Gemini 2.5 Flash ist darauf ausgelegt, schnelle Antworten zu liefern, ohne die Qualität der Ausgabe zu beeinträchtigen. Es unterstützt multimodale Eingaben, darunter Text, Bilder, Audio und Video, und eignet sich damit für vielfältige Anwendungen. Das Modell ist über Plattformen wie Google AI Studio und Vertex AI zugänglich und stellt Entwicklern die notwendigen Tools für eine nahtlose Integration in verschiedene Systeme bereit.
Grundlegende Informationen (Funktionen)
Gemini 2.5 Flash führt mehrere herausragende Funktionen ein, die es innerhalb der Gemini-2.5-Familie hervorheben:
- Hybrides Reasoning: Entwickler können einen thinking_budget-Parameter festlegen, um fein zu steuern, wie viele Tokens das Modell vor der Ausgabe für internes Reasoning aufwendet.
- Pareto-Grenze: An der optimalen Preis-Leistungs-Position platziert, bietet Flash das beste Preis-zu-Intelligenz-Verhältnis unter den 2.5-Modellen.
- Multimodale Unterstützung: Verarbeitet Text, Bilder, Video und Audio nativ und ermöglicht reichhaltigere Gesprächs- und Analysefunktionen.
- 1-Millionen-Token-Kontext: Unerreichte Kontextlänge ermöglicht tiefgehende Analysen und das Verständnis langer Dokumente in einer einzigen Anfrage.
Modellversionierung
Gemini 2.5 Flash hat die folgenden wichtigen Versionen durchlaufen:
- gemini-2.5-flash-lite-preview-09-2025: Verbesserte Tool-Bedienbarkeit: Bessere Leistung bei komplexen, mehrschrittigen Aufgaben mit einer 5%igen Steigerung der SWE-Bench Verified-Scores (von 48.9% auf 54%). Verbesserte Effizienz: Bei aktiviertem Reasoning wird mit weniger Tokens eine höhere Ausgabequalität erzielt, was Latenz und Kosten reduziert.
- Preview 04-17: Frühzugangsversion mit „thinking“-Fähigkeit, verfügbar über gemini-2.5-flash-preview-04-17.
- Stabile allgemeine Verfügbarkeit (GA): Seit dem 17. Juni 2025 ersetzt der stabile Endpunkt gemini-2.5-flash die Preview und gewährleistet Produktionsreife ohne API-Änderungen gegenüber der Preview vom 20. Mai.
- Abschaltung der Preview: Preview-Endpunkte waren für die Abschaltung am 15. Juli 2025 geplant; Nutzer müssen vor diesem Datum auf den GA-Endpunkt migrieren.
Mit Stand Juli 2025 ist Gemini 2.5 Flash nun öffentlich verfügbar und stabil (keine Änderungen gegenüber gemini-2.5-flash-preview-05-20).Wenn Sie gemini-2.5-flash-preview-04-17 verwenden, gelten die bestehenden Preview-Preise bis zur planmäßigen Außerdienststellung des Modellendpunkts am 15. Juli 2025, wenn er abgeschaltet wird. Sie können auf das allgemein verfügbare Modell "gemini-2.5-flash" migrieren.
Schneller, günstiger, intelligenter:
- Designziele: geringe Latenz + hoher Durchsatz + niedrige Kosten;
- Gesamtbeschleunigung beim Reasoning, in der Multimodal-Verarbeitung und bei Langtextaufgaben;
- Der Token-Verbrauch wird um 20–30% reduziert, was die Reasoning-Kosten deutlich senkt.
Technische Spezifikationen
Eingabekontextfenster: Bis zu 1 Million Tokens, was umfangreiche Kontextbeibehaltung ermöglicht.
Ausgabe-Tokens: Kann bis zu 8.192 Tokens pro Antwort generieren.
Unterstützte Modalitäten: Text, Bilder, Audio und Video.
Integrationsplattformen: Verfügbar über Google AI Studio und Vertex AI.
Preisgestaltung: Wettbewerbsfähiges tokenbasiertes Preismodell, das eine kosteneffiziente Bereitstellung erleichtert.
Technische Details
Unter der Haube ist Gemini 2.5 Flash ein transformer-basiertes großes Sprachmodell, das auf einer Mischung aus Web-, Code-, Bild- und Videodaten trainiert wurde. Wichtige technische Spezifikationen umfassen:
Multimodales Training: Trainiert zur Ausrichtung mehrerer Modalitäten, kann Flash Text nahtlos mit Bildern, Video oder Audio kombinieren, nützlich für Aufgaben wie Videosummarization oder Audiobeschreibung.
Dynamischer Denkprozess: Implementiert eine interne Reasoning-Schleife, in der das Modell plant und komplexe Prompts aufschlüsselt, bevor die finale Ausgabe erfolgt.
Konfigurierbare Thinking-Budgets: Der thinking_budget kann von 0 (kein Reasoning) bis 24,576 tokens gesetzt werden und ermöglicht Abwägungen zwischen Latenz und Antwortqualität.
Tool-Integration: Unterstützt Grounding with Google Search, Code Execution, URL Context und Function Calling und ermöglicht reale Aktionen direkt aus natürlichsprachigen Prompts.
Benchmark-Leistung
In rigorosen Evaluierungen zeigt Gemini 2.5 Flash führende Performance:
- LMArena Hard Prompts: Erreichte zweiten Platz nur hinter 2.5 Pro auf dem anspruchsvollen Hard-Prompts-Benchmark und demonstriert starkes mehrstufiges Reasoning.
- MMLU-Score von 0.809: Übertrifft die durchschnittliche Modellleistung mit einer 0.809 MMLU-Genauigkeit und spiegelt breites Domänenwissen und Reasoning-Kompetenz wider.
- Latenz und Durchsatz: Erzielt 271.4 tokens/sec Dekodiergeschwindigkeit mit 0.29 s Time-to-First-Token und ist damit ideal für latenzkritische Workloads.
- Preis-Leistungs-Führer: Bei \$0.26/1 M tokens unterbietet Flash viele Wettbewerber und erreicht auf wichtigen Benchmarks gleiche oder bessere Ergebnisse.
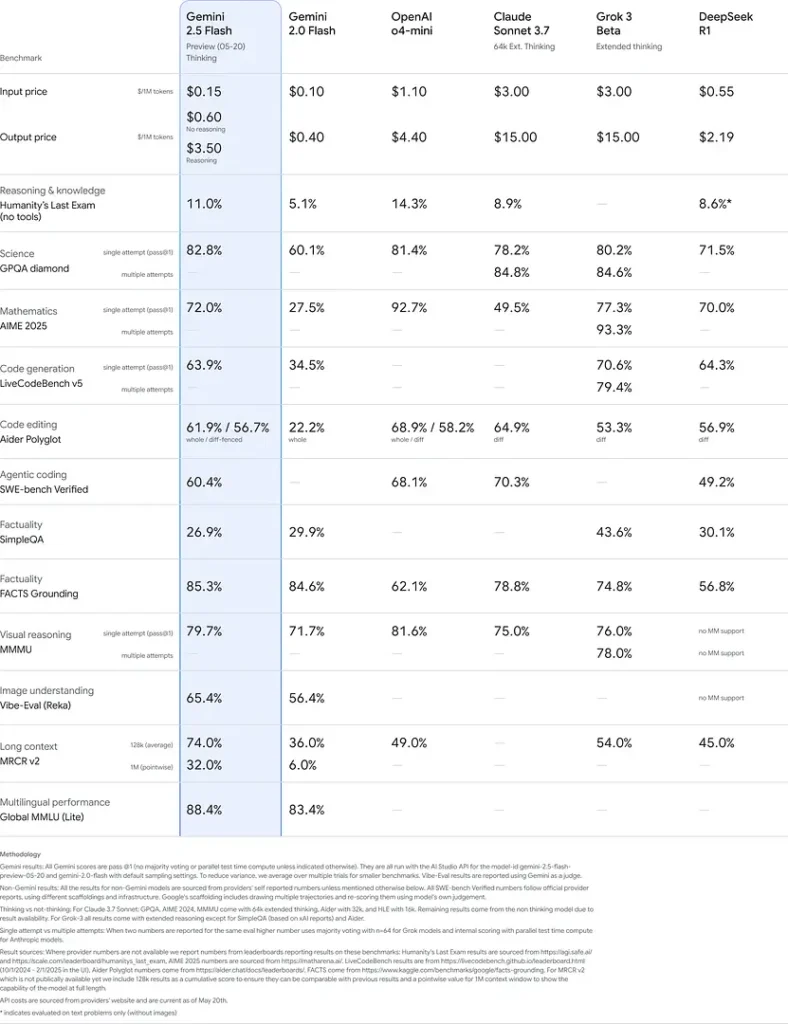
Diese Ergebnisse deuten auf den Wettbewerbsvorteil von Gemini 2.5 Flash in den Bereichen Reasoning, wissenschaftliches Verständnis, mathematische Problemlösung, Programmierung, visuelle Interpretation und Mehrsprachigkeit hin:
Einschränkungen
Trotz seiner Leistungsfähigkeit weist Gemini 2.5 Flash einige Einschränkungen auf:
- Sicherheitsrisiken: Das Modell kann einen "preachy"-Ton annehmen und plausibel klingende, aber falsche oder voreingenommene Ausgaben (Halluzinationen) erzeugen, insbesondere bei Randfallanfragen. Strenge menschliche Aufsicht bleibt essenziell.
- Ratenlimits: Die API-Nutzung ist durch Limits (10 RPM, 250,000 TPM, 250 RPD auf Standardstufen) beschränkt, was sich auf Batch-Verarbeitung oder Anwendungen mit hohem Volumen auswirken kann.
- Intelligenz-Untergrenze: Obwohl für ein Flash-Modell außergewöhnlich leistungsfähig, ist es bei den anspruchsvollsten agentischen Aufgaben wie fortgeschrittenem Coding oder Multi-Agent-Koordination weniger genau als 2.5 Pro.
- Kostenabwägungen: Obwohl es die beste Preis-Leistung bietet, erhöht umfangreiche Nutzung des thinking-Modus den gesamten Token-Verbrauch und damit die Kosten bei tiefem Reasoning.