

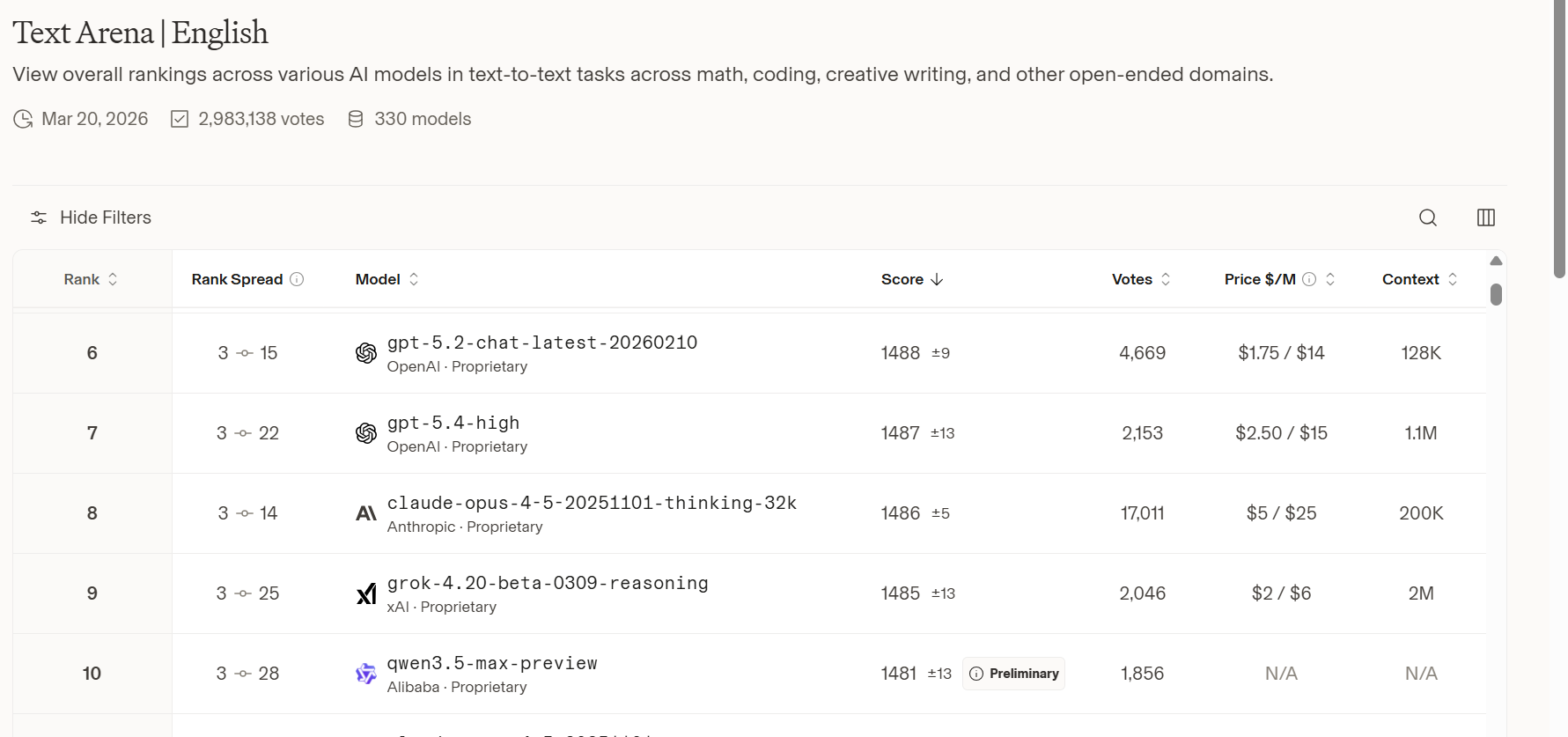
Das Qwen-Team von Alibaba hat seine Modellreihe mit der Einführung von Qwen3.5-Max-Preview im Februar 2026 in eine neue Phase geführt – eine Flaggschiff-Veröffentlichung innerhalb der Qwen3.5-Familie, die das Team als natives multimodales Agentenmodell positioniert. In der neuesten öffentlichen Leaderboard-Snapshot wurde qwen3.5-max-preview am 19. März 2026 zur Text-Rangliste von LMArena hinzugefügt und erscheint derzeit auf Rang 10 der englischen Text-Rangliste sowie auf Rang 15 der übergreifenden Text-Rangliste.
Seit dem Vorabend des Mondneujahrs hat die Qwen 3.5-Serie nacheinander acht Modelle mit unterschiedlichen Parametermaßen veröffentlicht, von 0.8B bis 397B. Sie können auf Qwen 3.5 Flash, qwen3.5-plus und qwen3.5-397b-a17b zugreifen.
Was ist Qwen 3.5-Max?
Qwen 3.5-Max repräsentiert die Flaggschiff-Stufe der Qwen 3.5-Modellreihe von Alibaba und ist darauf ausgelegt, direkt mit führenden KI-Modellen von OpenAI, Anthropic und Google zu konkurrieren.
Im Kern ist Qwen 3.5-Max:
- Ein großskaliges Mixture-of-Experts-(MoE)-Modell
- Ausgelegt für agentische KI-Workflows
- Optimiert für hochwertiges Reasoning, Coding und multimodale Aufgaben
- Darauf ausgelegt, Kosten zu senken und gleichzeitig die Leistung zu steigern
Die Qwen 3.5-Familie ist eine Weiterentwicklung früherer Qwen-Modelle, jedoch mit einer strategischen Neuausrichtung auf autonome KI-Agenten – Systeme, die komplexe Workflows über Tools und Umgebungen hinweg eigenständig ausführen können.
Qwen 3.5-Max wird als ein maßgeblicher Wettbewerber in der „Ära der agentischen KI“ positioniert, in der Modelle nicht nur Text generieren, sondern Aktionen in Anwendungen ausführen.
Qwen 3.5-Max springt in die weltweiten Top-Rankings
Ein beeindruckendes Debüt im Jahr 2026
Aktuelle Entwicklungen zeigen, dass Qwen 3.5-Max (und seine zugrunde liegende Architektur) rasch in den globalen KI-Ranglisten aufgestiegen ist und starke Leistungen über mehrere Benchmark-Suiten hinweg erzielt.
Zentrale Highlights:
qwen3.5-max-preview wurde laut Changelog am 19. März 2026 zur LMArena-Text-Rangliste hinzugefügt. Im Live-Leaderboard-Snapshot wird das Modell mit einem vorläufigen Score von 1481±13 in der englischen Text-Rangliste angezeigt, und in der breiteren Text-Rangliste erscheint es mit 1464±9, ebenfalls als vorläufig markiert:
- Platziert unter den Top-LLMs weltweit (in einigen Ranglisten im Bereich Top 5–Top 6)
- Erreichte Spitzenwerte in Reasoning- und Coding-Benchmarks
- Übertraf in mehreren Kategorien verschiedene US-Frontier-Modelle
Dieser schnelle Aufstieg spiegelt einen breiteren Wandel wider: Chinesische KI-Modelle konkurrieren inzwischen an der Spitze der globalen Ranglisten, nicht nur regional.
Benchmark-Leistung
Zentrale Benchmark-Scores
| Benchmark | Qwen 3.5-Max | Branchenposition |
|---|---|---|
| AIME (Mathematik) | 91.3 | Spitzenklasse |
| GPQA Diamond | 88.4 | Führend |
| LiveCodeBench v6 | 83.6 | Branchenführend |
| MMLU-Pro | ~84–86 | Oberste 20 % |
| BrowseComp | 78.6 | Klassenbeste |
Interpretation der Benchmarks
Stärken:
- Mathematisches Reasoning → nahe am Stand der Technik
- Coding → Spitzenklasse
- Wissenschaftliches Reasoning → führend
Schwächen:
- Einige Coding-Benchmarks liegen noch hinter den besten proprietären Modellen
- Konsistenz in realen Szenarien variiert je nach Aufgabe
Für Entwickler ist die praktische Quintessenz klar: Qwen3.5 wird als ein Modell positioniert, das in Chat, Coding, agentischen Workflows, Web-Recherche, multimodalem Verständnis und Langkontext-Aufgaben arbeiten kann. Die offizielle Ökosystem-Unterstützung für Qwen Chat, Qwen API, Qwen Code und Qwen Agent erleichtert Teams die Einführung des Modells in unterschiedlichen Formen, während die Benchmark-Tabelle nahelegt, dass es nicht nur ein Modell für den lokalen Markt ist, sondern in der globalen Spitzenklasse sinnvoll konkurrieren kann.
Warum erhält Qwen3.5-Max-Preview so viel Aufmerksamkeit? Lohnt es sich?
Die Aufmerksamkeit rührt aus einer seltenen Kombination aus drei Faktoren: einem Flaggschiff-Modellnamen, einem starken Arena-Debüt und einer breiteren Qwen3.5-Launch-Erzählung, die agentische Fähigkeiten und geringere Betriebskosten betont. Alibaba stellte Qwen 3.5 als ein Modell für die „Ära der agentischen KI“ vor und behauptet, es sei 60 % günstiger in der Nutzung und achtmal besser im Umgang mit großen Workloads als sein Vorgänger – zudem wurden visuelle agentische Fähigkeiten über Mobile- und Desktop-Umgebungen hinweg hinzugefügt.
Ein starker Auftakt, aber noch kein endgültiges Urteil
Qwen3.5-Max-Preview lässt sich am besten als Flaggschiff-Vorschau-Modell verstehen, das eine große, spärliche Architektur, native Multimodalität, langen Kontext, Mehrsprachigkeit und wettbewerbsfähige Benchmark-Leistung kombiniert. Sein Debüt bei LMArena, die schnelle Medienresonanz und die starke Benchmark-Tabelle deuten auf ein Modell hin, das im Wettbewerb an der Spitze bereits ernst zu nehmen ist. Gleichzeitig sollte die „Fünfter-Platz“-Erzählung mit Vorsicht gelesen werden: Der öffentliche Snapshot der Text-Rangliste zeigt eine solide, aber nicht oberste Platzierung, während die Berichterstattung auf Unternehmensebene ein insgesamt günstigeres Bild für Alibaba zeichnet.
Warum diese Veröffentlichung herausragt
Bemerkenswert an Qwen3.5-Max ist nicht eine einzelne Zahl, sondern die Kombination aus Fähigkeiten-Breite, Effizienzorientierung und Bereitstellungsflexibilität. Es ist selten, ein Modell zu sehen, das gleichzeitig für Reasoning über lange Kontexte, multimodales Verständnis, Tool-Nutzung, Agentenplanung und Einbindung in das Open-Weight-Ökosystem positioniert ist. Wenn Alibaba die Preview-Version zu einem vollständigen Release ausbaut, könnte Qwen3.5-Max zu einem der folgenreichsten Modelle der nächsten Welle des globalen KI-Wettbewerbs werden.
Fazit
Qwen3.5-Max-Preview ist am besten als Alibabas jüngstes Flaggschiff-Vorschau-Modell in der Qwen3.5-Linie zu verstehen: ein multimodales, agentenorientiertes System, das laut Unternehmen komplexe Aufgaben effizienter als zuvor bewältigen kann – mit offizieller Kommunikation, die visuelle agentische Fähigkeiten, geringere Kosten und stärkere Leistung bei großen Workloads betont. Sein LMArena-Debüt mit 1464 Punkten zeigt, dass das Modell sofort mit den sichtbarsten Systemen des Feldes konkurrieren kann, auch wenn sich genaue Ranglabels zwischen Live-Boards und Report-Formaten unterscheiden. In einem Markt, in dem Wahrnehmung, Leistung und Preisgestaltung zählen, reicht das aus, um Qwen3.5-Max zu einem der meistbeachteten Modell-Launches der Saison zu machen.
Wenn Sie als Entwickler nach den APIs der Qwen 3.5-Serie suchen, ist CometAPI eine gute Wahl. Die Preisstrategie und die Vielfalt der Integrationspartner sorgen dafür, dass Ihnen kein KI-Modell entgeht.