Technische Details
- Adaptives Reasonieren:
Gemini 2.5 Flash-Liteunterstützt bedarfsorientiertes Denken, sodass Entwickler Rechenressourcen nur dann zuweisen, wenn tieferes Denken erforderlich ist. - Tool-Integrationen: Volle Kompatibilität mit den nativen Tools von Gemini 2.5, darunter Grounding with Google Search, Code Execution, URL Context und Function Calling für nahtlose multimodale Workflows.
- Model Context Protocol (MCP): Nutzt Googles MCP, um Webdaten in Echtzeit abzurufen, sodass Antworten aktuell und kontextuell relevant sind.
- Bereitstellungsoptionen: Verfügbar über die CometAPI, Gemini API, Vertex AI und Google AI Studio, mit einem Preview-Track für Early Adopters zum Experimentieren und Feedback geben .
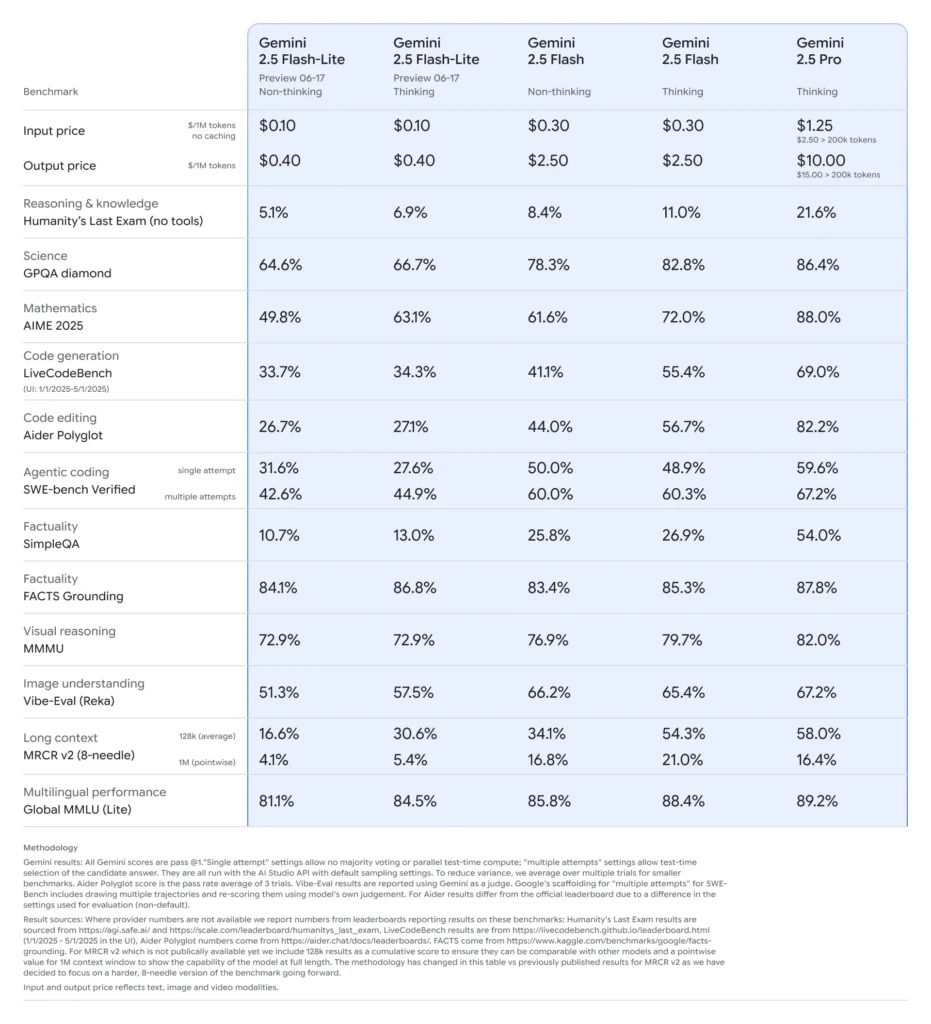
Benchmark-Leistung von Gemini 2.5 Flash-Lite
- Latenz: Erzielt bis zu 50% niedrigere mediane Antwortzeiten im Vergleich zu Gemini 2.5 Flash, mit typischen unter 100 ms Latenzen auf Standardbenchmarks für Klassifikation und Zusammenfassung.
- Durchsatz: Optimiert für hochvolumige Workloads und verarbeitet Zehntausende Anfragen pro Minute ohne Leistungsabfall.
- Preis-Leistung: Weist 25% geringere Kosten pro 1.000 Tokens gegenüber dem Flash-Gegenstück auf und ist damit die Pareto-optimale Wahl für kostensensitive Deployments.
- Branchenadoption: Frühe Nutzer berichten von nahtloser Integration in Produktions-Pipelines, wobei die Leistungskennzahlen den anfänglichen Prognosen entsprechen oder diese übertreffen .
Ideale Anwendungsfälle
- Hochfrequente, gering komplexe Aufgaben: Automatisches Tagging, Sentiment-Analyse und Massenübersetzung
- Kostensensitive Pipelines: Datenextraktion aus großen Dokumentenkorpora, periodische Batch-Zusammenfassungen
- Edge- und Mobile-Szenarien: Wenn Latenz kritisch ist, aber Ressourcenbudgets begrenzt sind
Einschränkungen von Gemini 2.5 Flash-Lite
- Preview-Status: Vor GA sind API-Änderungen möglich; Integrationen sollten mögliche Versionssprünge einkalkulieren.
- Kein Fine-Tuning on the fly: Benutzerdefinierte Gewichte können nicht hochgeladen werden; es wird auf Prompt Engineering und Systemnachrichten zurückgegriffen.
- Reduzierte Kreativität: Abgestimmt auf deterministische Aufgaben mit hohem Durchsatz; weniger geeignet für offene Generierung oder „kreatives“ Schreiben.
- Ressourcengrenze: Skaliert linear nur bis ~16 vCPUs; darüber hinaus nehmen Durchsatzgewinne ab.
- Multimodale Einschränkungen: Unterstützt Bild-/Audioeingaben, jedoch mit begrenzter Genauigkeit; nicht ideal für umfangreiche Vision- oder Audiotranskriptionsaufgaben.
- Kontextfenster-Trade-off : Obwohl bis zu 1 M Tokens akzeptiert werden, kann die praktische Inferenz in dieser Größenordnung einen verringerten Durchsatz aufweisen.