

El nombre en clave GPT-5.3“Garlic” se describe en filtraciones y reportes como la próxima versión incremental/iterativa de GPT-5.x, destinada a cerrar brechas en razonamiento, codificación y rendimiento de producto para OpenAI en respuesta a la presión competitiva de Gemini de Google y Claude de Anthropic.
OpenAI está experimentando con una iteración GPT-5.x más densa y eficiente, enfocada en un razonamiento más sólido, inferencia más rápida y flujos de trabajo de contexto más largo, en lugar de aumentar puramente el conteo de parámetros. No es solo otra iteración de la serie Generative Pre-trained Transformer; es una contraofensiva estratégica. Nacida de un "Código Rojo" interno declarado por el CEO Sam Altman en diciembre de 2025, "Garlic" representa un rechazo del dogma de "más grande es mejor" que ha gobernado el desarrollo de LLM durante medio decenio. En su lugar, apuesta todo por una nueva métrica: la densidad cognitiva.
¿Qué es GPT-5.3 “Garlic”?
GPT-5.3 — con nombre en clave “Garlic” — está siendo descrito como el siguiente paso iterativo en la familia GPT-5 de OpenAI. Las fuentes que enmarcan la filtración sitúan a Garlic no como un simple checkpoint o ajuste de tokens, sino como un refinamiento dirigido de arquitectura y entrenamiento: el objetivo es extraer mayor rendimiento en razonamiento, mejor planificación multietapa e interfaz mejorada con contextos largos a partir de un modelo más compacto y eficiente en inferencia, en lugar de depender únicamente de la escala bruta. Ese encuadre se alinea con las tendencias más amplias de la industria hacia diseños de modelos “densos” o de “alta eficiencia”.
El apodo "Garlic"—una desviación marcada de los nombres en clave celestiales (Orion) o botánico-dulces (Strawberry) del pasado—es, según se informa, una metáfora interna deliberada. Así como un solo diente de ajo puede dar sabor a todo un plato de manera más potente que ingredientes más grandes y sosos, este modelo está diseñado para proporcionar inteligencia concentrada sin la enorme sobrecarga computacional de los gigantes de la industria.
El origen del “Código Rojo”
La existencia de Garlic no puede desligarse de la crisis existencial que lo engendró. A finales de 2025, OpenAI se encontró en una "posición defensiva" por primera vez desde el lanzamiento de ChatGPT. Gemini 3 de Google se había coronado en los benchmarks multimodales, y Claude Opus 4.5 de Anthropic se convirtió en el estándar de facto para codificación compleja y flujos de trabajo agentivos. En respuesta, el liderazgo de OpenAI pausó proyectos periféricos—incluyendo experimentos de plataforma publicitaria y expansiones de agentes para consumidores—para concentrarse por completo en un modelo capaz de ejecutar un "golpe táctico" contra estos competidores.
Garlic es ese golpe. No está diseñado para ser el modelo más grande del mundo; está diseñado para ser el más inteligente por parámetro. Fusiona las líneas de investigación de proyectos internos previos, sobre todo "Shallotpeat", incorporando correcciones de errores y eficiencias de preentrenamiento que le permiten golpear por encima de su peso.
¿Cuál es el estado actual de las iteraciones observadas del modelo GPT-5.3?
A mediados de enero de 2026, GPT-5.3 se encuentra en las etapas finales de validación interna, una fase que en Silicon Valley a menudo se describe como “hardening”. El modelo es visible actualmente en registros internos y ha sido probado puntualmente por socios empresariales selectos bajo estrictos acuerdos de confidencialidad.
Iteraciones observadas e integración de “Shallotpeat”
El camino hacia Garlic no fue lineal. Memorias internas filtradas del Chief Research Officer Mark Chen sugieren que Garlic es en realidad un compuesto de dos líneas de investigación distintas. Inicialmente, OpenAI estaba desarrollando un modelo con nombre en clave "Shallotpeat", concebido como una actualización incremental directa. Sin embargo, durante el preentrenamiento de Shallotpeat, los investigadores descubrieron un método novedoso para "comprimir" patrones de razonamiento: esencialmente enseñar al modelo a descartar rutas neuronales redundantes antes en el proceso de entrenamiento.
Este descubrimiento condujo al descarte del lanzamiento independiente de Shallotpeat. Su arquitectura se fusionó con la rama más experimental "Garlic". El resultado es una iteración híbrida que posee la estabilidad de una variante GPT-5 madura pero la explosiva eficiencia de razonamiento de una nueva arquitectura.
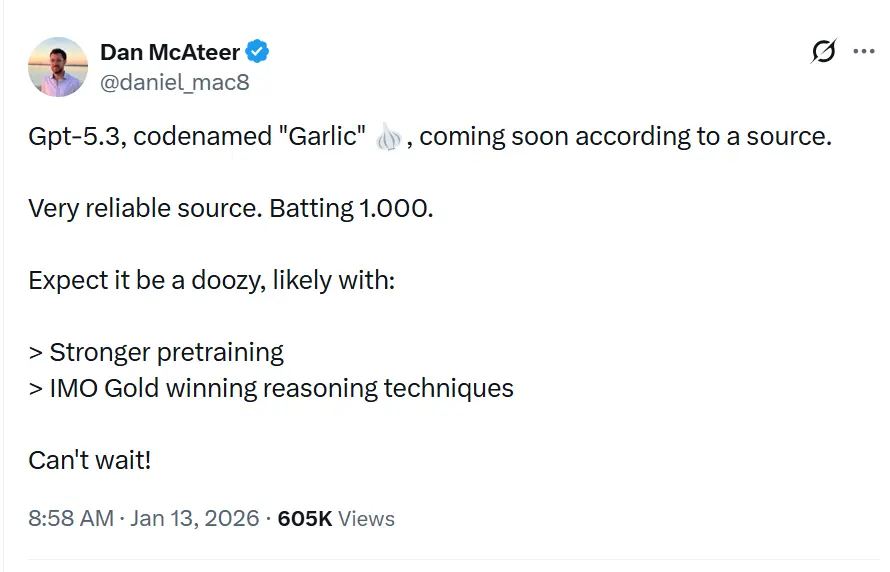
¿Cuándo podemos inferir que ocurrirá el lanzamiento?
Predecir fechas de lanzamiento de OpenAI es notoriamente difícil, pero el estatus de "Código Rojo" acelera los cronogramas estándar. Con base en la convergencia de filtraciones, actualizaciones de proveedores y ciclos de competidores, podemos triangular una ventana de lanzamiento.
Ventana principal: Q1 de 2026 (enero - marzo)
El consenso entre los conocedores es un lanzamiento en Q1 de 2026. El "Código Rojo" fue declarado en diciembre de 2025, con una directiva de lanzar "lo antes posible". Dado que el modelo ya está en comprobación/validación (la fusión con "Shallotpeat" ha acelerado el cronograma), un lanzamiento a finales de enero o principios de febrero parece lo más plausible.
El despliegue “Beta”
Podríamos ver un lanzamiento escalonado:
- Finales de enero de 2026: Un lanzamiento "preview" para socios selectos y usuarios de ChatGPT Pro (posiblemente bajo la etiqueta "GPT-5.3 (Preview)").
- Febrero de 2026: Disponibilidad completa de la API.
- Marzo de 2026: Integración en el nivel gratuito de ChatGPT (consultas limitadas) para contrarrestar la accesibilidad gratuita de Gemini.
¿Cuáles son las 3 características definitorias de GPT-5.3?
Si los rumores se confirman, GPT-5.3 introducirá un conjunto de funciones que priorizan la utilidad y la integración sobre la creatividad generativa bruta. El conjunto de funciones parece una lista de deseos para arquitectos de sistemas y desarrolladores empresariales.
1. Preentrenamiento de alta densidad (EPTE)
La joya de la corona de Garlic es su Eficiencia de Preentrenamiento Mejorada (EPTE).
Los modelos tradicionales aprenden viendo cantidades masivas de datos y creando una red extensa de asociaciones. El proceso de entrenamiento de Garlic, según se informa, incluye una fase de "poda" en la que el modelo condensa activamente la información.
- El resultado: Un modelo físicamente más pequeño (en términos de requisitos de VRAM) pero que retiene el "Conocimiento del Mundo" de un sistema mucho más grande.
- El beneficio: Velocidades de inferencia más rápidas y costos de API significativamente más bajos, abordando la relación "inteligencia-costo" que ha impedido la adopción masiva de modelos como Claude Opus.
2. Razonamiento agentivo nativo
A diferencia de modelos anteriores que requerían "envoltorios" o ingeniería de prompts compleja para funcionar como agentes, Garlic tiene capacidades nativas de llamada a herramientas.
El modelo trata las llamadas a API, la ejecución de código y las consultas a bases de datos como "ciudadanos de primera clase" en su vocabulario.
- Integración profunda: No solo "sabe programar"; entiende el entorno del código. Según informes, puede navegar por un directorio de archivos, editar múltiples archivos simultáneamente y ejecutar sus propias pruebas unitarias sin scripts de orquestación externos.
3. Ventanas masivas de contexto y salida
Para competir con la ventana de contexto de un millón de tokens de Gemini, se rumorea que Garlic se enviará con una ventana de contexto de 400,000 tokens. Aunque más pequeña que la oferta de Google, el diferenciador clave es el "Recuerdo Perfecto" en esa ventana, utilizando un nuevo mecanismo de atención que evita la pérdida del "medio del contexto" común en los modelos de 2025.
- Límite de salida de 128k: Quizá más emocionante para los desarrolladores sea la expansión rumoreada del límite de salida a 128,000 tokens. Esto permitiría al modelo generar bibliotecas de software completas, informes legales exhaustivos o novelas de longitud completa en una sola pasada, eliminando la necesidad de "fragmentación".
4. Reducción drástica de alucinaciones
Garlic utiliza una técnica de refuerzo post-entrenamiento centrada en la "humildad epistémica": el modelo se entrena rigurosamente para saber lo que no sabe. Las pruebas internas muestran una tasa de alucinaciones significativamente menor que GPT-5.0, haciéndolo viable para industrias de alto riesgo como biomedicina y derecho.
¿Cómo se compara con competidores como Gemini y Claude 4.5?
El éxito de Garlic no se medirá en aislamiento, sino en comparación directa con los dos titanes que actualmente dominan la arena: Gemini 3 de Google y Claude Opus 4.5 de Anthropic.
GPT-5.3 “Garlic” vs. Google Gemini 3
La batalla de la escala vs. la densidad.
- Gemini 3: Actualmente el modelo "todo en la cocina". Domina en comprensión multimodal (video, audio, generación nativa de imágenes) y tiene una ventana de contexto efectivamente infinita. Es el mejor modelo para datos del mundo real "desordenados".
- GPT-5.3 Garlic: No puede competir con la amplitud multimodal bruta de Gemini. En su lugar, ataca a Gemini en la pureza del razonamiento. Para generación de texto puro, lógica de código e instrucciones complejas, Garlic pretende ser más preciso y menos propenso a la "negativa" o a divagar.
- El veredicto: Si necesitas analizar un video de 3 horas, usas Gemini. Si necesitas escribir el backend de una app bancaria, usas Garlic.
GPT-5.3 “Garlic” vs. Claude Opus 4.5
La batalla por el alma del desarrollador.
- Claude Opus 4.5: Lanzado a finales de 2025, este modelo conquistó a los desarrolladores con su "calidez" y "vibras". Es famoso por escribir código limpio y legible, y seguir instrucciones del sistema con precisión milimétrica. Sin embargo, es caro y lento.
- GPT-5.3 Garlic: Este es el objetivo directo. Garlic pretende igualar la competencia de Opus 4.5 en codificación pero a 2x la velocidad y 0.5x el costo. Mediante el "Preentrenamiento de Alta Densidad", OpenAI quiere ofrecer inteligencia al nivel de Opus con un presupuesto al nivel de Sonnet.
- El veredicto: El "Código Rojo" se activó específicamente por el dominio de Opus 4.5 en codificación. El éxito de Garlic depende por completo de si puede convencer a los desarrolladores de volver a cambiar sus claves de API a OpenAI. Si Garlic puede programar tan bien como Opus pero ejecutarse más rápido, el mercado cambiará de la noche a la mañana.
Conclusión
Las primeras versiones internas de Garlic ya superan a Gemini 3 de Google y Opus 4.5 de Anthropic en dominios específicos de alto valor:
- Competencia en codificación: En benchmarks internos "duros" (más allá del HumanEval estándar), Garlic ha mostrado una menor tendencia a atascarse en "bucles lógicos" en comparación con GPT-4.5.
- Densidad de razonamiento: El modelo requiere menos tokens de "pensamiento" para llegar a conclusiones correctas, en contraste directo con la pesadez de "cadena de pensamiento" de la serie o1 (Strawberry).
| Métrica | GPT-5.3 (Garlic) | Google Gemini 3 | Claude 4.5 |
|---|---|---|---|
| Razonamiento (GDP-Val) | 70.9% | 53.3% | 59.6% |
| Programación (HumanEval+) | 94.2% | 89.1% | 91.5% |
| Ventana de contexto | 400K tokens | 2M tokens | 200K tokens |
| Velocidad de inferencia | Ultrarrápida | Moderada | Rápida |
Conclusión
“Garlic” es un rumor activo y plausible: una vía de ingeniería dirigida de OpenAI que prioriza densidad de razonamiento, eficiencia y herramientas del mundo real. Su aparición debe verse en el contexto de una carrera armamentista acelerada entre proveedores de modelos (OpenAI, Google, Anthropic), en la que el premio estratégico no es solo la capacidad bruta sino la capacidad utilizable por dólar y por milisegundo de latencia.
Si te interesa este nuevo modelo, sigue a CometAPI. Siempre actualiza con los últimos y mejores modelos de IA a un precio asequible.
Los desarrolladores pueden acceder a GPT-5.2, Gemini 3 y Claude 4.5 a través de CometAPI ahora. Para comenzar, explora las capacidades de los modelos de CometAPI en el Playground y consulta la API guide para instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio mucho más bajo que el oficial para ayudarte a integrar.
¿Listo para empezar?→ Sign up for CometAPI today
Si quieres más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!