um Folgendes:
- Positive Belohnungen für die Dimension des emotionalen Ausdrucks (Belohnung für emotionale Ausrichtung);
- Ein Maß für die Kohärenz der Persönlichkeit.
Wie wurde Grok 4.1 evaluiert – und wie schnitt es ab?
Was zeigten Blindtests zur Präferenzentwicklung von Probanden?
Bei einer stillen Testphase wurde Grok 4.1 im Live-Verkehr in 64.78 % der Fälle gegenüber dem vorherigen Produktionsmodell bevorzugt – ein starkes Signal für die menschliche Präferenz, das auf bessere Gesprächsergebnisse in freier Wildbahn hindeutet.
Gehört Grok 4.1 zu den Top-Spielern?
xAI berichtet, dass Grok 4.1 Denken Der Modus befindet sich bei Platz 1 in der Text Arena von LMArenamit einer gemeldeten Elo-Zahl von 1483und sein Modus ohne logisches Denken (schneller Modus) belegt mit 1465 Elo den zweiten Platz – starke Platzierungen in der öffentlichen Rangliste sowohl für Genauigkeit als auch für Präsentation (die Stilkontrolle spielt eine Rolle).
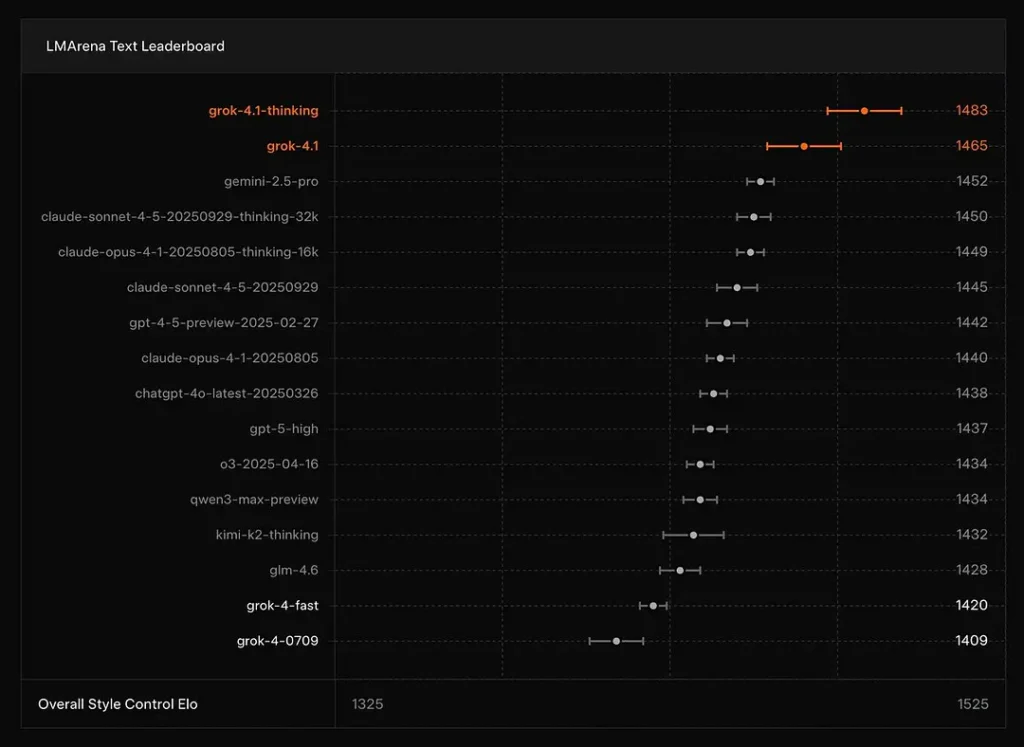
Fazit: Grok 4.1 übertrifft die gängigen Modelle der GPT-4.5- und Claude-Serien in Bezug auf Textverständnis, Generierung und Gesamtqualität und steht nur hinter der GPT-5 Advanced Preview-Version.
Emotionale Intelligenz
xAI führte EQ-Bench3 durch, einen spezialisierten Test zur emotionalen Intelligenz mit 45 anspruchsvollen Rollenspielszenarien, und berichtet, dass Grok 4.1 deutliche Verbesserungen in Empathie, Zeitmanagement und zwischenmenschlicher Einsicht aufweist. Grok 4.1 erzielte die höchsten Werte beim Verständnis von Kontexten der Traurigkeit, Empathie und des Trostes.

Kreatives Schreiben – ist es tatsächlich fantasievoller?
Grok 4.1 wurde evaluiert am Kreatives Schreiben v3 (32 Aufgaben in 3 Durchgängen mit Bewertungsraster und Elo-Wertung). Laut xAI haben sich Schreibstil, Sprachkonsistenz und Erzählkreativität von Version 4.1 deutlich verbessert, wodurch sie in den aktuellen Bestenlisten für kreative Aufgaben weit oben mitspielt (Beispielaufgaben sind in der Veröffentlichung enthalten). Unabhängige Gutachten bestätigen diese Ergebnisse: Die Gutachter bemerkten eine deutlich individuellere Stimme und eine bessere Kohärenz längerer Texte. Hinsichtlich der Schreibqualität steht Grok 4.1 direkt hinter den Modellen der GPT-5-Serie und übertrifft die gesamten Produktlinien von Claude, Gemini und Kimi.

Reduzierte Halluzinationen / Ehrlichkeit
xAI behauptet eine deutliche Reduzierung der Halluzinationsrate: Sie berichteten (in der Ankündigung und in Social-Media-Posts), dass Grok 4.1 etwa3-mal geringeres Risiko, Halluzinationen zu haben Im Vergleich zu früheren Grok-Modellen, die auf Analysen des Produktionsverkehrs und FActScore-ähnlichen Bewertungen (z. B. Fragenkataloge zu Biografien) basieren, ist ein niedrigerer Wert besser. Insbesondere im „Nicht-Argumentation-Modus“, in dem externe Suchwerkzeuge verfügbar sind, ist die Konsistenz der Fakten stabiler.

Warum wird Grok 4.1 anderen Modellen „übertroffen“ – ist das eine Übertreibung?
„Crushes“ klingt zwar nach Marketing, aber hinter dieser Aussage stecken objektive Behauptungen:
- Bestenlisten: Grok 4.1 belegt Spitzenplätze in den öffentlichen LMArena-Ranglisten für Textgenerierung (1483 Elo im Denkmodus) und erzielt laut xAI-Veröffentlichung starke Ergebnisse in den Bereichen Kreativität und emotionale Intelligenz. Dies sind vergleichbare, in der Community übliche Wettbewerbskennzahlen.
- Präferenz für realen Datenverkehr gewinnt: xAI verzeichnet in Blindvergleichen mit menschlichen Testpersonen deutliche Verbesserungen (ca. 65 % Präferenz gegenüber dem vorherigen Produktionsmodell) nach einer unauffälligen Einführung im Live-Verkehr. Dies spiegelt tatsächliche Verbesserungen für die Nutzer wider und nicht nur theoretische Benchmarks.
- Praktische neue Fähigkeit: Die Kombination aus Modellbewertung, Reinforcement Learning auf nicht verifizierbaren Signalen und strengeren Eingangsfiltern ist ein pragmatischer technischer Schritt, der die Benutzererfahrung bei dialogischen, empathischen und kreativen Aufgaben, bei denen Wettbewerber in der Vergangenheit schlechter abgeschnitten haben, direkt verbessert.
„Crushes“ ist zwar eine blumige Umschreibung für „führt in mehreren öffentlichen und internen Bewertungen“, doch die zugrunde liegenden, von xAI veröffentlichten öffentlichen Kennzahlen untermauern diese Schlussfolgerung.
So greifen Sie auf Grok 4.1 zu
Verbraucher-/App-Zugriff
xAI hat Grok 4.1 im „Auto“-Modus regelmäßig kostenlos oder im Rahmen einer Werbeaktion zugänglich gemacht, aber Premium-Stufen (SuperGrok, SuperGrok Heavy) und API-Zugriff mit höheren Kontingenten existieren und bleiben kostenpflichtige Angebote.
Grok 4.1 steht allen Benutzern zur Verfügung. on grok.com, X (ehemals Twitter), und die iOS- und Android-Grok-Apps, die sofort im Automatikmodus verfügbar sind und gleichzeitig im Modellauswahlmenü explizit als „Grok 4.1“ ausgewählt werden können.
API-Zugriff und Entwicklerpläne
Grok 4.1-Endpunkte sind über die xAI-API verfügbar. Zum Zeitpunkt der Veröffentlichung dieses Artikels war die offizielle GPT 4.1-API noch nicht verfügbar.
CometAPI verspricht, die neuesten Modelldynamiken im Auge zu behalten, einschließlich Grok 4.1 API, das zeitgleich mit der offiziellen Veröffentlichung erscheint. Seien Sie gespannt und behalten Sie CometAPI weiterhin im Auge. In der Zwischenzeit können Sie sich die anderen Modelle von Grok ansehen, wie zum Beispiel . Grok-Code-schnell-1 kombiniert mit einem nachhaltigen Materialprofil. Grok 4Erkunden Sie die Funktionen im Playground und konsultieren Sie die API-Dokumentation für detaillierte Anweisungen zum Aufrufen. Stellen Sie vor dem Zugriff sicher, dass Sie sich bei CometAPI angemeldet und den API-Schlüssel erhalten haben.
Praktische Tipps für den Einsatz von Grok 4.1 in der Produktion
Wie man das Halluzinationsrisiko verringern kann
- Live-Suche aktivieren oder eine verifizierte Toolkette für Informationsanfragen.
- Verifizierungsschritte bereitstellenBitten Sie das Modell, Quellen und Belege für Faktenbehauptungen anzugeben; verwenden Sie die
responseMetadaten zur Überprüfung von Zitaten (sofern verfügbar). - Führe deterministische Prüfungen durch (Faktenprüfung von LLMs, Validierung strukturierter Daten) als Nachbearbeitungsschritt für wichtige Ergebnisse.
Wie man Ton und Stil kontrolliert
- Verwenden Sie explizite Systemhinweise, um Ihre Stimme zu korrigieren („Sie sind formell und empathisch.“).
- Verwenden Sie überwachte Eingabeaufforderungen und kleine lokale Vorlagen, um eine einheitliche Sprachausgabe in allen Anwendungen zu gewährleisten.
- Nutzen Sie, sofern verfügbar, die Stilsteuerungsoptionen und die belohnungsbasierten Lenkknöpfe von xAI.
Endgültiges Urteil: Bedeutet Grok 4.1 eine grundlegende Veränderung?
Grok 4.1 ist kein Frontalunterricht. keine brandneue Architektur; vielmehr handelt es sich um eine anspruchsvolle und durchdachte Nach dem Training / Ausrichtung Veröffentlichung, die sich darauf konzentriert, was Menschen im Chat tatsächlich wichtig ist: Persönlichkeit, emotionale Intelligenz, Kreativität und weniger sachliche FehlerMessbare Verbesserungen in Bestenlisten, umfangreiche Echtzeit-Nutzerpräferenzen und optimierte Sicherheitsfunktionen. Für Anwendungen, die auf hochwertige Konversation, kreative Zusammenarbeit oder sprachsensitive Unterstützung angewiesen sind, stellt Grok 4.1 einen bedeutenden Fortschritt dar und war zum Zeitpunkt der Veröffentlichung in mehreren Community-Benchmarks führend.
CometAPI ist eine kommerzielle API-Aggregationsplattform, die Entwicklern einen einheitlichen REST-Zugriff im OpenAI-Stil auf Hunderte von KI-Modellen verschiedener Anbieter ermöglicht – darunter Text-LLMs, Bild-/Videogeneratoren, Einbettungen und mehr – über eine einzige, konsistente Schnittstelle. Anstatt separate SDKs oder maßgeschneiderte Endpunkte für OpenAI, Anthropic, Google, Meta oder kleinere spezialisierte Modellanbieter zu verwenden, können Sie mit CometAPI verschiedene Modelle aufrufen, indem Sie einfach Modellstrings und einige wenige Parameter ändern.
Bereit zum Ausprobieren?→ Melden Sie sich noch heute für CometAPI an !
Wenn Sie weitere Tipps, Anleitungen und Neuigkeiten zu KI erfahren möchten, folgen Sie uns auf VK, X kombiniert mit einem nachhaltigen Materialprofil. Discord!