
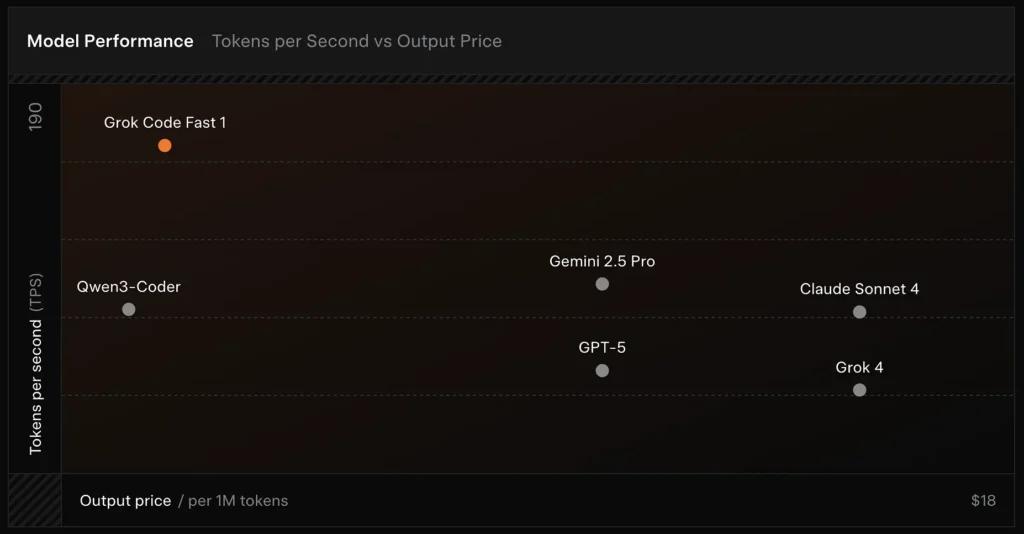
grok-code-fast-1 ist xAI’s geschwindigkeitsorientiertes, kosteneffizientes agentisches Coding‑Modell, entwickelt für IDE‑Integrationen und automatisierte Coding‑Agenten. Es legt den Schwerpunkt auf niedrige Latenz, agentische Verhaltensweisen (Tool‑Aufrufe, schrittweise Reasoning‑Spuren) und ein kompaktes Kostenprofil für alltägliche Entwickler‑Workflows.
Zentrale Funktionen (auf einen Blick)
- Hoher Durchsatz / niedrige Latenz: fokussiert auf sehr schnelle Tokenausgabe und zügige Vervollständigungen für den IDE‑Einsatz.
- Agentisches Function‑Calling & Tooling: unterstützt Funktionsaufrufe und die Orchestrierung externer Tools (Tests ausführen, Linter, Dateiabruf), um mehrschrittige Coding‑Agenten zu ermöglichen.
- Großes Kontextfenster: ausgelegt für große Codebasen und Multi‑File‑Kontexte (einige Anbieter listen 256k‑Kontextfenster in Marketplace‑Adaptern).
- Sichtbares Reasoning / Traces: Antworten können schrittweise Reasoning‑Spuren enthalten, um Entscheidungen des Agenten nachvollziehbar und debuggbar zu machen.
Technische Details
Architektur & Training: xAI gibt an, dass grok-code-fast-1 von Grund auf mit einer neuen Architektur und einem Pretraining‑Korpus mit reichhaltigen Programmierinhalten aufgebaut wurde; das Modell erhielt anschließend eine Kuratierung nach dem Training auf hochwertigen, realen Pull‑Request‑/Code‑Datensätzen. Diese Engineering‑Pipeline zielt darauf ab, das Modell praktisch in agentischen Workflows (IDE + Tool‑Nutzung) einsetzbar zu machen.
Serving & Kontext: grok-code-fast-1 und typische Nutzungsmuster setzen Streaming‑Ausgaben, Funktionsaufrufe und eine reichhaltige Kontexteinspeisung (Datei‑Uploads/-Sammlungen) voraus. Mehrere Cloud‑Marktplätze und Plattformadapter listen es bereits mit großem Kontext‑Support (256k Kontexte in einigen Adaptern).
Usability‑Features: Sichtbare Reasoning‑Traces (das Modell zeigt seine Planung/Tool‑Nutzung), Prompt‑Engineering‑Hinweise und Beispiel‑Integrationen sowie frühe Launch‑Partner‑Integrationen (z. B. GitHub Copilot, Cursor).
Benchmark‑Performance (Worauf es punktet)
SWE‑Bench‑Verified: xAI berichtet von 70.8% auf ihrem internen Harness über das SWE‑Bench‑Verified‑Subset — ein Benchmark, der häufig für Vergleiche von Software‑Engineering‑Modellen verwendet wird. Eine aktuelle praktische Evaluation meldete eine durchschnittliche menschliche Bewertung ≈ 7.6 auf einer gemischten Coding‑Suite — konkurrenzfähig mit einigen hochpreisigen Modellen (z. B. Gemini 2.5 Pro), aber hinter größeren multimodalen/“best‑reasoner”‑Modellen wie Claude Opus 4 und xAI’s eigenem Grok 4 bei Aufgaben mit hoher Reasoning‑Schwierigkeit. Benchmarks zeigen zudem Streuung je nach Aufgabe: hervorragend bei üblichen Bugfixes und prägnanter Code‑Generierung, schwächer bei einigen Nischen‑ oder bibliotheksspezifischen Problemen (Tailwind‑CSS‑Beispiel).
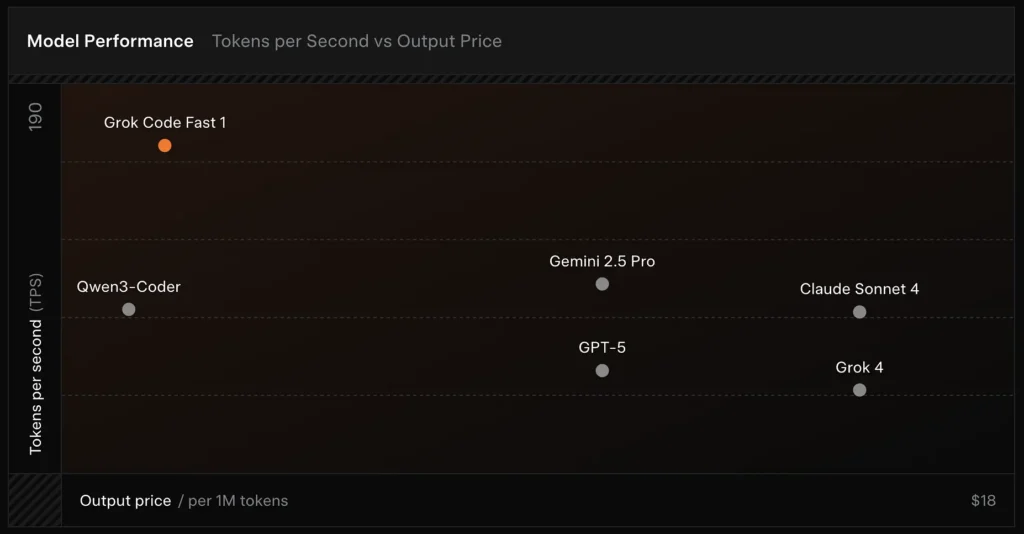
Vergleich:
- vs Grok 4: Grok-code-fast-1 tauscht etwas absolute Korrektheit und tiefes Reasoning gegen deutlich niedrigere Kosten und schnelleren Durchsatz; Grok 4 bleibt die leistungsfähigere Option.
- vs Claude Opus / GPT‑Klasse: Diese Modelle führen oft bei komplexen, kreativen oder schwierigen Reasoning‑Aufgaben; Grok-code-fast-1 ist stark bei hohem Volumen und Routine‑Developer‑Tasks, bei denen Latenz und Kosten entscheidend sind.
Einschränkungen & Risiken
Praktische Beobachtungen bisher:
- Domain‑Lücken: Leistungseinbrüche bei Nischenbibliotheken oder ungewöhnlich formulierten Problemen (Beispiele: Tailwind‑CSS‑Edge‑Cases).
- Reasoning‑Token‑Kosten‑Trade‑off: Da das Modell interne Reasoning‑Tokens ausgeben kann, kann stark agentisches/ausführliches Reasoning die Inferenz‑Ausgabelänge (und die Kosten) erhöhen.
- Genauigkeit / Randfälle: Obwohl stark bei Routineaufgaben, kann Grok-code-fast-1 halluzinieren oder fehlerhaften Code für neuartige Algorithmen oder adversarial formulierte Problemstellungen erzeugen; bei anspruchsvollen algorithmischen Benchmarks bleibt es hinter den besten Reasoning‑fokussierten Modellen zurück.
Typische Anwendungsfälle
- IDE‑Unterstützung & Rapid Prototyping: schnelle Vervollständigungen, inkrementelle Code‑Erstellung und interaktives Debugging.
- Automatisierte Agenten / Code‑Workflows: Agenten, die Tests orchestrieren, Befehle ausführen und Dateien bearbeiten (z. B. CI‑Helfer, Bot‑Reviewer).
- Alltägliche Engineering‑Aufgaben: Generieren von Codeskeletten, Refactorings, Bug‑Triage‑Vorschlägen und Multi‑File‑Projekt‑Gerüsten, bei denen geringe Latenz den Developer‑Flow spürbar verbessert.
So rufen Sie die grok-code-fast-1‑API über CometAPI auf
grok-code-fast-1 API‑Preise in CometAPI, 20% günstiger als der offizielle Preis:
- Input Tokens: $0.16/ M tokens
- Output Tokens: $2.0/ M tokens
Erforderliche Schritte
- Melden Sie sich bei cometapi.com an. Wenn Sie noch kein Nutzer sind, registrieren Sie sich bitte zuerst.
- Rufen Sie den Zugangs‑API‑Schlüssel der Schnittstelle ab. Klicken Sie im persönlichen Zentrum bei API‑Token auf „Add Token“, erhalten Sie den Token‑Schlüssel: sk‑xxxxx und übermitteln Sie ihn.
Vorgehensweise
- Wählen Sie den Endpunkt „
grok-code-fast-1“, um die API‑Anfrage zu senden, und setzen Sie den Request‑Body. Anfragemethode und Request‑Body entnehmen Sie der API‑Doku auf unserer Website. Unsere Website bietet auch Apifox‑Tests zu Ihrer Bequemlichkeit. - Ersetzen Sie <YOUR_API_KEY> durch Ihren tatsächlichen CometAPI‑Schlüssel aus Ihrem Account.
- Fügen Sie Ihre Frage oder Anforderung in das content‑Feld ein — darauf wird das Modell antworten.
- . Verarbeiten Sie die API‑Antwort, um die generierte Antwort zu erhalten.
CometAPI stellt eine vollständig kompatible REST‑API bereit — für nahtlose Migration. Kerndetails zur API‑Doku:
- Basis‑URL: https://api.cometapi.com/v1/chat/completions
- Modellnamen: “
grok-code-fast-1“ - Authentifizierung: Bearer‑Token via
Authorization: Bearer YOUR_CometAPI_API_KEYHeader - Content-Type:
application/json.
API‑Integration & Beispiele
Python‑Snippet für einen ChatCompletion‑Aufruf über CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Siehe auch Grok 4