

El 3 de marzo de 2026, Google presentó Gemini 3.1 Flash-Lite, el miembro más reciente de la familia Gemini 3 diseñado específicamente como un motor de alto caudal, baja latencia y alta eficiencia de costos para cargas de trabajo de desarrolladores y empresas. Google posiciona a Flash-Lite como el modelo “más rápido y más rentable” de la línea Gemini 3: una variante liviana que busca ofrecer interacciones en streaming, procesamiento en segundo plano a gran escala y tareas de producción de alta frecuencia (por ejemplo, traducción, extracción, generación de UI y clasificación de gran volumen) a un precio mucho más bajo que sus contrapartes Pro.
A continuación analizamos qué es Flash-Lite.
Qué es Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite es un miembro de la familia Gemini 3 que sacrifica intencionalmente parte de la máxima profundidad de razonamiento a cambio de velocidad y eficiencia de costos. Es multimodal de forma nativa dentro de la línea Gemini (capaz de aceptar texto, imágenes y otras modalidades como entrada), pero está ajustado e implementado específicamente para ofrecer el máximo rendimiento en tokens por segundo y una facturación por token sustancialmente menor en cargas de trabajo que requieren inferencias rápidas y repetidas en lugar de la máxima profundidad cognitiva. Se describe como derivado de la arquitectura 3.1 Pro, pero optimizado para caudal, latencia y costo.
Compensaciones clave de diseño
El sobrenombre "Lite" indica el énfasis de ingeniería del modelo:
- Caudal por encima del razonamiento intensivo: Flash-Lite reduce intencionalmente el cómputo por token para ofrecer un menor Time-to-First-Token (TTFT) y una velocidad de salida sostenida más alta. Eso lo hace ideal para canalizaciones en las que cada solicitud debe servirse con rapidez y a escala (p. ej., filtros de seguridad, asistentes en tiempo real, generación de alto volumen).
- Eficiencia de costos para altos volúmenes: Al reducir el cómputo por token, el modelo puede ofrecerse a precios más bajos por millón de tokens, lo que reduce el costo marginal en aplicaciones a gran escala (p. ej., de millones a miles de millones de tokens por mes). Los precios de vista previa de Google muestran una diferencia significativa frente al nivel Pro.
- Calidad ajustada para tareas pragmáticas: Según resúmenes de puntuaciones tempranas, Flash-Lite mantiene resultados sólidos en tareas de clasificación estándar, multilingües y muchas multimodales, pero no está concebido para superar a Pro en los benchmarks más complejos de razonamiento multinivel o generación de código, donde la profundidad importa.
Estas cargas de trabajo requieren salidas confiables y alto caudal, pero no siempre requieren las capacidades de razonamiento multietapa complejas de los modelos insignia.
Características clave de Gemini 3.1 Flash-Lite
1. Baja latencia y tiempo rápido hasta el primer token
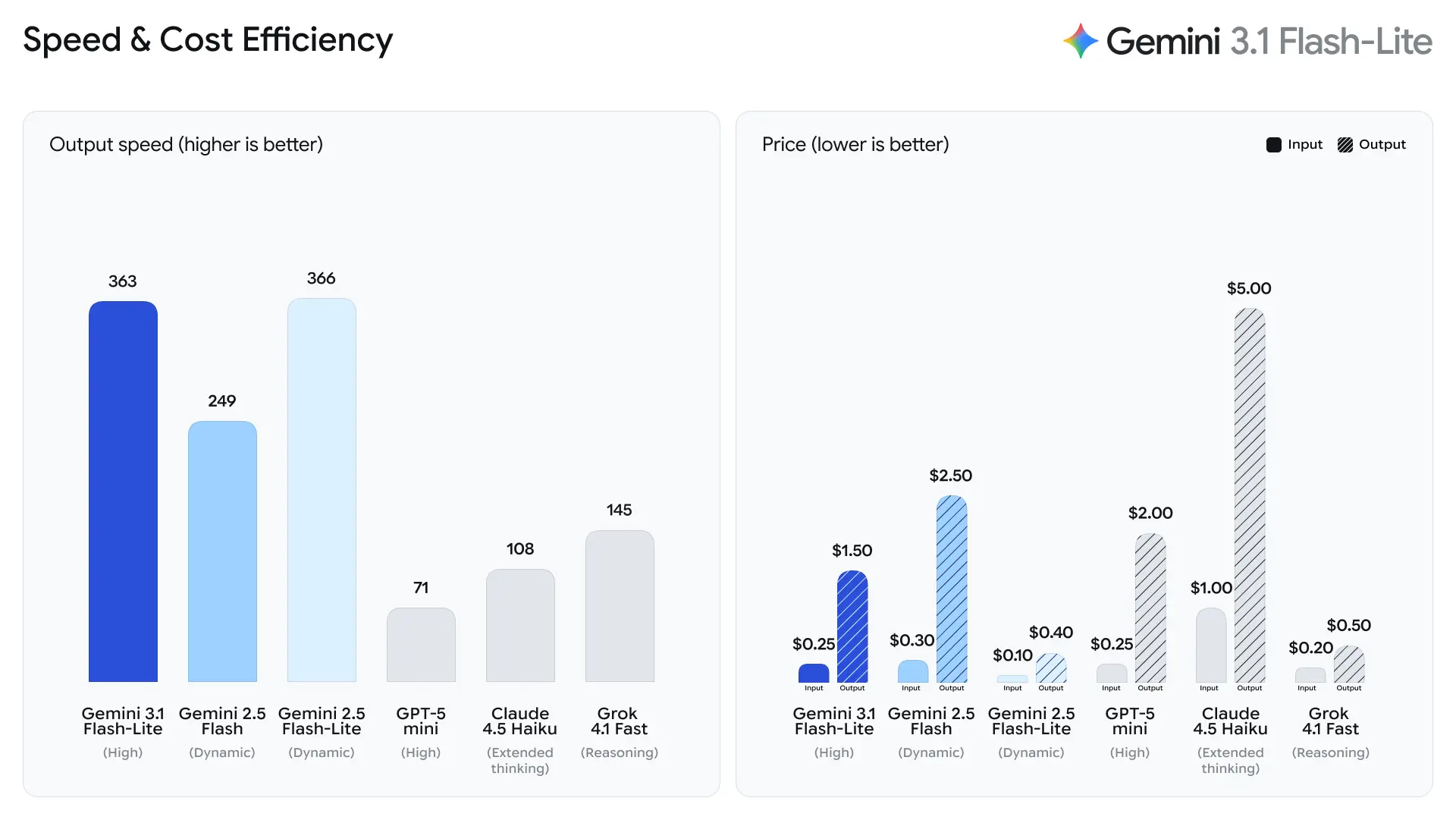
Google destaca el tiempo hasta el primer token de respuesta como métrica principal para Flash-Lite. La compañía informa ~2.5× más rápido tiempo hasta el primer token en comparación con Gemini 2.5 Flash y hasta 45% más rápida generación de salida, mejoras que impactan directamente en la sensación de respuesta para los usuarios finales y en los costos de caudal de los sistemas de back-end. Estas ganancias hacen que Flash-Lite sea muy adecuado para funciones interactivas (p. ej., chatbots integrados en apps) y canalizaciones de alto QPS donde los microsegundos importan.
Esta mejora optimiza significativamente las aplicaciones en tiempo real como:
- IA conversacional
- asistentes de búsqueda con IA
- chatbots interactivos
- servicios de traducción en tiempo real
Una menor latencia mejora la experiencia del usuario al reducir el tiempo de espera y permitir interacciones más fluidas.
2. Estructura de precios por token rentable
Los costos de inferencia de IA a menudo se calculan por token, por lo que el precio es un factor fundamental para implementaciones a gran escala.
Gemini 3.1 Flash-Lite introduce una estructura de precios altamente competitiva:
| Tipo de token | Precio |
|---|---|
| Tokens de entrada | $0.25 por 1M tokens |
| Tokens de salida | $1.50 por 1M tokens |
Esto supone una reducción respecto a modelos Flash anteriores, lo que hace que el modelo sea atractivo para organizaciones con grandes cargas de trabajo.
En comparación:
| Modelo | Precio de entrada | Precio de salida |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Esta estrategia de precios permite a los desarrolladores ejecutar IA a escala sin aumentar drásticamente los costos operativos.
Si buscas un precio aún mejor, entonces Gemini Flash-Lite ofrece un 20% de descuento en CometAPI.
3. “Niveles de pensamiento” (profundidad de inferencia controlable)
Gemini 3.1 Flash-Lite incluye la capacidad de “niveles de pensamiento”: un control configurable por el desarrollador que instruye al modelo para preferir un procesamiento más rápido y superficial en tareas triviales y un razonamiento más profundo en tareas más difíciles. Esto es importante en la práctica porque permite compensaciones dinámicas de costo/latencia por solicitud sin cambiar de modelo.
Los desarrolladores pueden configurar la profundidad de razonamiento del modelo para que coincida con la complejidad de la tarea. Niveles de pensamiento: admite cuatro niveles: Minimal, Bajo, Medio y Alto.
Este enfoque dinámico permite optimizar el uso de recursos manteniendo la calidad donde importa. La estrategia práctica es aproximadamente la siguiente:
- Minimal/Bajo: Adecuado para alta concurrencia pero tareas lógicamente simples como traducción, clasificación y análisis de sentimiento, priorizando la máxima velocidad y el costo mínimo.
- Medio: Adecuado para la mayoría de tareas de producción, equilibrando calidad y eficiencia.
- Alto: Adecuado para tareas que requieren razonamiento profundo, como generar interfaces de usuario, crear simulaciones y ejecutar instrucciones complejas.
4. Capacidad multimodal con huella ligera
Aunque Flash-Lite está optimizado para velocidad y costo, mantiene los fundamentos multimodales de la línea Gemini 3: puede aceptar entradas de imagen para clasificación o razonamiento multimodal ligero cuando el caso de uso lo requiera, pero los desarrolladores deben esperar que el diseño económico favorezca operaciones multimodales más cortas y acotadas por encima de flujos de trabajo muy grandes y cargados de imágenes. Al igual que otros modelos Gemini, Gemini 3.1 Flash-Lite admite entradas multimodales, lo que permite a los desarrolladores procesar diferentes tipos de datos.
Las entradas admitidas incluyen:
- Texto
- Imágenes
- Video
- Audio
La capacidad del modelo para analizar múltiples tipos de información habilita nuevos casos de uso, como:
- procesamiento automático de documentos
- extracción de datos visuales
- resumen de contenido multimedia
Los modelos Gemini anteriores también demostraron sólidas capacidades de razonamiento multimodal en benchmarks visuales y de conocimiento.
Indicadores de rendimiento: números reales y su significado
El anuncio y la documentación de producto de Google presentan varios datos de benchmark destinados a ayudar a los compradores a entender dónde se ubica Flash-Lite dentro del ecosistema.
Métricas de velocidad orientadas a desarrolladores
- 2.5× más rápido en tiempo hasta el primer token de respuesta vs Gemini 2.5 Flash (comparación interna declarada por Google).
- 45% más rápida generación de salida vs Gemini 2.5 Flash.
Se trata de métricas de ingeniería de rendimiento más que de calidad juzgada por humanos; reflejan mejoras en la microarquitectura de ejecución, el batching y optimizaciones de la pila de inferencia que reducen la latencia para respuestas cortas. Tiempos más rápidos del primer token reducen la latencia percibida en aplicaciones interactivas y aumentan el caudal por servidor, lo que puede disminuir el cómputo total para el mismo QPS.
Tokens por segundo (t/s) y caudal
Según los datos de prueba de Artificial Analysis, 3.1 Flash-Lite alcanzó una velocidad de salida de 388.8 tokens por segundo (la mediana de los modelos en el mismo rango de precio es de solo 96.7 tokens/segundo). Esta velocidad es de primer nivel entre los modelos de su clase.
Sin embargo, Artificial Analysis también señaló un problema: la latencia del primer token (TTFT) de 3.1 Flash-Lite es de 5.18 segundos, relativamente alta para modelos de inferencia en el mismo rango de precio (la mediana es 1.82 segundos). Además, el modelo generó 53 millones de tokens durante el proceso de evaluación, lo cual es relativamente alto en comparación con el promedio de 20 millones. Esto significa que si tu escenario es muy sensible al tiempo del primer token o tiene requisitos estrictos de concisión en la salida, puede que necesites optimizar el nivel de pensamiento y los prompts.
Puntuaciones de benchmark para razonamiento y factualidad
Google incluyó comparativas entre modelos que muestran a Gemini 3.1 Flash-Lite con un rendimiento sólido frente a pares y variantes previas de Gemini en tareas agregadas de razonamiento/factualidad:
- Puntuación Elo de Arena.ai: Gemini 3.1 Flash-Lite habría logrado un Elo de 1432 en la tabla de evaluación de Arena: un ranking compuesto cara a cara que muestra un rendimiento relativo competitivo en escenarios de confrontación directa.
- GPQA Diamond: 86.9% (una medida de robustez en preguntas y respuestas).
- MMMU Pro: 76.8% (una métrica multimodal/multitarea usada interna/externamente por algunos laboratorios).
- LiveCodeBench (capacidad de programación): 72.0%
- CharXiv Reasoning (razonamiento gráfico): 73.2%
- Video-MMMU (comprensión de video): 84.8%
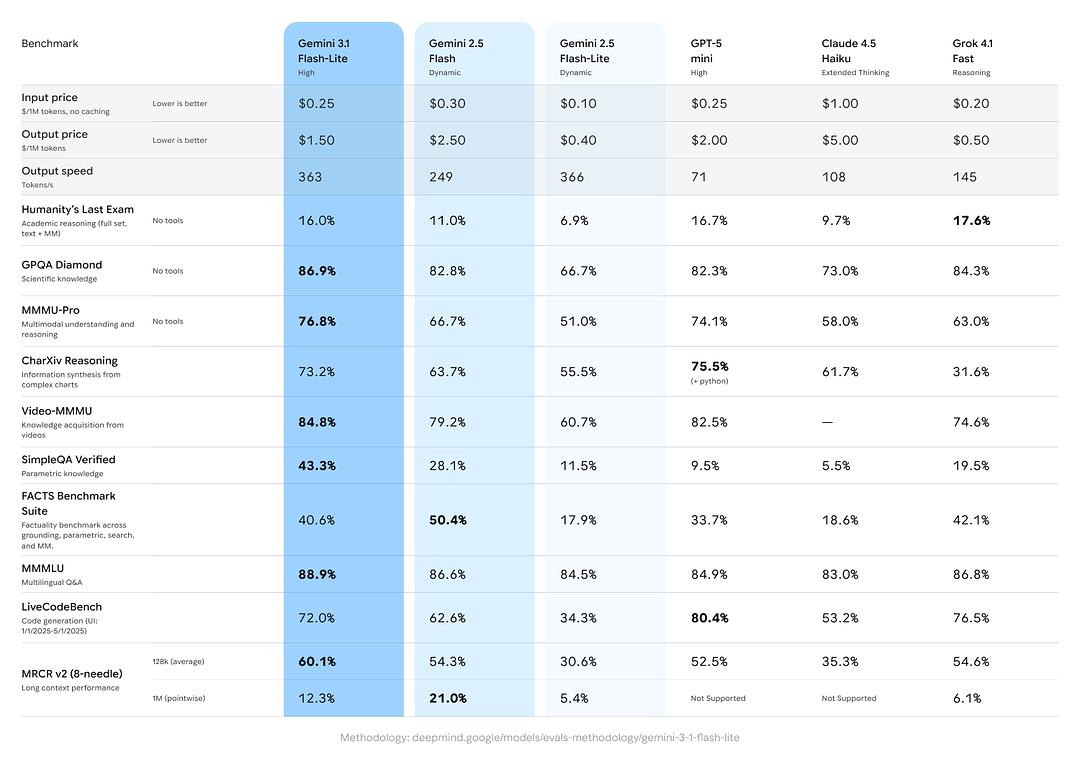
Gemini 3.1 Flash-Lite supera al antiguo Gemini 2.5 Flash en varias de estas métricas mientras ofrece una velocidad/costo muy superior.
Casos de uso que encajan con Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite está diseñado en torno a un conjunto claro de cargas de trabajo prácticas donde el alto caudal y el menor costo por token son determinantes:
Agentes conversacionales de alta frecuencia y UI en streaming
Los chatbots en tiempo real, las transmisiones de transcripción + traducción en vivo y las UIs colaborativas que muestran respuestas parciales a medida que el modelo genera se benefician de la salida de tokens en streaming y del bajo tiempo hasta el primer token de Flash-Lite.
Procesamiento de datos a granel (RAG, canalizaciones de transformación)
Ingesta masiva de documentos: extracción de entidades, etiquetado de metadatos, clasificación y tareas de traducción realizadas sobre millones de documentos — Gemini 3.1 Flash-Lite reduce el costo de inferencia a la vez que proporciona una precisión aceptable para salidas con plantillas o guiadas por reglas.
Procesamiento estilo edge o en segundo plano
Cargas de trabajo que procesan telemetría entrante o datos no estructurados de manera continua (p. ej., canalizaciones de clasificación para moderación de contenido, generación automática de informes) son buenos encajes porque Gemini 3.1 Flash-Lite minimiza el costo por unidad.
Herramientas para desarrolladores y autocompletado de código por lotes
Para funciones como el andamiaje multiarchivo, el linting de código a gran escala y la generación de plantillas a escala, las ventajas de velocidad de Gemini 3.1 Flash-Lite reducen la latencia y el costo para herramientas de experiencia de desarrollador donde no se requiere la máxima profundidad de razonamiento.
Comparación de Gemini 3.1 Flash-Lite con otros modelos Gemini y competidores
Dentro de la familia Gemini
- Gemini 3.1 Pro: máxima capacidad en razonamiento complejo y planificación multietapa; notablemente más costoso y lento por token, pero mejor para tareas profundas y matizadas.
- Gemini 3.1 Flash (no Lite): apunta a un punto intermedio entre caudal bruto y capacidad—Flash-Lite optimiza aún más la pila de cómputo para caudal.
Frente a modelos “rápidos” competidores
Gemini 3.1 Flash-Lite iguala o supera a varios modelos rápidos/mini en muchas métricas de caudal y calidad — aunque analistas independientes advierten que las comparaciones directas son sensibles a la metodología de evaluación y a la selección de datasets. Espera que Gemini 3.1 Flash-Lite sea altamente competitivo en caudal y costo mientras se mantiene cerca de la mitad de la tabla en las métricas más altas de razonamiento.
Conclusión: dónde encaja Flash-Lite en la pila de IA
Gemini 3.1 Flash-Lite es una oferta diseñada deliberadamente: un miembro eficiente y enfocado en el caudal dentro de la familia Gemini 3 que permite a los equipos intercambiar cómputo por ejemplo a cambio de mejoras drásticas en latencia y costo. Para empresas y desarrolladores que construyen canalizaciones de alto volumen — traducciones, procesamiento por lotes, UIs en streaming y tareas agenticas de complejidad moderada — Flash-Lite representa un motor base sensato. Para organizaciones que requieren la máxima fidelidad de razonamiento, los modelos Pro siguen siendo la elección adecuada.
Si tu carga de trabajo está dominada por muchas inferencias cortas y repetibles o necesitas salida en streaming rápida a gran escala, vale la pena hacer una prueba piloto con Flash-Lite. Si tu carga depende de razonamiento profundo multihop, planifica un enfoque híbrido: enruta el tráfico de caudal a Flash-Lite y deriva las consultas complejas y de alto valor a los modelos Pro.
Los desarrolladores pueden acceder a Gemini 3.1 Flash Lite a través de CometAPI ahora. Para comenzar, explora las capacidades del modelo en el Playground y consulta la guía de la API para obtener instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y de haber obtenido la clave de API. CometAPI ofrece un precio muy inferior al oficial para ayudarte con la integración.
¿Listo para empezar?→ Regístrate para Gemini 3.1 Flash-Lite hoy
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!