

Google y su brazo de investigación DeepMind han impulsado discretamente (y luego no tan discretamente) otro paso importante en la hoja de ruta de Gemini: Gemini 3.1 Pro. El lanzamiento, desplegado en superficies de cara al consumidor CometAPI, se posiciona como una actualización de rendimiento y razonamiento para la familia Gemini 3, prometiendo un razonamiento extenso notablemente más sólido, una comprensión multimodal mejorada y una mejor escalabilidad para aplicaciones del mundo real.
El modelo más nuevo de Google — ¿qué es Gemini 3.1 Pro?
Gemini 3.1 Pro es la primera actualización incremental en la familia Gemini 3, posicionada como un modelo de razonamiento “el más capaz” optimizado para tareas de múltiples pasos, multimodales y con agentes. Lanzado en vista previa pública a mediados de febrero de 2026 (vista previa anunciada el 19–20 de febrero de 2026), el modelo está explícitamente dirigido a escenarios que requieren cadenas de pensamiento sostenidas, uso de herramientas y comprensión de contexto largo; por ejemplo: síntesis de investigación a gran escala, agentes de ingeniería que coordinan herramientas y sistemas, y análisis multimodal de documentos que combinan texto, imágenes, audio y video.
A alto nivel, los desarrolladores describen Gemini 3.1 Pro como:
- Nativamente multimodal — capaz de aceptar y razonar sobre texto, imágenes, audio y video.
- Construido para contexto largo — soporta ventanas de contexto muy grandes adecuadas para bases de código completas, expedientes multidocumento o transcripciones largas.
- Optimizado para razonamiento confiable y flujos de trabajo con agentes, lo que significa que está ajustado para planificar, llamar herramientas y verificar resultados en tareas de múltiples pasos.
Por qué importa ahora: las organizaciones y los desarrolladores están pasando de “buenos asistentes conversacionales” a “agentes de soporte a decisiones e investigación de alto impacto” (redacción legal, síntesis de I+D, comprensión multimodal de documentos). Gemini 3.1 Pro está diseñado explícitamente para ese corredor: reducir alucinaciones, producir razonamiento trazable e integrarse con CometAPI tanto para prototipado como para producción.
¿Cuáles son los aspectos técnicos destacados y funciones de Gemini 3.1 Pro?
Multimodalidad nativa y ventanas de contexto extremas
Gemini 3.1 Pro continúa el enfoque en multimodalidad del linaje Gemini. Según la tarjeta del modelo y las notas de producto, el modelo acepta y razona sobre texto, imágenes, audio y video en la misma canalización, una capacidad que simplifica flujos de trabajo donde los tipos de datos están mezclados (p. ej., declaraciones legales con audio + transcripción + escaneos). Es notable que el modelo soporta una ventana de contexto de 1,000,000 tokens y puede producir salidas largas (las notas publicadas sitúan los límites de salida en tamaños muy grandes apropiados para tareas de formato largo). Esta escala lo hace adecuado para casos de uso como analizar repositorios de código completos, documentos de varios capítulos o transcripciones largas sin fragmentación.
“Dynamic thinking”: razonamiento mejorado y planificación paso a paso
Google describe 3.1 Pro como con “pensamiento” mejorado; es decir, mejor manejo interno de cadenas de pensamiento y selección dinámica de estrategias de razonamiento según la complejidad de la tarea. El modelo está ajustado para activar planificación explícita de múltiples pasos cuando sea necesario, y ser eficiente en tokens al hacerlo. En la práctica, esto se traduce en menos alucinaciones para problemas complejos y escalonados y una consistencia factual mejorada en pruebas de razonamiento de múltiples pasos.
Flujos de trabajo con agentes y uso de herramientas
Un enfoque de diseño clave para 3.1 Pro es el rendimiento agéntico: coordinar herramientas, invocar grounding web o búsqueda, escribir y ejecutar fragmentos de código, y verificar salidas mediante pases secundarios. Google ha integrado 3.1 Pro en productos orientados a agentes (p. ej., el entorno de desarrollo Antigravity) para permitir que los modelos ejecuten tareas que involucran editor, terminal y navegador, y registren artefactos como capturas de pantalla y grabaciones del navegador para verificar el progreso. Estas funciones apuntan a reducir la brecha entre modelos que “dan consejos” y modelos que realmente ejecutan flujos de trabajo multi-herramienta de forma confiable.
Submodos especializados (Deep Research, Deep Think)
Google empareja 3.1 Pro con “Deep Research” y hace referencia a una variante “Deep Think” próxima. Estos submodos están dirigidos, respectivamente, a tareas de investigación de alta cobertura y a profundidad de razonamiento máxima (con coste y latencia de cómputo adicionales). Están pensados para analistas, investigadores y desarrolladores que necesitan salidas más deliberadas y de mayor calidad en lugar de las respuestas más rápidas y baratas.
¿Cómo rinde Gemini 3.1 Pro en benchmarks?
Gemini 3.1 Pro logra avances sólidos sobre los resultados anteriores de Gemini 3 Pro, a menudo tomando la delantera en un conjunto amplio de medidas de razonamiento de múltiples pasos y multimodales, pero quedando por detrás de algunos competidores en tareas especializadas específicas (notablemente ciertos conjuntos avanzados de codificación o preguntas de nivel experto). En pocas palabras: mejoras amplias con ventajas puntuales de competidores en benchmarks especializados.
Principales afirmaciones de benchmarks y cifras destacadas
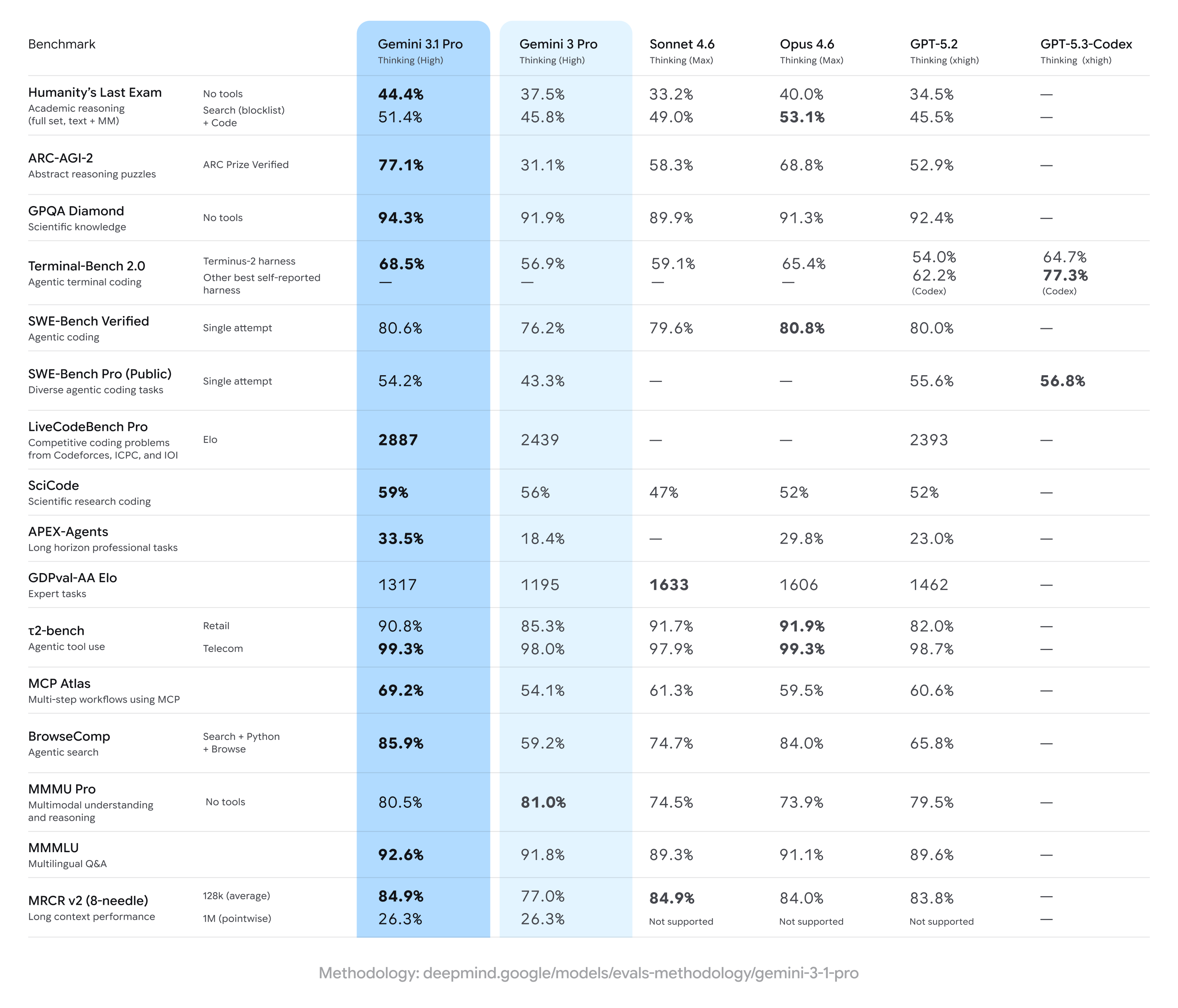
- ARC-AGI-2 (razonamiento abstracto / acertijos científicos de múltiples pasos): Los incrementos reportados para Gemini 3.1 Pro muestran una mejora sustancial respecto a versiones previas de Gemini 3 Pro; una batería de pruebas comunitarias indicó una mejora superior al doble en ARC-AGI-2 frente a la línea base anterior de Gemini 3 Pro en pruebas cortas y enfocadas. Puntuaciones específicas reportadas (pruebas comunitarias) sitúan a Gemini 3.1 Pro en ~77.1% en algunas agregaciones estilo ARC (información pública).
- GPQA Diamond y benchmarks de ciencia a nivel de posgrado: Los informes de datos indican que Gemini 3.1 Pro alcanzó récords en GPQA Diamond (un benchmark de preguntas y respuestas de ciencia a nivel de posgrado), superando modelos Gemini anteriores y estableciendo un nuevo máximo para la familia en ejecuciones independientes. Estos avances reflejan el ajuste mejorado de cadena de pensamiento y razonamiento paso a paso del modelo.
- “Humanity’s Last Exam” con herramientas habilitadas (razonamiento fundamentado multi-herramienta): En comparativas directas con Claude Opus 4.6 de Anthropic, Claude alcanzó 53.1% en este complejo benchmark con herramientas habilitadas mientras que Gemini 3.1 Pro logró 51.4% en la misma ronda de pruebas — mostrando a Gemini muy cerca pero no en la cima en ese examen multi-herramienta concreto.
- Benchmarks de programación y terminal (Terminal-Bench 2.0, SWE-Bench Pro): Los benchmarks de codificación especializados mostraron mayor divergencia. En Terminal-Bench 2.0 con arneses específicos, variantes GPT-5.3-Codex puntuaron alrededor de 77.3% frente a ~68.5% de Gemini 3.1 Pro en las mismas comparativas. En resultados públicos de SWE-Bench Pro, Gemini 3.1 Pro obtuvo ~54.2% frente a 56.8% de GPT-5.3-Codex — más cerca, pero con la familia Codex de OpenAI manteniendo ventaja en tareas de programación especializadas en esas ejecuciones.
- GDPval-AA Elo (clasificación de tareas expertas): En un ranking agregado estilo Elo para tareas de experto, variantes Claude Sonnet/Opus puntuaron más alto (p. ej., ~1606–1633 puntos) mientras que un informe público situó a Gemini 3.1 Pro en ~1317 puntos en ese mismo conjunto — indicando margen de mejora en ciertos dominios expertos estrechos.
Resultados de pruebas en el mundo real y tests prácticos
Informes prácticos de analistas muestran que Gemini 3.1 Pro destaca particularmente en:
- Resumen de contexto largo y síntesis multidocumento, donde la ventana de 1M tokens evita la fragmentación propensa a artefactos.
- Tareas de comprensión multimodal donde el grounding imagen + texto mejora la extracción factual.
- Automatización agéntica (p. ej., coordinación de cadenas de herramientas simples) — con pruebas en Antigravity demostrando que la orquestación de tareas multiagente es factible con artefactos que registran cada paso.
Dónde aún queda por detrás Gemini 3.1 Pro (lo que dicen los números)
Ningún modelo es uniformemente el mejor. Comentarios independientes y pruebas comunitarias destacan brechas específicas:
- Benchmarks de ingeniería de software y mantenimiento de código (SWE-Bench Pro y similares) — Gemini 3.1 Pro por detrás de un competidor (Claude Opus 4.6 de Anthropic) en tareas que evalúan habilidades prácticas de ingeniería de software: refactorizaciones a gran escala, triaje de bugs en bases de código desordenadas y algunos tipos de reparación automática de programas. En otras palabras, para el mantenimiento de ingeniería del día a día, modelos especializados aún conservan ventaja en ciertos bancos de pruebas.
- Microtareas sensibles a la latencia — dado que Gemini 3.1 Pro está ajustado para la profundidad, tareas que requieren ultra baja latencia y alto rendimiento (p. ej., micro-inferencia para interfaces conversacionales livianas) pueden estar mejor servidas por “Flash” u otras variantes optimizadas de la familia Gemini.
¿Cuál es el precio de Gemini 3.1 Pro?
Puedes acceder a Gemini 3.1 Pro de dos maneras — suscripción de consumidor o API para desarrolladores — y el precio difiere en cada caso.
- Consumidor (app Gemini / Google AI Pro): El acceso a Gemini 3.1 Pro está incluido en la suscripción Google AI Pro, que en EE. UU. es $19.99 / mes (Google también ofrece el nivel inferior “AI Plus” y un nivel superior “AI Ultra”). Google.
- Desarrollador / API (por tokens): Si llamas a los modelos Gemini vía la API de desarrollador de Gemini/AI, el precio se mide por tokens. Para la vista previa Gemini 3.x Pro los precios publicados para desarrolladores son aproximadamente: $2.00 por 1M tokens de entrada y $12.00 por 1M tokens de salida para la banda estándar (≤200k prompts) — con niveles superiores (p. ej., $4/$18 por 1M) para contextos muy grandes. (Consulta la tabla de precios de la API de Gemini para detalles completos y precios por lotes).
- Si usas Gemini 3.1 Pro vía CometAPI:
| Precio en Comet (USD / M tokens) | Precio oficial (USD / M tokens) |
|---|---|
| Entrada:$1.6/M; Salida:$9.6/M | Entrada:$2/M; Salida:$12/M |
Precio de suscripción del consumidor (app Gemini)
Para planes de usuario final dentro de la app Gemini, Google estructura niveles que delimitan el acceso a variantes del modelo y funciones extra: Google AI Pro y Google AI Ultra. Los precios varían por mercado y moneda; ejemplos publicados muestran Google AI Pro a $19.99/mes (con pruebas promocionales disponibles) y precios escalonados por moneda en la página de producto (incluyendo ofertas de prueba y tarifas reducidas a corto plazo). AI Ultra agrupa un acceso superior (p. ej., acceso prioritario a nuevas innovaciones, más créditos para generación de video) a una tarifa mensual más alta. Estos precios de planes para consumidores son competitivos con otras suscripciones de IA de gama alta y están orientados a dar a usuarios avanzados individuales o equipos pequeños acceso a las funciones de 3.1 Pro sin integración de API.
Consejos prácticos de prompts y uso (lo que yo haría)
Usa estos para obtener resultados confiables y repetibles:
- Planificador de pasos explícito
Prompt pattern:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Esto aprovecha la ejecución paso a paso más sólida de 3.1 Pro y te da puntos de control. - Salida estructurada con esquemas
Pide JSON con un esquema ystrict: true. Como 3.1 Pro produce salidas largas adherentes a esquemas con mayor confiabilidad, obtendrás respuestas más grandes en una sola entrega que podrás parsear aguas abajo. - Sándwich de verificación de herramientas
Al invocar herramientas externas (APIs, ejecutores de código), pide al modelo que produzca: plan → llamada exacta a la herramienta (copiable/pegable) → pasos de validación. Luego verifica los pasos de validación fuera del modelo antes de continuar. - Cuidado con la confianza de un solo paso
Aunque el modelo escriba código o comandos que parezcan perfectos, ejecuta validación independiente (tests, linters, ejecución en sandbox), especialmente para acciones agénticas/autónomas.
Práctica con Gemini 3.1 Pro
Caso de prueba 1: asistente de investigación de largo contexto (NotebookLM / Deep Research)
Objetivo: Evaluar la capacidad del modelo para sintetizar 10–50 documentos largos (p. ej., informes, whitepapers) en un resumen ejecutivo de varias páginas con citas y acciones.
Configuración: Alimenta un corpus de 200k–800k tokens; pide al modelo producir un resumen de 2–4 páginas con citas explícitas y recomendaciones de “siguientes pasos”. Usa una plantilla de prompt repetible y mide tiempo, uso de tokens (coste) y precisión fáctica.
Resultados: Mayor rapidez de extremo a extremo en la síntesis con menos artefactos de fragmentación respecto a modelos anteriores, mayor fidelidad de citas en el resumen y mejor coherencia a escala — a costa de un uso significativo de tokens (así que planifica el presupuesto). Los benchmarks y pruebas prácticas muestran que Gemini 3.1 Pro sobresale en síntesis multidocumento gracias a la ventana de 1M tokens.
Caso de prueba 2: asistente de programación agéntico (Antigravity + GitHub Copilot)
Objetivo: Medir la reducción en tiempo hasta completar tareas de desarrollador de múltiples pasos (p. ej., implementar una función en varios archivos, ejecutar pruebas, corregir pruebas fallidas).
Configuración: Usa Antigravity o GitHub Copilot en vista previa con Gemini 3.1 Pro seleccionado. Define tareas reproducibles (creación de incidencias → implementar → ejecutar pruebas), registra pasos y artefactos del agente, y compara con una línea base solo humana.
Resultados: Orquestación mejorada de tareas de múltiples pasos (registro de artefactos, sugerencia automática de candidatos a parche), mejor razonamiento multiarchivo que el Gemini 3 Pro anterior, y ahorros de tiempo medibles en trabajo rutinario de funciones. Las tareas especializadas de depuración de sistemas de bajo nivel pueden seguir favoreciendo modelos especializados con enfoque primero en código (resultados comunitarios muestran una brecha frente a algunas variantes GPT-Codex en ciertos benchmarks de terminal).
Caso de prueba 3: revisión de documentos legales/médicos multimodal
Objetivo: Usar el modelo para ingerir un corpus mixto (PDFs escaneados, imágenes, transcripciones de audio), extraer hechos clave y producir una matriz de riesgos y acciones priorizadas.
Configuración: Suministra un conjunto de datos con imágenes escaneadas y texto OCR, además de audio de soporte. Mide la precisión en extracción de entidades con nombre, la tasa de falsos positivos y la capacidad del modelo para referenciar artefactos fuente.
Resultados: Razonamiento integrado más sólido entre modalidades y salidas más trazables (capacidad de señalar la imagen / página / marca de tiempo de audio que respalda una afirmación). La ventana de contexto larga reduce la necesidad de fragmentación y referencias cruzadas manuales. Sin embargo, en dominios regulados, las salidas deben ser validadas por expertos del dominio y debe usarse una canalización de grounding/verificación.
Primeras impresiones (qué se siente diferente)
- Razonamiento paso a paso más profundo. Tareas que antes requerían múltiples idas y vueltas — p. ej., síntesis multidocumento, matemáticas/lógica de múltiples pasos — tienden a completarse en menos pasadas y con salidas tipo cadena de pensamiento más claras (sin exponer texto de instrucciones internas). Esto es el titular que Google enfatizó.
- Salidas estructuradas más largas y de mayor calidad. JSON y automatizaciones de formato largo son más consistentes y a menudo mucho más extensas (algunos usuarios reportaron tamaños de salida mucho mayores que 3.0). Eso lo hace excelente para trabajos generativos donde quieres una carga grande única. Espera manejar salidas más voluminosas y streaming.
- Manejo de tokens/contexto más eficiente. Mayor eficiencia de tokens y un comportamiento más “fundamentado y consistentemente factual” en escenarios con uso de herramientas. Se refleja en menos alucinaciones en consultas fácticas cortas.
Análisis final: ¿vale la pena adoptar Gemini 3.1 Pro ahora?
Gemini 3.1 Pro representa un avance significativo en la familia Gemini con mejoras demostrables en benchmarks de razonamiento, programación y desempeño agéntico — respaldado por la tarjeta del modelo publicada por Google y rastreadores independientes que citan saltos grandes en ciertos rankings. Para equipos que necesitan razonamiento avanzado, coordinación de herramientas agénticas o capacidades multimodales de contexto largo, 3.1 Pro es un candidato convincente.
Los desarrolladores pueden acceder a Gemini 3.1 Pro vía CometAPI ahora. Para empezar, explora las capacidades del modelo en el Playground y consulta la guía de la API para instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio mucho más bajo que el oficial para ayudarte a integrar.
¿Listo para empezar? → Regístrate en Gemini 3.1 Pro hoy
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!