

a 15 de diciembre de 2025 los hechos públicos muestran que la versión preliminar de Google’s Gemini 3 Pro (preview) y OpenAI’s GPT-5.2 marcan nuevas fronteras en razonamiento, multimodalidad y trabajo con contexto largo, pero adoptan rutas de ingeniería diferentes (Gemini → MoE disperso + contexto enorme; GPT-5.2 → diseños densos/“routing”, compactación y modos de razonamiento x-high) y por tanto intercambian victorias máximas en benchmarks frente a previsibilidad de ingeniería, herramientas y ecosistema. Cuál es “mejor” depende de tu necesidad principal: las aplicaciones multimodales basadas en agentes con contexto extremo se inclinan por Gemini 3 Pro; herramientas de desarrollo empresariales estables, costos predecibles y disponibilidad inmediata de API favorecen GPT-5.2.
¿Qué es GPT-5.2 y cuáles son sus principales características?
GPT-5.2 es el lanzamiento del 11 de diciembre de 2025 de OpenAI en la familia GPT-5 (variantes: Instant, Thinking, Pro). Se posiciona como el modelo más capaz de la empresa para el “trabajo profesional del conocimiento”: optimizado para hojas de cálculo, presentaciones, razonamiento con contexto largo, llamadas a herramientas, generación de código y tareas de visión. OpenAI puso GPT-5.2 a disposición de usuarios pagos de ChatGPT y vía la API de OpenAI (Responses API / Chat Completions) bajo nombres de modelo como gpt-5.2, gpt-5.2-chat-latest y gpt-5.2-pro.
Variantes del modelo y uso previsto
- gpt-5.2 / GPT-5.2 (Thinking) — el mejor para razonamiento complejo y de múltiples pasos (la variante por defecto “Thinking” usada en Responses API).
- gpt-5.2-chat-latest / Instant — menor latencia para uso diario de asistente y chat.
- gpt-5.2-pro / Pro — máxima fidelidad/fiabilidad para los problemas más difíciles (cómputo extra, admite
reasoning_effort: "xhigh").
Características técnicas clave (de cara al usuario)
- Mejoras en visión y multimodalidad — mejor razonamiento espacial sobre imágenes y comprensión de video mejorada cuando se combina con herramientas de código (herramienta de Python), además de compatibilidad con herramientas estilo intérprete de código para ejecutar fragmentos.
- Esfuerzo de razonamiento configurable (
reasoning_effort: none|minimal|low|medium|high|xhigh) para intercambiar latencia/costo por profundidad.xhighes nuevo en GPT-5.2 (y está disponible en Pro). - Mejor gestión de contexto largo y funciones de compactación para razonar a través de cientos de miles de tokens (OpenAI reporta métricas sólidas en MRCRv2 / métricas de contexto largo).
- Llamadas avanzadas a herramientas y flujos de trabajo basados en agentes — coordinación multi-turn más sólida, mejor orquestación de herramientas en una arquitectura de “mega-agente único” (OpenAI destaca el rendimiento en herramientas de Tau2-bench).
¿Qué es Gemini 3 Pro Preview?
Gemini 3 Pro Preview es el modelo de IA generativa más avanzado de Google, lanzado como parte de la familia Gemini 3 en noviembre de 2025. El modelo se construyó con énfasis en la comprensión multimodal: capaz de comprender y sintetizar texto, imágenes, video y audio, y cuenta con una gran ventana de contexto (~1 millón de tokens) para manejar documentos o bases de código extensos.
Google posiciona Gemini 3 Pro como líder de vanguardia en profundidad y matiz del razonamiento, y sirve como motor central de múltiples herramientas para desarrolladores y empresas, incluidas Google AI Studio, Vertex AI y plataformas de desarrollo basadas en agentes como Google Antigravity.
Por ahora, Gemini 3 Pro está en vista previa —lo que significa que la funcionalidad y el acceso aún se están ampliando, pero el modelo ya obtiene altas puntuaciones en lógica, comprensión multimodal y flujos de trabajo basados en agentes.
Características técnicas y de producto clave
- Ventana de contexto: Gemini 3 Pro Preview admite una entrada de contexto de 1,000,000 tokens (y hasta 64k tokens de salida), lo que es una ventaja práctica importante para ingerir documentos extremadamente grandes o transcripciones de video en una sola solicitud.
- Características de API: parámetro
thinking_level(low/high) para intercambiar latencia y profundidad de razonamiento; configuracionesmedia_resolutionpara controlar la fidelidad multimodal y el uso de tokens; se admiten grounding de búsqueda, contexto de archivos/URL, ejecución de código y llamadas a funciones. Thought signatures y el almacenamiento en caché de contexto ayudan a mantener el estado en flujos de trabajo de múltiples llamadas. - Modo Deep Think / razonamiento superior: una opción “Deep Think” ofrece un pase adicional de razonamiento para impulsar las puntuaciones en benchmarks difíciles. Google publica Deep Think como una vía de alto rendimiento separada para problemas complejos.
- Compatibilidad multimodal nativa: Entradas de texto, imagen, audio y video con grounding estrecho para búsqueda e integraciones de producto (se destacan las puntuaciones en Video-MMMU y otros benchmarks multimodales).
Vista rápida — GPT-5.2 vs Gemini 3 Pro
Tabla comparativa compacta con los hechos más importantes (fuentes citadas).
| Aspecto | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| Proveedor / posicionamiento | OpenAI — actualización insignia de GPT-5.x centrada en trabajo profesional del conocimiento, programación y flujos basados en agentes. | Google DeepMind / Google AI — generación insignia de Gemini centrada en razonamiento multimodal de contexto ultralargo e integración de herramientas. |
| Principales variantes del modelo | Instant, Thinking, Pro (y conmutación automática entre ellas). Pro añade mayor esfuerzo de razonamiento. | Familia Gemini 3 que incluye Gemini 3 Pro y modos Deep-Think; enfoque multimodal / basado en agentes. |
| Ventana de contexto (entrada / salida) | ~400,000 tokens de capacidad total de entrada; hasta 128,000 tokens de salida / razonamiento (diseñado para documentos y bases de código muy largos). | Hasta ~1,000,000 tokens de entrada/ventana de contexto (1M) con salidas de hasta 64K tokens |
| Fortalezas clave / enfoque | Razonamiento con contexto largo, llamadas a herramientas basadas en agentes, programación, tareas estructuradas de oficina (hojas de cálculo, presentaciones); actualizaciones de seguridad/system card enfatizan la fiabilidad. | Comprensión multimodal a escala, razonamiento + composición de imágenes, edición de imágenes con múltiples referencias y renderizado de texto legible. |
| Capacidades multimodales y de imagen | Mejor grounding de visión y multimodal; ajustado para uso de herramientas y análisis de documentos. | Generación de imágenes de alta fidelidad + composición con razonamiento, edición de imágenes con múltiples referencias y renderizado de texto legible. |
| Latencia / interactividad | El proveedor enfatiza inferencia más rápida y mayor capacidad de respuesta (menor latencia que modelos GPT-5.x previos); múltiples niveles (Instant / Thinking / Pro). | Google enfatiza “Flash”/serving optimizados y velocidades interactivas comparables para muchos flujos; el modo Deep Think intercambia latencia por razonamiento más profundo. |
| Características destacadas / diferenciadores | Niveles de esfuerzo de razonamiento (medium/high/xhigh), mejor llamada a herramientas, generación de código de alta calidad, alta eficiencia de tokens para flujos empresariales. | Contexto de 1M tokens, ingesta multimodal nativa potente (vídeo/audio), modo de razonamiento “Deep Think”, integraciones estrechas con productos de Google (Docs/Drive/NotebookLM). |
| Usos típicos recomendados (breve) | Análisis de documentos largos, flujos basados en agentes, proyectos de programación complejos, automatización empresarial (hojas de cálculo/informes). | Proyectos multimodales extremadamente grandes, flujos basados en agentes de horizonte largo que necesitan contexto de 1M tokens, canalizaciones avanzadas de imagen + razonamiento. |
¿Cómo se comparan arquitectónicamente GPT-5.2 y Gemini 3 Pro?
Arquitectura principal
- Benchmarks / evaluaciones de trabajo real: GPT-5.2 Thinking logró 70.9% de victorias/empates en GDPval (evaluación de trabajo del conocimiento en 44 ocupaciones) y grandes avances en ingeniería y matemáticas frente a variantes GPT-5 anteriores. Mejoras importantes en programación (SWE-Bench Pro) y QA científica de dominio (GPQA Diamond).
- Herramientas y agentes: Sólida compatibilidad integrada para llamadas a herramientas, ejecución en Python y flujos de trabajo basados en agentes (búsqueda de documentos, análisis de archivos, agentes de ciencia de datos). 11x velocidad / <1% de costo frente a expertos humanos para algunas tareas de GDPval (medida del valor económico potencial, 70.9% vs. ~38.8% previo), y muestra mejoras concretas en modelado de hojas de cálculo (p. ej., +9.3% en una tarea de banca de inversión junior vs GPT-5.1).
- Gemini 3 Pro: Transformer con Mezcla de Expertos dispersa (MoE). El modelo activa un pequeño conjunto de expertos por token, habilitando una capacidad total de parámetros extremadamente grande con cómputo sublineal por token. Google publica una tarjeta del modelo aclarando que el diseño de MoE disperso es un contribuyente clave al perfil de rendimiento mejorado. Esta arquitectura hace factible impulsar la capacidad del modelo mucho más alto sin costo de inferencia lineal.
- GPT-5.2 (OpenAI): OpenAI continúa usando arquitecturas basadas en Transformer con estrategias de routing/compactación en la familia GPT-5 (un “router” activa diferentes modos — Instant vs Thinking — y la empresa documenta técnicas de compactación y gestión de tokens para contextos largos). GPT-5.2 enfatiza el entrenamiento y la evaluación para “pensar antes de responder” y la compactación para tareas de horizonte largo en lugar de anunciar un MoE disperso clásico a escala.
Implicaciones de las arquitecturas
- Intercambios de latencia y costo: Modelos MoE como Gemini 3 Pro pueden ofrecer mayor capacidad máxima por token manteniendo el costo de inferencia más bajo en muchas tareas porque solo se ejecuta un subconjunto de expertos. Sin embargo, pueden añadir complejidad en la prestación del servicio y la planificación (equilibrado de expertos en arranque en frío, E/S). El enfoque de GPT-5.2 (denso/enrutado con compactación) favorece latencia predecible y ergonomía para desarrolladores, especialmente cuando se integra en herramientas establecidas de OpenAI como Responses, Realtime, Assistants y APIs por lotes.
- Escalado de contexto largo: La capacidad de entrada de 1M tokens de Gemini permite alimentar documentos extremadamente largos y flujos multimodales de forma nativa. El contexto combinado de GPT-5.2 de ~400k (entrada+salida) sigue siendo enorme y cubre la mayoría de necesidades empresariales, pero es menor que la especificación de 1M de Gemini. Para corpus muy grandes o transcripciones de vídeo de varias horas, la especificación de Gemini da una ventaja técnica clara.
Herramientas, agentes e infraestructura multimodal
- OpenAI: integración profunda para llamadas a herramientas, ejecución en Python, modos de razonamiento “Pro” y ecosistemas de agentes de pago (Agentes de ChatGPT / integraciones de herramientas empresariales). Fuerte enfoque en flujos centrados en código y generación de hojas de cálculo/diapositivas como salidas de primera clase.
- Google / Gemini: grounding integrado con Google Search (función opcional con facturación), ejecución de código, contexto de URL y archivos, y controles explícitos de resolución de medios para intercambiar tokens por fidelidad visual. La API ofrece
thinking_levely otros controles para ajustar costo/latencia/calidad.
¿Cómo se comparan los números de benchmark?
Ventanas de contexto y manejo de tokens
- Gemini 3 Pro Preview: 1,000,000 tokens de entrada / 64k tokens de salida (tarjeta del modelo de la vista previa Pro). Fecha de corte de conocimiento: enero de 2025 (Google).
- GPT-5.2: OpenAI demuestra un sólido rendimiento en contexto largo (puntuaciones MRCRv2 en tareas de “needle” de 4k–256k con rangos >85–95% en muchos ajustes) y usa funciones de compactación; los ejemplos públicos de contexto de OpenAI indican rendimiento robusto incluso en contextos muy grandes, pero OpenAI lista ventanas específicas por variante (y enfatiza la compactación en lugar de un único número de 1M). Para uso de API, los nombres de modelo son
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Razonamiento y benchmarks agénticos
- OpenAI (selección): Tau2-bench Telecom 98.7% (GPT-5.2 Thinking), grandes ganancias en uso de herramientas multietapa y tareas agénticas (OpenAI destaca colapsar sistemas multiagente en un “mega-agente”). GPQA Diamond y ARC-AGI mostraron incrementos respecto a GPT-5.1.
- Google (selección): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87.6%, GPQA alto y puntuaciones en Humanity’s Last Exam; Google también demuestra planificación de horizonte largo mediante ejemplos agénticos.
Herramientas y agentes:
GPT-5.2: Sólida compatibilidad integrada para llamadas a herramientas, ejecución en Python y flujos de trabajo basados en agentes (búsqueda de documentos, análisis de archivos, agentes de ciencia de datos). 11x velocidad / <1% de costo frente a expertos humanos para algunas tareas de GDPval (medida del valor económico potencial, 70.9% vs. ~38.8% previo), y muestra mejoras concretas en modelado de hojas de cálculo (p. ej., +9.3% en una tarea de banca de inversión junior vs GPT-5.1).
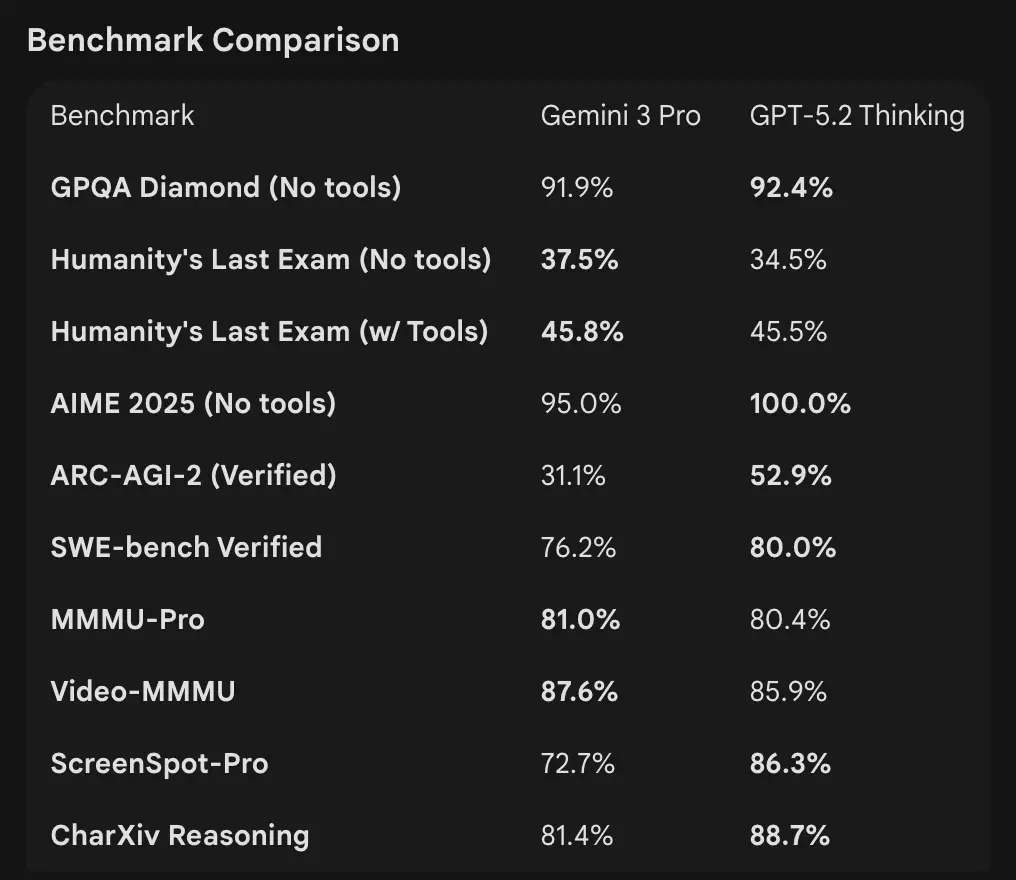
Interpretación: los benchmarks son complementarios: OpenAI enfatiza benchmarks de trabajo del conocimiento del mundo real (GDPval) que muestran que GPT-5.2 sobresale en tareas de producción como hojas de cálculo, diapositivas y secuencias agénticas largas. Google enfatiza tablas de clasificación de razonamiento puro y ventanas de contexto de una sola solicitud extremadamente grandes. Qué importa más depende de tu carga de trabajo: canalizaciones empresariales agénticas y de documentos largos favorecen el rendimiento probado de GPT-5.2 en GDPval; la ingesta de contexto masivo (p. ej., corpus de video completos / libros enteros en una pasada) favorece la entrada de 1M de Gemini.
¿Cómo se comparan las capacidades multimodales?
Entradas y salidas
- Gemini 3 Pro Preview: admite entradas de texto, imagen, video, audio, PDF y salidas de texto; Google proporciona controles granulares de
media_resolutiony un parámetrothinking_levelpara ajustar costo vs. fidelidad en trabajos multimodales. Límite de salida de 64k tokens; entrada hasta 1M tokens. - GPT-5.2: admite flujos ricos de visión y multimodalidad; OpenAI destaca el mejor razonamiento espacial (componentes de imagen con estimación de etiquetas de bounding), comprensión de video (puntuaciones Video MMMU) y visión habilitada por herramientas (la herramienta de Python en tareas de visión mejora las puntuaciones). GPT-5.2 enfatiza que tareas complejas de visión + código se benefician mucho cuando se habilita el soporte de herramientas (ejecución de código Python).
Diferencias prácticas
Granularidad vs. amplitud: Gemini expone un conjunto de controles multimodales (media_resolution, thinking_level) orientados a permitir que los desarrolladores ajusten los intercambios por tipo de medio. GPT-5.2 enfatiza el uso integrado de herramientas (ejecutar Python en el loop) para combinar visión, código y tareas de transformación de datos. Si tu caso de uso implica análisis intensivo de video + imagen con contextos extremadamente grandes, la afirmación de 1M de Gemini es convincente; si tus flujos requieren ejecutar código en el loop (transformaciones de datos, generación de hojas de cálculo), el tooling de código y la afinidad con agentes de GPT-5.2 puede resultar más conveniente.
¿Qué hay de acceso a API, SDKs y precios?
OpenAI GPT-5.2 (API y precios)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-provía Responses API / Chat Completions. SDKs establecidos (Python/JS), guías “cookbook” y un ecosistema maduro. - Precios (público): $1.75 / 1M tokens de entrada y $14 / 1M tokens de salida; los descuentos por caché (90% para entradas en caché) reducen el costo efectivo para datos repetidos. OpenAI enfatiza la eficiencia por token (precio por token más alto pero menor costo total para alcanzar un umbral de calidad).
Gemini 3 Pro Preview (API y precios)
- API:
gemini-3-pro-previewvía Google GenAI SDK y endpoints Vertex AI/GenerativeLanguage. Nuevos parámetros (thinking_level,media_resolution) e integración con groundings de Google y herramientas. - Precios (vista previa pública): Aproximadamente $2 / 1M tokens de entrada y $12 / 1M tokens de salida para niveles de vista previa por debajo de 200k tokens; pueden aplicarse cargos adicionales por Search grounding, Maps u otros servicios de Google (la facturación de Search grounding comienza el 5 de enero de 2026).
Usa GPT-5.2 y Gemini 3 vía CometAPI
CometAPI es una API de gateway/aggregator: un único endpoint REST estilo OpenAI que te da acceso unificado a cientos de modelos de muchos proveedores (LLMs, modelos de imagen/video, embeddings, etc.). En lugar de integrar muchos SDKs de proveedores, CometAPI permite llamar endpoints con formato OpenAI conocidos (chat/completions/embeddings/images) mientras cambias de modelo o proveedor por debajo.
Los desarrolladores pueden disfrutar de modelos insignia de dos compañías diferentes simultáneamente vía CometAPI sin cambiar de proveedor, y los precios de la API son más asequibles, normalmente con un 20% de descuento.
Ejemplo: fragmentos rápidos de API (copiar y pegar para probar)
A continuación se muestran ejemplos mínimos que puedes ejecutar. Reflejan las guías rápidas publicadas por los proveedores (OpenAI Responses API + Google GenAI client). Sustituye $OPENAI_API_KEY / $GEMINI_API_KEY por tus llaves.
GPT-5.2 — Python (OpenAI Responses API, razonamiento establecido en xhigh para problemas difíciles)
# Python (requiere el SDK de openai que soporte Responses API)
from openai import OpenAI
client = OpenAI(api_key="YOUR_OPENAI_API_KEY")
resp = client.responses.create(
model="gpt-5.2-pro", # gpt-5.2 o gpt-5.2-pro
input="Resume este informe empresarial de 50k tokens y genera un esquema de presentación de 10 diapositivas con notas del orador.",
reasoning={"effort": "xhigh"}, # razonamiento más profundo
max_output_tokens=4000
)
print(resp.output_text) # o inspecciona resp para obtener salidas estructuradas / tokens
Notas: reasoning.effort te permite intercambiar costo vs. profundidad. Usa gpt-5.2-chat-latest para estilo de chat Instant. La documentación de OpenAI muestra ejemplos para responses.create.
GPT-5.2 — curl (simple)
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5.2",
"input": "Escribe una función de Python que convierta un PDF con tablas en un CSV normalizado con columnas tipadas.",
"reasoning": {"effort":"high"}
}'
(Inspecciona el JSON para output_text o salidas estructuradas.)
Gemini 3 Pro Preview — Python (Google GenAI client)
# Python (cliente google genai) — ejemplo de la documentación de Google
from google import genai
client = genai.Client(api_key="YOUR_GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents="Encuentra la condición de carrera en este fragmento de C++ multihilo: <pega el código aquí>",
config={
"thinkingConfig": {"thinking_level": "high"}
}
)
print(response.text)
Notas: thinking_level controla la deliberación interna del modelo; media_resolution se puede configurar para imágenes/videos. Los ejemplos de REST y JS están en la guía para desarrolladores de Gemini de Google.
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explica la condición de carrera en este código C++: ..."}]
}],
"generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}}
}'
La documentación de Google incluye ejemplos multimodales (datos de imagen inline, media_resolution).
¿Qué modelo es “mejor”? — guía práctica
No hay un “ganador” único; en su lugar elige según caso de uso y restricciones. A continuación, una matriz de decisión breve.
Elige GPT-5.2 si:
- Necesitas integración estrecha con herramientas de ejecución de código (ecosistema de intérprete/herramientas de OpenAI) para canalizaciones programáticas de datos, generación de hojas de cálculo o flujos de trabajo de código basados en agentes. OpenAI destaca mejoras en la herramienta de Python y uso de mega-agente.
- Das prioridad a la eficiencia de tokens según lo que afirma el proveedor y quieres precios por token explícitos y predecibles de OpenAI con grandes descuentos para entradas en caché (ayuda en flujos por lotes/producción).
- Quieres el ecosistema de OpenAI (integración con el producto ChatGPT, alianzas con Azure / Microsoft y herramientas alrededor de Responses API y Codex).
Elige Gemini 3 Pro si:
- Necesitas entrada multimodal extrema (video + imágenes + audio + pdfs) y quieres un solo modelo que acepte de forma nativa todas estas entradas con una ventana de entrada de 1,000,000 tokens. Google lo comercializa explícitamente para videos largos, canalizaciones de documentos grandes + video y casos de uso interactivos de Search/AI Mode.
- Estás construyendo sobre Google Cloud / Vertex AI y quieres una integración estrecha con el grounding de Google Search, aprovisionamiento en Vertex y las APIs del cliente GenAI. Te beneficiarás de las integraciones de productos de Google (Search AI Mode, AI Studio, herramientas de agentes Antigravity).
Conclusión: ¿Cuál es mejor en 2026?
En el “cara a cara” GPT-5.2 vs. Gemini 3 Pro Preview, la respuesta es dependiente del contexto:
- GPT-5.2 lidera en trabajo profesional del conocimiento, profundidad analítica y flujos estructurados.
- Gemini 3 Pro Preview sobresale en comprensión multimodal, ecosistemas integrados y tareas de gran contexto.
Ningún modelo es universalmente “mejor”; sus fortalezas complementan demandas reales diferentes. Los adoptantes inteligentes deben ajustar la elección del modelo al caso de uso específico, restricciones de presupuesto y alineación de ecosistema.
Lo claro en 2026 es que la frontera de la IA ha avanzado significativamente, y tanto GPT-5.2 como Gemini 3 Pro están empujando los límites de lo que los sistemas inteligentes pueden lograr en la empresa y más allá.
Si quieres probar de inmediato, explora las capacidades de GPT-5.2 y Gemini 3 Pro de CometAPI en el Playground y consulta la guía de API para instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para empezar?→ Prueba gratuita de GPT-5.2 y Gemini 3 Pro !
If you want to