

Luma AIs Uni-1 ist mehr als nur ein neues Text-zu-Bild-Modell. In Lumas eigener Darstellung ist es ein „multimodales Reasoning-Modell, das Pixel generieren kann“, aufgebaut auf „Unified Intelligence“, sodass es Intention versteht, auf Anweisungen reagiert und „mit dir denkt“. Der technische Bericht des Unternehmens besagt, dass das Modell einen Decoder-only autoregressiven Transformer verwendet, in dem Text und Bilder in einer einzigen ineinander verschachtelten Sequenz dargestellt sind, und dass Uni-1 vor und während der Bildsynthese strukturiertes internes Reasoning ausführen kann. Diese Kombination macht Uni-1 zu einer der interessantesten Bildmodell-Veröffentlichungen des Jahres 2026.
Was ist das UNI-1-Bildmodell?
Uni-1 ist Luma AIs neues Bildmodell für Aufgaben, die sowohl Verstehen als auch Generieren in einem System erfordern. Luma präsentiert es als ein multimodales Reasoning-Modell statt als klassische reine Diffusions-Bild-Engine. Das ist wichtig, weil das Modell mehr tun soll, als nur visuell ansprechende Ergebnisse zu liefern: Es ist darauf ausgelegt, Anweisungen zu interpretieren, Referenzrestriktionen beizubehalten und die Szenenlogik als Teil der Generierung durchzudenken. Der technische Bericht des Unternehmens beschreibt Uni-1 als sein erstes vereintes Verstehens-und-Generierungsmodell auf dem Weg zu multimodaler allgemeiner Intelligenz.
Warum Uni-1 anders ist
Die alte Pipeline hat eine Decke: Bildgenerierung ohne Verständnis kommt nur begrenzt weit. Uni-1 wird als Schritt in Richtung „unified intelligence“ präsentiert, bei der Sprache, Wahrnehmung, Vorstellungskraft, Planung und Ausführung innerhalb einer einzigen Architektur gehandhabt werden. Das ist mehr als nur Branding. Uni-1 kann sich von bloßer visueller Ähnlichkeit in Richtung beabsichtigter Komposition, Plausibilität und Szenenlogik bewegen.
Die größere Geschichte ist, dass Bildmodelle agentischer werden. Googles neuester Bild-Stack betont nun konversationale Bearbeitung, Suchverankerung, Multi-Image-Fusion und Charakterkonsistenz; OpenAIs GPT Image-Familie betont native Multimodalität und Befolgen von Anweisungen. Uni-1 schließt sich dieser Verschiebung an, legt aber stärker die Idee zugrunde, dass das Modell über das Bild „nachdenken“ sollte, bevor es es zeichnet. Das macht Uni-1 besonders interessant für Workflows, in denen Präzision und Reproduzierbarkeit ebenso wichtig sind wie visuelle Finesse.
Wie funktioniert Uni-1 tatsächlich?
🔬 Tokenisierungsprozess
- Text → Token-Sequenz
- Bild → tokenisierte Patches
- Kombiniert zu einer einzigen ineinander verschachtelten Sequenz
🔁 Generierungsprozess
- Eingabe-Prompt + Referenzen
- Modell führt internes Reasoning aus
- Plant die Komposition
- Generiert Tokens sequenziell
Mathematisch: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Interne Reasoning-Schicht
Uni-1:
- Zerlegt Anweisungen
- Löst Restriktionen auf
- Plant das Layout vor dem Rendern
👉 Das ist ein großer Sprung gegenüber Diffusionsmodellen.
Decoder-only autoregressive Generation
Das wichtigste technische Detail ist, dass Uni-1 autoregressiv statt diffusionsbasiert ist. Lumas technischer Bericht sagt, es handelt sich um einen Decoder-only autoregressiven Transformer und dass Text und Bilder in einer einzigen ineinander verschachtelten Sequenz kodiert sind. Einfach gesagt startet das Modell nicht nur aus Rauschen und „entrauscht“ schrittweise zu einem Bild. Stattdessen generiert es Token für Token, sodass das Modell den Prompt durchdenken, Restriktionen auflösen und die Komposition vor und während des Renderings planen kann.
🔬 Tokenisierungsprozess
- Text → Token-Sequenz
- Bild → tokenisierte Patches
- Kombiniert zu einer einzigen ineinander verschachtelten Sequenz
Diffusion vs. Autoregressiv
| Feature | Diffusionsmodelle | Uni-1 (Autoregressiv) |
|---|---|---|
| Generierung | Rauschen → Bild | Token-für-Token |
| Reasoning | Begrenzt | Stark |
| Bearbeitung | Schwach | Multi-Turn |
| Textrendering | Schwach | Stark |
| Kontrolle | Niedrig | Hoch |
Kernarchitektur
Uni-1 ist:
- Decoder-only autoregressiver Transformer
- Gemeinsamer Tokenraum für Text + Bilder
Diese Architektur ist wichtig, weil sie dem Modell die Möglichkeit gibt, Kohärenz zu bewahren, wenn der Prompt kompliziert ist. Luma sagt, Uni-1 könne Anweisungen zerlegen, widersprüchliche Restriktionen auflösen und das Bild planen, bevor das Rendering beginnt. Das ist besonders nützlich für Aufgaben wie strukturierte Szenenvervollständigung, Platzierung mehrerer Subjekte, Multi-Turn-Verfeinerung und Edits, die erfordern, dass das Ergebnis einem Referenzbild treu bleibt und zugleich neuen Anweisungen folgt.
Was das Modell besser zu leisten scheint
Das Erlernen der Bildgenerierung verbessert das Verständnis. Luma sagt, dass das Training zur Bildgenerierung das fein-granulare visuelle Verständnis deutlich verbessert, insbesondere in Bezug auf Regionen, Objekte und Layouts. Deshalb versteht Luma Uni-1 nicht als Einbahnstraßen-Generator, sondern als ein vereintes System, in dem Generierung und Verständnis sich gegenseitig verstärken. In der Inferenz bedeutet das, dass Uni-1 versucht, die Lücke zwischen „Sehen“ und „Machen“ zu schließen. Das ist ein großer Sprung gegenüber Diffusionsmodellen.
Generierungsprozess:
- Eingabe-Prompt + Referenzen
- Modell führt internes Reasoning aus
- Plant die Komposition
- Generiert Tokens sequenziell
Mathematisch: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Welche Features und Kernvorteile bietet Uni-1?
Starkes Befolgen von Anweisungen und hohe Steuerbarkeit
Der größte Pluspunkt von Uni-1 ist die Kontrolle. Das Modell ist für präzises Editieren, strukturierten Referenzeinsatz und reproduzierbare Workflows gebaut. Für Kreative bedeutet das weniger Prompt-Lotterie und mehr wiederholbare Ergebnisse.
Ein praktischer Vorteil von Uni-1 ist, dass es für kontrollierte Iteration ausgelegt ist. Seeds lassen Nutzer Ergebnisse reproduzieren, während Referenzrollen dem Modell helfen zu wissen, ob ein Bild die Charakteridentität, Stimmung, Palette oder Komposition leiten soll. Das macht Uni-1 leichter dirigierbar als ein rein prompt-getriebenes Modell, besonders für Teams, die Anzeigen, Storyboards, Produkt-Mockups oder Marken-Assets produzieren, bei denen Konsistenz zählt.
Referenzbasierte Generierung, die Identität bewahrt
Ein großer Vorteil ist der Umgang mit Referenzen. Luma sagt ausdrücklich, dass Uni-1 quellverankerte Steuerungen verwendet und Identität, Komposition und zentrale visuelle Restriktionen aus einer oder mehreren Referenzen bewahren kann. Das macht es attraktiv für kommerzielle Workflows wie Markencharaktere, Produkt-Mockups, Kampagnen-Assets und jedes Projekt, bei dem ein Subjekt über Varianten hinweg wiedererkennbar bleiben muss. Dies ist einer der deutlichsten Unterschiede von Uni-1 zu eher rein ästhetischen Bildsystemen.
Kulturelle Gewandtheit und Stilbreite
Luma betont zudem kulturinformierte Generierung. Der Abschnitt „Cultured“ verweist auf Memes, Manga, cineastische Looks, Casual-Fotos, Sport- und Tierbilder und zeigt, dass das Modell über visuelle Sprachen hinweg operieren soll statt in einem generischen Stil. Das ist wichtig, weil ein modernes Bildmodell nicht nur eine realistische Szene rendern muss; es muss auch die visuellen Konventionen der Internetkultur, Editorial-Designs, stilisierte Illustration und Social Content verstehen.
Multimodales Denken als Designentscheidung
Der eigentliche Differenzierer ist nicht nur, dass Uni-1 Bilder generiert, sondern dass Luma die Bildgenerierung als Reasoning-Aufgabe rahmt. Uni-1 kann strukturiertes internes Reasoning ausführen, und das Erlernen der Bildgenerierung verbessert das fein-granulare visuelle Verständnis über Regionen, Objekte und Layouts. Das deutet auf ein Modell hin, das die Szene versteht, bevor es sie rendert, statt den Prompt nur statistisch zu approximieren.
Leistungsbenchmarks
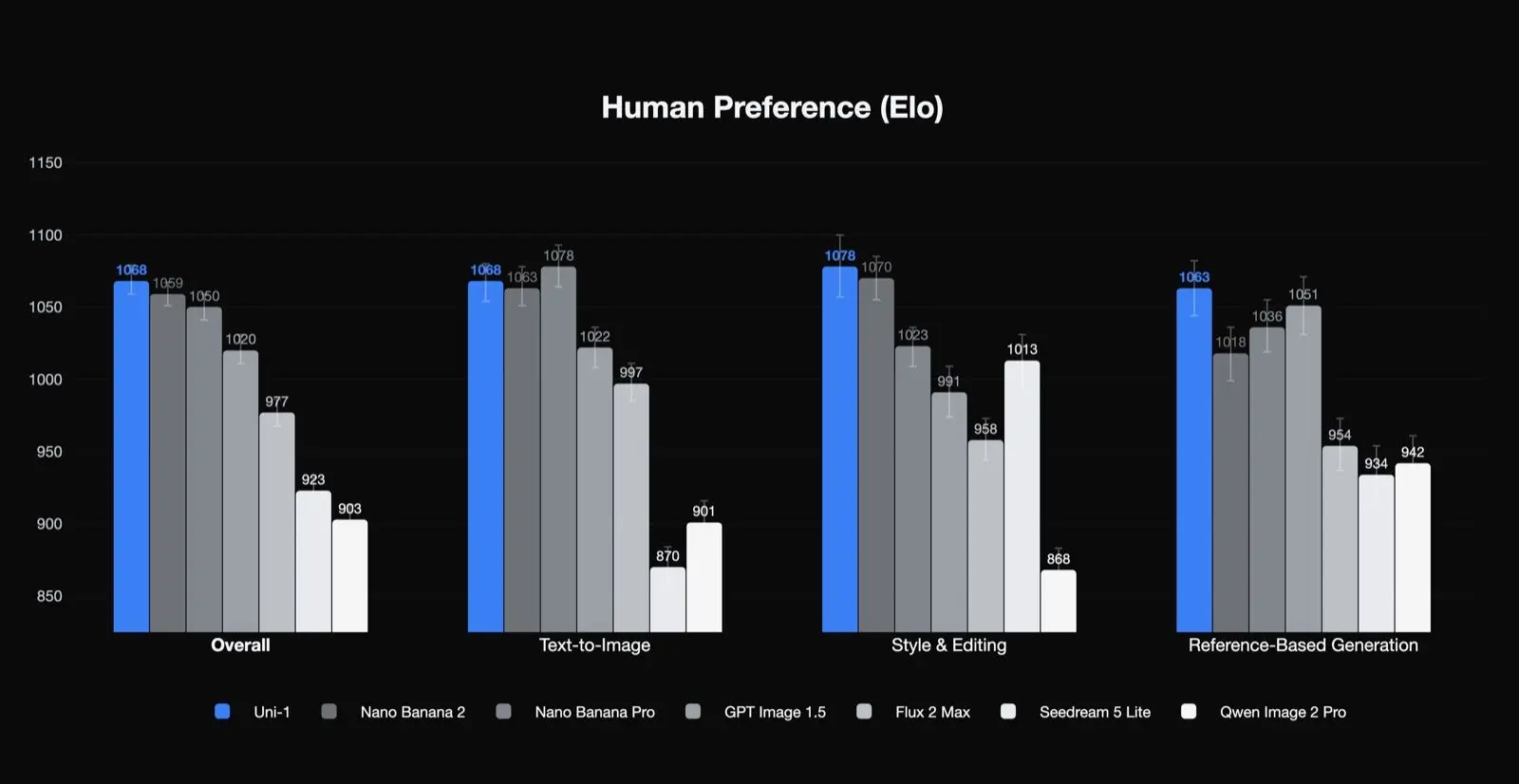
Lumas eigene Human-Preference-Ergebnisse
Uni-1 belegt den ersten Platz in der Human-Preference-Elo für Gesamtqualität, Stil und Bearbeitung sowie referenzbasierte Generierung und den zweiten Platz bei Text-zu-Bild. Das ist ein bedeutsames Ergebnis, weil es nahelegt, dass das Modell besonders stark in den Aufgaben ist, die für Produktionsteams wichtig sind: Bearbeitung, Konsistenz und geführte Transformation. Es legt auch nahe, dass die besten Anwendungsfälle nicht nur reines One-Shot-Text-zu-Bild sind.
RISEBench: reasoning-informierte visuelle Bearbeitung
Der aufmerksamkeitsstärkste Benchmark ist RISEBench, der reasoning-informierte visuelle Bearbeitung über zeitliche, kausale, räumliche und logische Aspekte hinweg bewertet. Drittberichte zu Lumas Launch sagen, Uni-1 erreiche insgesamt 0,51 auf RISEBench, vor Googles Nano Banana 2 mit 0,50, Nano Banana Pro mit 0,49 und OpenAIs GPT Image 1.5 mit 0,46. Beim räumlichen Reasoning wird Uni-1 mit 0,58 gegenüber Nano Banana 2 mit 0,47 berichtet. Beim logischen Reasoning wird Uni-1 mit 0,32 berichtet, mehr als doppelt so hoch wie GPT Image 1.5 mit 0,15. Die Margen sind insgesamt nicht riesig, aber in den schwierigsten Reasoning-Kategorien groß.

ODinW-13 und die These „Generierung verbessert Verständnis“
Uni-1 schneidet auch auf ODinW-13, einem Open-Vocabulary-Dense-Detection-Benchmark, stark ab. Berichte über Lumas technische Daten sagen, dass das Vollmodell 46,2 mAP erreicht und damit nahezu Googles Gemini 3 Pro mit 46,3 entspricht. Dieselben Berichte sagen, dass eine reine Verständnis-Variante 43,9 mAP erreicht, was impliziert, dass Generierungs-Training das Verständnis um 2,3 Punkte verbessert. Das ist bemerkenswert, weil es Lumas Kernaussage stützt: Bildgenerierung und Bildverständnis könnten sich gegenseitig verstärken statt konkurrieren.
Preis der Uni-1-API
| Eingabepreis (Text) | $0.50 |
|---|---|
| Eingabepreis (Bilder) | $1.20 |
| Ausgabepreis (Text und Denken) | $3.00 |
| Ausgabepreis (Bilder) | $45.45 |
Auf der Consumer-Seite listet Lumas Preisseite Plus mit $30/Monat, Pro mit $90/Monat und Ultra mit $300/Monat, mit kostenlosen Testguthaben in allen Plänen. Das bedeutet, es sind im Wesentlichen zwei Preisebenen zu berücksichtigen: die Consumer-Mitgliedschaft für die Plattform und die modellbezogene API-Bepreisung für den Produktionseinsatz.
Derzeit ist CometAPIs Uni-1-API „Available Soon“, mit einem versprochenen Rabatt zum Start. Aktuell bietet CometAPI auch exzellente Raw-Bildmodelle wie Midjourney und Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 versus Googles Nano Banana 2
Nano Banana 2 wirkt stärker in der Breite der Referenzverarbeitung und Ökosystemintegration. Google betont Bildsuch-Verankerung, konversationale Iteration und referenzlastige Workflows mit bis zu 14 Referenzen. Uni-1 hingegen wird expliziter um Reasoning, Szenenplausibilität und präzise Bearbeitung in einer vereinten Modellarchitektur gerahmt. Praktisch erscheint Google auf Geschwindigkeit, Mainstream-Produktionsmaßstab und native Google-Verankerung optimiert; Luma erscheint auf strukturiertes visuelles Reasoning und dirigierbare Bildbearbeitung optimiert.
In den öffentlichen Vergleichen rund um Uni-1 ist der Trade-off klar: Nano Banana 2 bleibt offenbar sehr stark bei reiner Text-zu-Bild-Qualität und -Geschwindigkeit, während Uni-1 stärker auf reasoninglastige Bearbeitung, Referenzkontrolle und Anweisungsgetreue drängt.
Uni-1 versus OpenAIs GPT Image
In Benchmark-Berichten liegt Uni-1 bei RISEBench insgesamt knapp vor GPT Image 1.5 und beim logischen Reasoning deutlicher. Verglichen mit OpenAIs GPT Image-Familie ist Uni-1 enger und aggressiver auf visuelles Reasoning und kontrollierte Bearbeitung positioniert. OpenAIs Dokus betonen Weltwissen, multimodales Verständnis und Kontextsensitivität; Lumas Dokus betonen strukturiertes internes Reasoning, referenzverankerte Kontrolle und benchmarkte visuelle Bearbeitungskompetenz. Während beide multimodal sind, ist Uni-1 das offensichtlichere „bildspezialisierte Reasoning-Modell“, während GPT Image eher wie ein allgemeines multimodales System wirkt, das zufällig auch sehr gut Bilder generiert.
Preisvergleich zwischen den dreien
Beim Pricing hängt der Vergleich von Ausgabengröße und Produktstufe ab, daher ist er nicht perfekt vergleichbar. Uni-1s veröffentlichter 2048px-Äquivalent liegt bei etwa $0.0909 pro Bild. Googles neueste Bildmodell-Preisseite listet $0.134 pro 1K/2K-Bild und $0.24 pro 4K-Bild für die neueste Gemini-Image-Preview, während OpenAIs GPT Image-Preisseite eine pro-Bild-Ausgabebepreisung von $0.011 bei niedriger Qualität für 1024x1024, $0.042 bei mittlerer Qualität und $0.167 bei hoher Qualität listet, mit größeren hochwertigen Ausgaben bei $0.25. Anders gesagt: OpenAI kann am unteren Ende deutlich günstiger sein, Google ist am Speed-und-Scale-Ende aggressiv, und Uni-1 landet in der Mitte mit einem starken, auf 2K ausgerichteten Preis-Leistungs-Profil.
Philosophische Unterschiede
| Modell | Ansatz |
|---|---|
| Uni-1 | Vereinte multimodale Intelligenz |
| GPT Image | LLM + Bildgenerierung |
| Nano Banana 2 | Optimierte Produktions-Diffusion |
Detaillierte Vergleichstabelle
| Feature | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Architektur | Autoregressiv | Hybrid | Diffusion |
| Multimodale Vereinigung | ✅ Native | Partiell | ❌ |
| Reasoning-Fähigkeit | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Bildqualität | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Textrendering | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Bearbeitungs-Workflows | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Geschwindigkeit | Mittel | Schnell | Schnell |
| Kontrolle | Hoch | Mittel | Mittel |
CometAPI bietet interaktive Raw-Bilder für GPT Image 1.5, Nano Banana 2, sowie das kommende Uni-1 und API-Programmierung. Rabattierte Preise und Pay-as-you-go-Optionen machen es zu einer bevorzugten Wahl für Entwickler.
Wofür Uni-1 am besten geeignet ist
Uni-1 wirkt besonders stark in Fällen, in denen du Reproduzierbarkeit, Charakterkonsistenz oder Kontrolle über mehrere Referenzen brauchst. Dazu zählen Marken-Kampagnen, Produkt-Mockups, Editorial-Konzepte, Storyboards, Lokalisierungsvarianten und Bildbearbeitungen, bei denen die Komposition intakt bleiben muss, Stil oder Umgebung sich aber ändern sollen. Lumas eigene Beispiele stützen sich stark auf diese Anwendungsfälle, und die „Create vs Modify“-Aufteilung des Modells ist im Grunde eine direkte Antwort auf gängige Produktionsschmerzpunkte.
Wenn deine Arbeit hauptsächlich „mach aus einem Prompt etwas Schönes“ ist, wirkt der Unterschied vielleicht weniger dramatisch. Wenn dein Workflow aber „mache fünf verwandte Versionen, behalte denselben Charakter, erhalte die Framing, ändere das Licht und mache es nächste Woche reproduzierbar“ lautet, ergibt das Design von Uni-1 viel Sinn. Das ist eine Schlussfolgerung, folgt aber natürlich aus den von Luma betonten Kontrollfeatures.
Best Practices für bessere Ergebnisse mit Uni-1
Beginne mit dem richtigen Modus. Lumas Leitfaden ist simpel: Create, wenn du eine neue Szene willst, Modify, wenn du eine bestehende erhalten willst. Das Mischen dieser Intentionen macht die Ergebnisse wackliger.
Nutze Referenzlabels wie ein Profi. Luma empfiehlt Formulierungen wie „Use IMAGE1 as a STYLE reference“ oder „Use IMAGE2 as LIGHTING“. Das Modell arbeitet besser, wenn jede Referenz einen Job hat statt vager „Inspiration“.
Fixiere den Seed, nachdem du etwas Gutes gefunden hast. Luma empfiehlt ausdrücklich, zunächst ohne Seed zu explorieren und den Seed zu speichern, sobald du ein starkes Ergebnis hast. Danach ändere eine Variable nach der anderen. Das ist der einfachste Weg, Generierung in ein kontrolliertes Produktionssystem zu verwandeln.
Sei spezifisch und konkret. Luma warnt vor vagen Worten wie „beautiful“ oder „amazing“ und ermutigt stattdessen benannte Ästhetiken wie „1970s Italian giallo film poster“ oder exakte Kamera-Stilhinweise. In der Praxis schlagen spezifische Prompts meist poetische Prompts, weil das Modell sich an realer Struktur orientieren kann.
Nutze die Create → Modify-Kette. Luma nennt dies ausdrücklich einen seiner stärksten Workflows: in Create explorieren, dann in Modify verfeinern. Das ist der Sweet Spot für ernsthafte Produktionsarbeit, weil es Backtracking reduziert und die guten Teile einer Komposition bewahrt, während die Details geschärft werden.
Schlussfazit
Uni-1 ist Lumas bislang klarste Aussage, dass Bildgenerierung sich von „Prompt rein, Bild raus“ hin zu reasoning-geleiteter visueller Kreation bewegt. Seine öffentlichen Stärken sind Kontrolle, Referenzverarbeitung, Reproduzierbarkeit und eine Modellarchitektur, die Sprache und Pixel im selben System hält.
Für Kreative und Teams, denen hochklickbare visuelle Ergebnisse, konsistente Charaktere, präzise Edits und klare High-Resolution-Bepreisung wichtig sind, ist Uni-1 definitiv ein Modell, das man im Blick behalten sollte. Wenn der API-Rollout sauber gelingt, könnte es 2026 zu einer der interessantesten Alternativen zu Googles Nano Banana 2 und OpenAIs GPT Image 1.5 werden.
Du planst, mit Raw-Bildern zu starten? CometAPI, eine One-Stop-Aggregationsplattform für multimodale Modell-APIs, heißt dich willkommen!