

Composer 2 von Cursor ist das neueste agentische Coding-Modell des Unternehmens, angekündigt am 19. März 2026. Cursor beschreibt es als „Frontier-Niveau beim Codieren“, ausgelegt für Softwarearbeit mit niedriger Latenz und direkt in Cursor verfügbar, mit einem eigenständigen Nutzungspool für Einzelpläne. Der Start brachte zudem eine schnellere Variante mit derselben Intelligenz sowie eine neue Preisstruktur, die agentisches Codieren erschwinglicher machen soll als viele allgemeine Frontier-Modelle.
Composer 2 ist wichtig, weil es einen breiteren Wandel in der KI-Softwareentwicklung widerspiegelt: Der Wert liegt nicht mehr nur in der rohen Modellintelligenz, sondern in der Kombination aus Geschwindigkeit, der Fähigkeit zur Bearbeitung von Aufgaben mit langem Horizont, Tool-Nutzung und Kosteneffizienz. Cursors eigene Beschreibung ist explizit: Das Modell ist für agentisches Codieren optimiert, kann anspruchsvolle Aufgaben bewältigen, die Hunderte von Aktionen erfordern, und wurde darauf trainiert, kritischen Kontext über langlaufende Workflows hinweg zu erhalten.
Was ist Composer 2?
Ein Modell für agentisches Codieren, nicht nur Textvervollständigung
Composer 2 ist Cursors eigenes Coding-Modell. Composer 2 ist spezialisiert auf Software-Engineering-Intelligenz und Geschwindigkeit, im Cursor-Agent-Harness trainiert, und darauf ausgelegt, bei echten Coding-Aufgaben gut zu funktionieren statt in generischen Chats. Das ist wichtig, weil agentisches Codieren sich von gewöhnlicher Codegenerierung unterscheidet: Das Modell muss eine Codebasis durchsuchen, Dateien bearbeiten, über mehrere Schritte hinweg schlussfolgern und sich von Fehlern erholen, ohne den roten Faden der Aufgabe zu verlieren. Cursors Beitrag zum Long-Horizon-Training macht dieses Designziel sehr deutlich.
Dual Model Variants:
| Variante | Zweck |
|---|---|
| Standard | Niedrigste Kosten |
| Fast | Höhere Geschwindigkeit (Standard) |
Warum Cursor es gebaut hat
Cursors Forschungsbeiträge deuten auf eine einfache These hin: Bessere Coding-Agenten brauchen sowohl Intelligenz als auch eine effiziente Fortsetzung über viele Schritte. Beobachtungen aus dem internen Benchmark (CursorBench) zeigen, dass stärkere Leistung bei schwierigen realen Coding-Aufgaben mit mehr Denken und mehr Exploration der Codebasis korreliert. Composer 2 wurde daher nicht nur darauf trainiert, Aufgaben zu lösen, sondern sie über lange Trajektorien hinweg weiter zu lösen, die die unmittelbare Kontextlänge des Modells überschreiten.
Wie funktioniert Composer 2?
Fortgesetztes Vortraining ist das große Upgrade
Die Qualitätsgewinne von Composer 2 kommen von seinem „ersten Lauf mit fortgesetztem Vortraining“, der eine deutlich stärkere Grundlage für Reinforcement Learning bietet. Das ist wichtig, weil es nahelegt, dass das Modell nicht nur eine getunte Version von Composer 1.5 ist; es ist ein besserer Ausgangspunkt für das langhorizontige Coding-Verhalten, das Cursor anstrebt.
Reinforcement Learning auf langen Coding-Trajektorien
Nach dem fortgesetzten Vortraining trainiert Cursor Composer 2 mit Reinforcement Learning auf langhorizontigen Coding-Aufgaben. Das Unternehmen behauptet, Composer 2 könne schwierige Probleme lösen, die Hunderte von Aktionen erfordern. Praktisch bedeutet das, dass das Modell darauf trainiert wird, durch mehrstufiges Debugging, Code-Navigation und iterative Reparaturschleifen zu persistieren, statt eine Einmal-Antwort zu liefern und dort aufzuhören.
Selbstzusammenfassung ist ein zentraler Forschungsfortschritt
Cursor trainiert Composer für längere Horizonte mittels „Selbstzusammenfassung“. In diesem Setup pausiert das Modell, wenn es einen Kontext-Trigger erreicht, fasst seinen eigenen Arbeitszustand zusammen und setzt dann aus diesem komprimierten Kontext fort. Cursor sagt, diese Technik erlaube es, auf Trajektorien zu trainieren, die deutlich länger sind als das maximale Kontextfenster des Modells, und die Zusammenfassungen selbst als Teil des Trainingssignals zu belohnen.
Robustheit
Der praktische Vorteil ist Robustheit. Lange Coding-Aufgaben scheitern oft, wenn ein Agent eine frühere Entscheidung vergisst oder wichtige Details in einem ausufernden Arbeitsbereich verliert. Selbstzusammenfassung reduziert den Verdichtungsfehler um 50 %, während nur ein Fünftel der Tokens genutzt wird, verglichen mit einer abgestimmten, promptbasierten Verdichtungs-Baseline in den Testumgebungen. Das ist eine substanzielle Behauptung, denn Verdichtung ist eine der Schwächen aktueller Agentensysteme.
Was ist neu in Composer 2?
1. Fortgesetztes Vortraining + RL-Skalierung
Composer 2 führt Cursors erste großskalige Pipeline für fortgesetztes Vortraining ein und schafft damit ein stärkeres Basismodell für Reinforcement Learning.
Dann folgt:
- Long-Horizon-RL-Training
- Task-Chaining über mehrere Schritte
- Reale Coding-Workflows
👉 Ergebnis: Bessere Bewältigung von komplexen Engineering-Aufgaben, nicht nur Codeschnipseln.
2. Langfristige Aufgabenausführung
Anders als frühere Modelle, die nach wenigen Schritten scheitern:
- Composer 2 kann Refactorings über mehrere Dateien abschließen
- Terminal-Workflows ausführen
- Zustand über Hunderte von Aktionen beibehalten
Das treibt es in Richtung echten KI-Coding-Agenten-Verhaltens.
3. Nur-Code-Trainingsstrategie
Composer 2 wird ausschließlich auf programmbezogenen Daten trainiert.
Warum das wichtig ist:
| Faktor | Allgemeine Modelle | Composer 2 |
|---|---|---|
| Modellgröße | Groß | Kleiner |
| Umfang | Breit | Eng |
| Effizienz | Niedriger | Höher |
| Kosten | Hoch | Niedrig |
👉 Das erklärt den massiven Preis-Leistungs-Vorteil.
4. Hybride Grundlage (Kimi-Basis + RL)
Jüngste Offenlegungen zeigten, dass Composer 2 zunächst auf Kimi K2.5 (Moonshot AI) aufgebaut wurde, mit zusätzlichem Reinforcement-Training.
- Nur ~25 % Rechenaufwand vom Basismodell
- Der Großteil aus Cursors Trainings-Stack
👉 Das spiegelt einen neuen Trend wider: hybride Modell-Entwicklung + proprietäre Optimierung
Leistungs-Benchmarks
| Modell | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Im Vergleich zu Composer 1.5 liegt Composer 2 etwa 38,7 % höher auf dem CursorBench, 28,8 % höher auf dem Terminal-Bench 2.0 und 11,8 % höher auf SWE-bench Multilingual. Das beweist keine universelle Überlegenheit gegenüber jedem externen Modell, zeigt aber einen klaren Schritt nach vorn innerhalb von Cursors eigener Modellreihe.
Wie greifen Sie auf Composer 2 zu?
Cursor positioniert Composer 2 als Teil des agent-first Workflows des Produkts. Es ist in Cursor verfügbar, und Cursor sagt, dass bei Einzelplänen die Composer-Nutzung aus einem eigenständigen Nutzungspool kommt, mit großzügig inkludierter Nutzung. Cursor sagt außerdem, dass Nutzer Composer 2 in der „Early Alpha“ seiner neuen Oberfläche ausprobieren können. Das bedeutet, Composer 2 ist nicht nur eine Modell-API; es soll innerhalb von Cursors Agent-Workflow verwendet werden, in dem Editor, Agent, Browser und Review-Tools zusammenarbeiten.
In Cursor
Composer 2 ist in Cursor und auch in der Early Alpha der neuen Oberfläche verfügbar. Das praktische Zugriffsmodell ist produkt-nativ statt API-first: Nutzer interagieren damit im Cursor-Editor und seinem Agent-Workflow. Das ist konsistent mit Cursors übergreifender Richtung, in der das Unternehmen den Editor als primäre Oberfläche für die Modellinteraktion behandelt.
Nutzungspools und Planstruktur
Jeder Einzelplan umfasst zwei Nutzungspools, die sich in jedem Abrechnungszyklus zurücksetzen: Auto + Composer, das deutlich mehr inkludierte Nutzung bietet, wenn Auto oder Composer 2 ausgewählt ist, und einen API-Pool, der zum API-Tarif des Modells abgerechnet wird. Cursor sagt außerdem, dass Einzelpläne monatlich mindestens 20 $ API-Nutzung enthalten, wobei der genaue Betrag in höheren Stufen steigt. Die praktische Quintessenz ist, dass Composer 2 darauf ausgelegt ist, häufig verwendet zu werden, ohne jede Anfrage sofort in reine API-Abrechnung zu zwingen.
API-Preis:
$0.50 Input / $2.50 Output pro 1 Mio. Tokens; schnelle Variante $1.50 / $7.50
Plan-Kontext
Cursor Pro für $20 pro Monat, Pro Plus für $60 und Ultra für $200, jeweils mit unterschiedlichen inkludierten Nutzungsumfängen. Für Teams bietet Cursor außerdem Teams und Enterprise mit zusätzlichen Kontrollen. Das ist wichtig, denn Composer 2 ist nicht nur ein Modell-SKU; es ist Teil eines breiteren Produktpakets, das Preise, Nutzungspools und Kollaborationskontrollen kombiniert.
Composer 2 vs Claude Opus 4.6 vs GPT-5.4: Welche sollte ich wählen?
Terminal-Bench 2.0
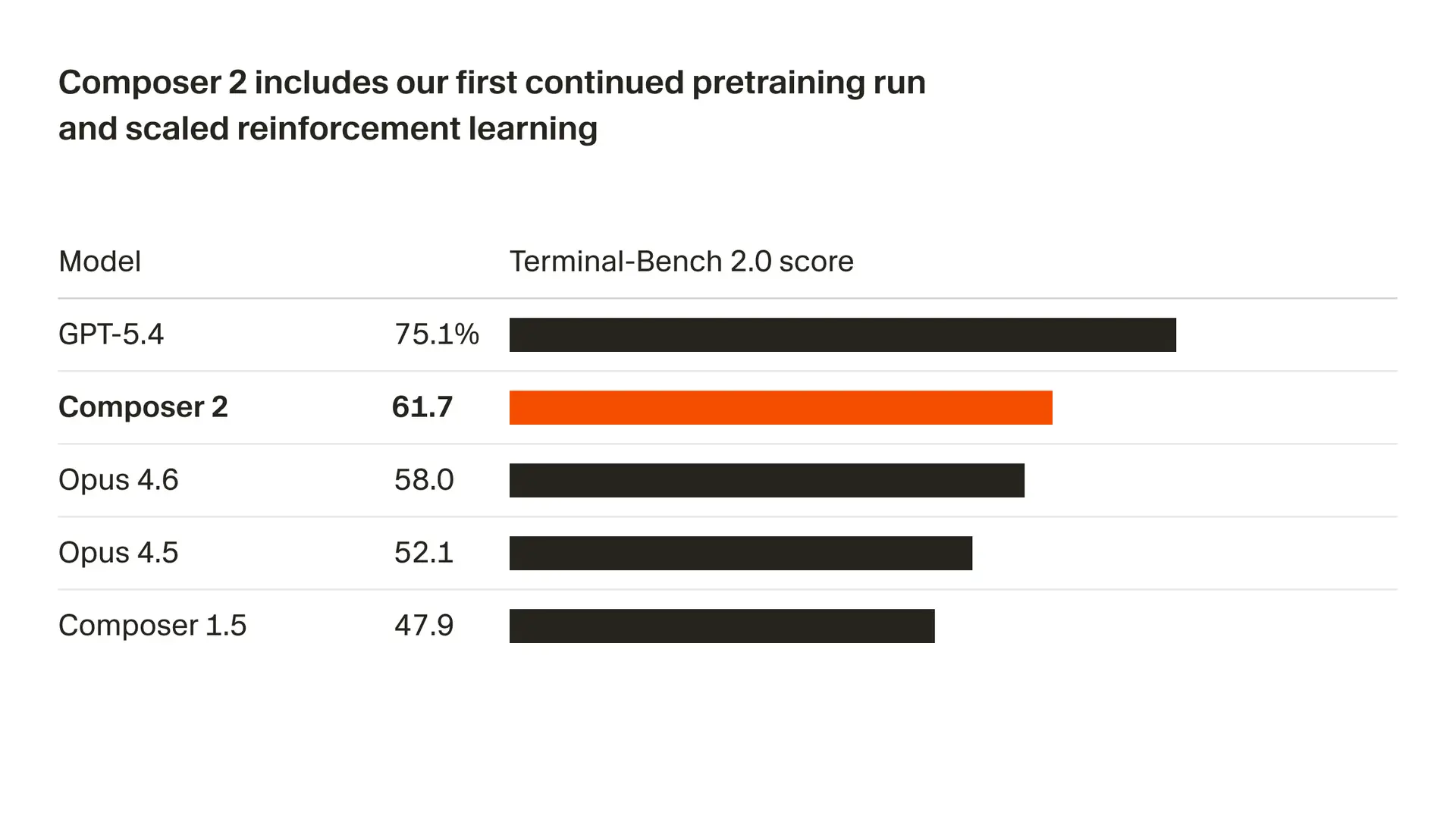
| Modell | Punktzahl |
|---|---|
| Composer 2 | 61.7 |
| Claude Opus 4.6 | ~58 |
| GPT-5.4 | ~75 |
👉 Composer 2:
Liegt hinter GPT-5.4 in der Spitzenleistung
Schlägt Opus 4.6 in einigen Setups
Offizielle Preise
| Modell | Input ($/M Tokens) | Output ($/M Tokens) |
|---|---|---|
| Composer 2 | 0.50 | 2.50 |
| Composer 2 Fast | 1.50 | 7.50 |
| Claude Opus 4.6 | 5.00 | 25.00 |
| GPT-5.4 | 2.50–5.00 | 15.00–22.50 |
👉 Composer 2 ist:
- 10× günstiger als Opus 4.6
- ~5–6× günstiger als GPT-5.4
Warum sind Claude Opus 4.6 und GPT-5.4 dennoch sinnvoll?
Composer 2 passt stark zu Entwicklern, die die meiste Zeit in Cursor verbringen, insbesondere bei repetitiven Code-Editing-Schleifen, Refactorings, Änderungen über mehrere Dateien und agentischen Aufgaben, die von Geschwindigkeit und Kosteneffizienz profitieren; es ist rund um Code und langhorizontige Aktionsausführung optimiert, mit einer Preisgestaltung, die drastisch niedriger ist.
Aber Claude Opus 4.6 und GPT-5.4 bringen jeweils breitere professionelle Fähigkeiten, große Kontextfenster und reichere Enterprise-Funktionen. Wenn Sie in einem Durchgang einen ausgefeilten Essay, eine Tabelle und einen Browser-Agent-Workflow produzieren müssen.
Vergleichstabelle:
| Merkmal | Composer 2 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Fokus | Nur Coding | Allgemeine KI | Allgemeine KI |
| Kosten | ⭐ Am niedrigsten | Sehr hoch | Mittel |
| Codegenauigkeit | Hoch | Sehr hoch | Hoch |
| Denkvermögen | Mittel | Sehr hoch | Sehr hoch |
| Geschwindigkeit | Schnelle Variante verfügbar | Moderat | Moderat |
| Agentenfähigkeit | Stark | Stark | Verbessert sich |
| Multimodal | ❌ | ✅ | ✅ |
| Bester Anwendungsfall | Dev-Workflows | Aufgaben in Forschungsqualität | Allgemeines + Coding |
Passende Anwendungsfälle und Zugriff
Wenn die Aufgabe breites Reasoning, multimodale Arbeit oder allgemeinen Enterprise-Einsatz erfordert, sind GPT-5.4 und Claude Opus 4.6 beide starke Kandidaten, basierend auf ihrer offiziellen Positionierung und ihren Fähigkeiten. Wenn die Aufgabe tägliches Codieren in Cursor ist, insbesondere wo Kosten und Iterationsgeschwindigkeit zählen, ist Composer 2 die spezialisiertere und günstigere Wahl. Cursor positioniert Composer 2 als spezialisiertes agentisches Coding-Modell für Cursor selbst. GPT-5.4 und Opus 4.6 sind breite Frontier-Modelle, während Composer 2 zweckgebaut für die IDE-Agent-Schleife ist.
OpenAI positioniert GPT-5.4 als Frontier-Modell für komplexe professionelle Arbeit, mit Tool-Unterstützung in der API und starker allgemeiner Reasoning-Fähigkeit. Anthropic positioniert Claude Opus 4.6 als sein intelligentestes Modell für Coding, Reasoning und agentische Arbeit; alle sind mit Verfügbarkeit über CometAPI erhältlich.
Die API von CometAPI ist derzeit um 20 % reduziert und kann direkt Playgrounds generieren. Im Vergleich zu anderen Lösungen ist CometAPI eine deutlich bessere Option; es ist im Grunde ein Cursor, der kein Abonnement benötigt.
Fazit
Composer 2 ist nicht nur ein weiteres inkrementelles Cursor-Modell. Es ist Cursors Versuch, die Preis-Leistungs-Kurve für Coding-Agenten neu zu setzen: stärkere Benchmark-Ergebnisse als seine Vorgänger, ein Design, das auf langhorizontiges agentisches Verhalten ausgerichtet ist, und Preise, die die großen Frontier-Alternativen drastisch unterbieten. Cursors eigene Evidenz zeigt klare Zugewinne gegenüber Composer 1 und 1.5, während die Preise Claude Opus 4.6 bei den Input-Tokens um das 10-Fache und GPT-5.4 um das 5-Fache unterbieten.
Für Teams, die bereits in Cursor leben, ist Composer 2 für viele Coding-Aufgaben eine überzeugende Standardeinstellung. Für die härtesten, hochriskantesten oder breitesten Aufgaben bleiben Claude Opus 4.6 und GPT-5.4 die Premium-Benchmarks zum Vergleich. Die eigentliche Geschichte ist, dass der Frontier-Coding-Markt gleichzeitig schärfer, günstiger und spezialisierter wird.
Wenn Sie nach einer Alternative zu Cursor suchen oder nach einer günstigeren, hochmodernen Modell-API wie Claude Opus 4.6 und GPT-5.4, dann ist CometAPI die beste Wahl. Bereit loszulegen?