

GLM-5-Turbo es un nuevo LLM fundamental de Zhipu AI, específicamente entrenado y ajustado para flujos de trabajo de estilo agente (la empresa denomina al ecosistema objetivo OpenClaw / escenarios “lobster”). Ofrece un contexto muy largo (hasta ~200K tokens), streaming y salidas estructuradas, menores tasas de error en llamadas a herramientas (reportado ~0.67% en pruebas de terceros) y un precio por token materialmente más bajo. El modelo busca intercambiar una pequeña porción del rendimiento máximo por turno único por una estabilidad mucho mejor, mayor fiabilidad en herramientas, gestión de tareas programadas/persistentes y ejecución de cadenas largas, útil para agentes autónomos, sistemas de orquestación y pipelines con múltiples herramientas.
¿Qué es GLM-5-Turbo?
GLM-5-Turbo es presentado por Zhipu como un modelo fundamental diseñado para la orquestación de agentes y flujos de trabajo automatizados complejos, más que como un modelo general de chat o multimodal. Las decisiones de diseño enfatizan:
- Entrenamiento nativo “amigable para agentes” (uso de herramientas, seguimiento de comandos, tareas temporizadas/persistentes).
- Ventanas de contexto muy grandes y amplia capacidad de salida para soportar sesiones largas, memoria y planificación de cadena de razonamiento.
- Inferencia estable y de alto rendimiento para flujos de negocio largos y tareas programadas.
A diferencia de los LLM tradicionales optimizados para chat o generación de texto, GLM-5-Turbo es:
- Con prioridad en agentes (no en chat)
- Construido para entornos OpenClaw (“lobster”)
- Diseñado para flujos de trabajo autónomos de múltiples pasos
🦞 ¿Qué significa “Lobster Agent”?
El concepto “lobster” se refiere a OpenClaw, el ecosistema de agentes de Zhipu en el que los modelos:
- Usan herramientas de forma dinámica
- Ejecutan cadenas largas de tareas
- Mantienen memoria persistente
- Operan a través de terminales, apps y APIs
GLM-5-Turbo está profundamente optimizado para este paradigma, resolviendo problemas clave de los agentes como:
- Fiabilidad en llamadas a herramientas
- Descomposición de tareas
- Planificación a largo plazo
- Estabilidad de ejecución
Funciones clave y por qué importan
Contexto largo + enorme capacidad de salida (200K / 128K)
Una ventana de contexto de 200K tokens y capacidad de salida de 128K permiten que GLM-5-Turbo:
- Mantenga memoria extendida del contexto previo (conversaciones, salidas de herramientas, resultados intermedios).
- Produzca artefactos generados muy largos (planes multi-etapa, informes extensos, bases de código) sin necesidad de coser contextos repetidamente.
- Aloje agentes de múltiples turnos que deban retener todo el historial de ejecución para tomar decisiones con precisión.
Esta es una decisión técnica deliberada para agentes: en lugar de dividir tareas en prompts cortos, los agentes pueden mantener un estado coherente a lo largo de miles de turnos o pasos.
Primitivas de agente integradas en el entrenamiento
En lugar de adaptar un modelo de propósito general a tareas de agente, GLM-5-Turbo fue entrenado con objetivos de estilo agente (p. ej., comportamiento de invocación de herramientas, análisis de comandos/argumentos). El efecto declarado es menos alucinaciones durante llamadas a herramientas, planes multi-paso más estables y mejor latencia en ejecuciones largas, todo valioso cuando la automatización debe encadenar muchas APIs externas o herramientas con fiabilidad.
Rendimiento y estabilidad de ejecución
La variante GLM-5-Turbo mejora la estabilidad de ejecución y el rendimiento para flujos de negocio largos en comparación con modelos generalistas grandes; el lenguaje de marketing enfatiza “ejecución de alto rendimiento” y “estabilidad de respuesta líder” entre modelos similares. Esto es significativo para despliegues empresariales de agentes en los que un paso fallido puede romper todo el pipeline. Los benchmarks independientes de terceros aún están emergiendo.
Datos de referencia de GLM-5-Turbo
Nota: Zhipu ha publicado evaluaciones internas y existen benchmarks de terceros/ académicos para GLM-5. GLM-5-Turbo es de lanzamiento reciente; las ejecuciones de benchmark de la comunidad independiente tardarán en aparecer. A continuación listamos las cifras publicadas más defendibles y su contexto.
GLM-5 (referencia): métricas publicadas representativas
GLM-5 de Zhipu (el buque insignia predecesor de Turbo) reporta posiciones destacadas en muchos trabajos de ingeniería/flujo de trabajo; por ejemplo:
- SWE-bench Verified: 77.8 (reportado en la documentación de GLM-5 como una puntuación líder entre modelos abiertos).
- Terminal Bench 2.0: 56.2 (reportado como el mejor rendimiento de modelos abiertos en la distribución dada).
Esos números establecen a GLM-5 como una base alta en tareas de ingeniería de software y ejecución; GLM-5-Turbo está posicionado para intercambiar algo de tamaño/parámetros brutos por mejor fiabilidad de agente y rendimiento. GLM-5-Turbo mostró ~0.67% de error en llamadas a herramientas en sus comparativas, materialmente menor que ejecuciones comparativas de proveedores de GLM-5 que oscilaron entre ~2.33% y 6.41%.
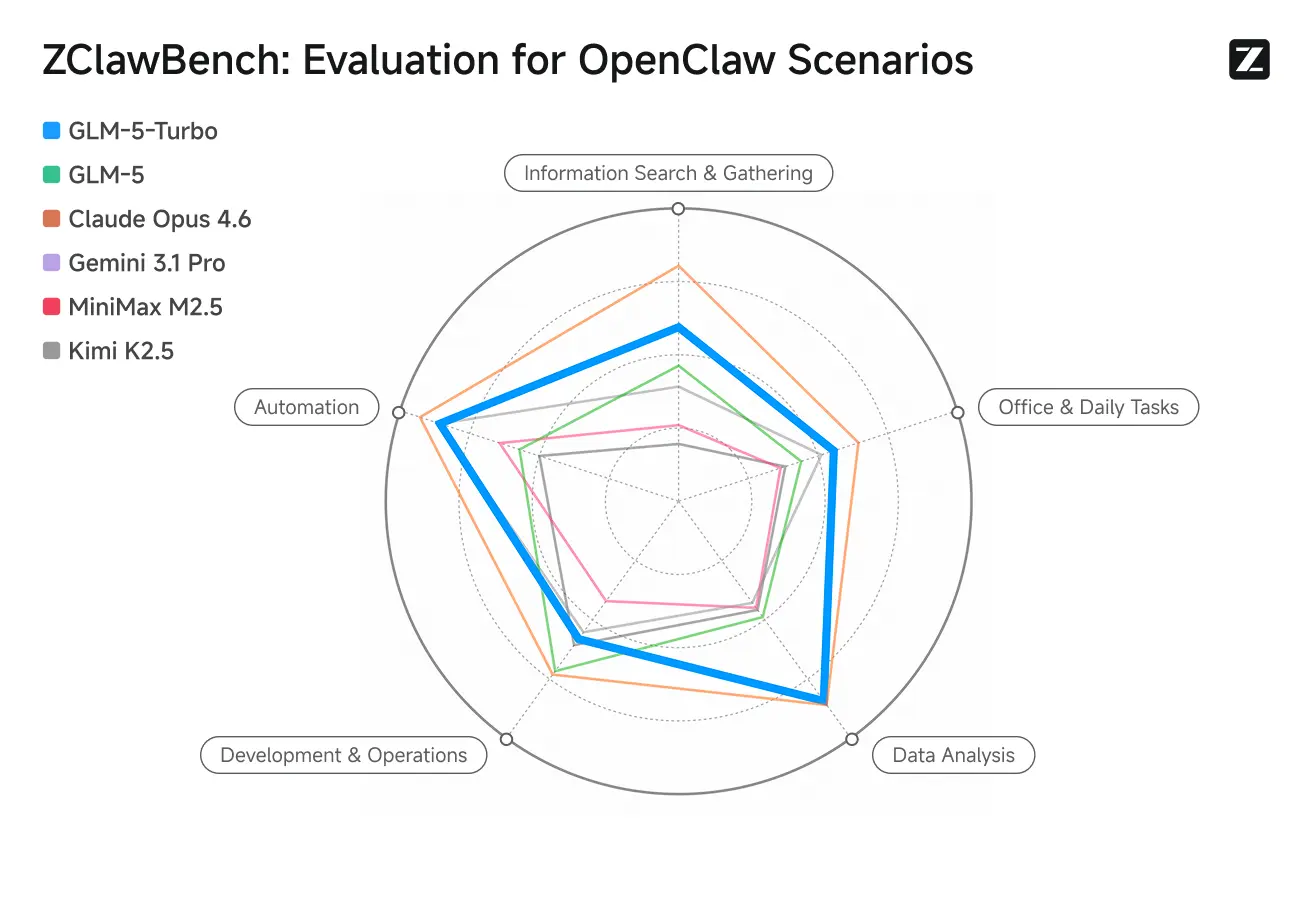
ZClawBench: Prueba de Benchmark para escenarios proxy de OpenClaw
Zhipu también lanzó el benchmark ZClawBench para evaluar agentes inteligentes. En pruebas a ciegas que cubrieron campos diversos como desarrollo de código, análisis de datos y creación de contenido, el nuevo modelo con nombre en clave Pony-Alpha-2 obtuvo el favor del 90% de los encuestados.
Precios y disponibilidad (quién lo vende y cuánto cuesta)
Zhipu implementó un aumento de precio de API de ~20% para la oferta GLM-5-Turbo en el lanzamiento e introdujo simultáneamente niveles de suscripción “Lobster Package” destinados a suavizar los precios por token para despliegues de agentes.
Niveles de suscripción reportados (paquetes de ejemplo)
Dos paquetes Lobster ilustrativos (precios son conversiones reportadas y aproximadas):
- Entry Lobster plan: ~39 CNY / mes (~US$5.66) por 35,000,000 tokens.
- Mid Lobster plan: ~99 CNY / mes (~US$14.36) por 100,000,000 tokens.
Usando esos números publicados, el costo por 1 millón de tokens es aproximadamente:
- Plan Entry: ~US$0.162 por 1M tokens.
- Plan Mid: ~US$0.144 por 1M tokens.
Esas cifras por 1M son conversiones simples del costo de suscripción publicado y el tope de tokens, y ilustran la economía para cargas de trabajo de agentes de alto volumen. (Cálculos basados en la moneda y cantidades de tokens reportadas en prensa).
Precio de API
Listado representativo de marketplace (CometAPI): US$0.96 por 1M tokens de entrada y US$3.20 por 1M tokens de salida para GLM-5-Turbo.
La página de precios para desarrolladores de Zhipu (Z.ai) lista una tarifa directa ligeramente mayor para GLM-5-Turbo: US$1.20 por 1M tokens de entrada y US$4.00 por 1M tokens de salida (las tarifas de entrada en caché son más bajas).
GLM-5-Turbo vs GLM-5 — comparación lado a lado
A alto nivel:
- GLM-5 = modelo fundamental insignia de propósito general (razonamiento, programación, benchmarks)
- GLM-5-Turbo = variante optimizada para agentes de GLM-5 (centrada en flujos largos, uso de herramientas, estabilidad)
GLM-5-Turbo no es una arquitectura de modelo completamente nueva, sino una versión especializada y optimizada para producción de GLM-5 diseñada para sistemas de agentes como OpenClaw.
Posicionamiento central
| Modelo | Posicionamiento |
|---|---|
| GLM-5 | LLM insignia de propósito general (razonamiento, código, benchmarks) |
| GLM-5-Turbo | Modelo con prioridad en agentes (automatización, orquestación, uso de herramientas) |
👉 En términos simples:
- Usa GLM-5 → cuando quieres máxima inteligencia
- Usa GLM-5-Turbo → cuando quieres automatización/ agentes estables
Comparación de capacidades de agente (LO MÁS IMPORTANTE)
GLM-5 (capacidad de agente) ya admite:
- Uso de herramientas
- Razonamiento multi-paso
- Agentes de programación
Pero con limitaciones:
- Puede perder contexto en cadenas largas
- Las llamadas a herramientas pueden degradarse con el tiempo
- Requiere más lógica de orquestación
GLM-5-Turbo está explícitamente optimizado para agentes:
Mejoras clave:
- Fiabilidad de llamadas a herramientas ↑
- Descomposición de tareas (planificación) ↑
- Consistencia en cadenas largas ↑
- Soporte de ejecución persistente ↑
Mejora de ejemplo:
- Ejecución estable a lo largo de 10+ pasos sin perder contexto
👉 Esto es crítico para:
- Sistemas estilo AutoGPT
- Flujos de trabajo multiagente
- Automatización SaaS
Velocidad y eficiencia
| Aspecto | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Velocidad de inferencia | Moderada | Más rápida |
| Rendimiento (throughput) | Estándar | Superior |
| Latencia en tareas largas | Puede degradarse | Optimizada |
GLM-5-Turbo está diseñado para solucionar un problema real de la industria:
Los modelos grandes se ralentizan o fallan durante flujos de trabajo largos
Comparación de precios
| Modelo | Entrada (US$/1M tokens) | Salida (US$/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo es más caro (~20% más)
¿Por qué más caro?
Porque ofrece:
- Mejor fiabilidad de orquestación
- Mayor estabilidad en producción
- Optimizaciones específicas para agentes
👉 En entornos empresariales:
- Pagas más por token
- Pero reduces costes de fallo + reintentos
| Atributo | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Objetivo principal | Modelo fundamental insignia (capacidades amplias, fuerte en código/benchmarks) | Modelo fundamental optimizado para agentes/“OpenClaw” / “lobster” |
| Ventana de contexto | (reportada como alta; GLM-5 se enfoca en ~200K (GLM-5 también soporta contexto largo) | 200,000 tokens (documentado). |
| Máximo de tokens de salida | (grande, depende del modelo) | 128,000 tokens (documentado). |
| Puntuaciones destacadas de benchmark | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (números reportados de GLM-5). | Evaluaciones internas afirman mayor estabilidad en cadenas largas y rendimiento para flujos de agentes; benchmarks públicos independientes pendientes. |
| Modalidades | Texto (principal), la familia GLM tiene variantes de visión en modelos hermanos | Solo texto (según docs) — optimizado para agentes basados en herramientas. |
| Casos de uso recomendados | Amplios: chat, código, razonamiento, contenido | Orquestación de agentes, invocación de herramientas, automatización a largo plazo |
| Precios | Precios existentes de GLM-5 (varían por plan) | Nuevo lanzamiento — aumento de precio de API ~20%; se introdujeron nuevos niveles de suscripción Lobster |
Cómo usar GLM-5-Turbo
CometAPI — acceso a muchos modelos con una sola API (compatible con OpenAI)
CometAPI lista GLM-5-Turbo como disponible y proporciona una URL base y SDK compatibles con OpenAI. Usa la cadena de modelo que publiquen (su sitio lista GLM-5-Turbo con precios similares). Ejemplos adaptados de la documentación de CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
El valor de CometAPI es la conveniencia como agregador (una única integración para muchos modelos). Confirma el slug exacto del modelo en el panel de CometAPI antes de llamar.
Mejores prácticas al crear agentes Lobster / OpenClaw con GLM-5-Turbo
- Diseña para la fiabilidad, no para la latencia bruta: la ventaja de Turbo es la menor tasa de fallo de llamadas a herramientas en cadenas largas. Estructura las ejecuciones del agente para preferir completados robustos (reintentos, llamadas idempotentes a herramientas) por encima de ganancias mínimas en el primer token.
- Usa streaming y llamadas a herramientas incrementales: adopta salidas en streaming/fragmentadas para reducir retrabajos y permitir invocación temprana de herramientas cuando corresponda. GLM-5-Turbo soporta streaming.
- Salidas estructuradas para parsers: prefiere JSON o resultados bien formateados para un análisis determinista por herramientas downstream. Turbo soporta salidas estructuradas.
- Planifica para la programación/persistencia: si tu agente debe comprobar periódicamente o ejecutar tareas en segundo plano, utiliza las mejores semánticas de tiempo y funciones de caché de Turbo para evitar replanificar en cada ciclo.
- Instrumenta llamadas a herramientas y planes de contingencia: registra las llamadas a herramientas y diseña alternativas elegantes (p. ej., reintentar con ligera variación de temperatura o llamar a una herramienta de respaldo), ya que los flujos de trabajo orientados a agentes son frágiles si falla una sola API externa. Turbo reduce las tasas de error, pero no elimina fallos externos.
Developers can access GLM-5 and GLM-5 turbo APIvia CometAPI now.To begin, consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
¿Listo para empezar?→ Sign up fo GLM-5 and GLM-5 turbo today !