
.png&w=3840&q=75)
GPT-5.4 Mini y GPT-5.4 Nano son las nuevas variantes compactas de OpenAI de su familia de vanguardia GPT-5.4: Mini apunta a un compromiso de rendimiento/latencia de primer nivel para programación, tareas de IU multimodal y cargas de trabajo de subagentes; Nano apunta a un costo y latencia ultrabajos para clasificación, extracción, ranking y subagentes masivamente paralelos. Mini ofrece una precisión cercana a la de vanguardia en muchos benchmarks para desarrolladores mientras se ejecuta más de 2× más rápido que las minis anteriores; Nano es significativamente más barato por token e ideal donde el rendimiento y la capacidad de respuesta importan más. Estos modelos están disponibles en la API (GPT 5.4 Mini y Nano están disponibles en CometAPI).
¿Qué son GPT-5.4 Mini y GPT-5.4 Nano?
Definición breve: GPT-5.4 Mini y GPT-5.4 Nano son variantes compactas y diseñadas de la familia GPT-5.4 creadas para llevar las fortalezas principales del GPT-5.4 grande (razonamiento, programación, percepción multimodal, uso de herramientas) a modelos más rápidos y de menor costo dirigidos a cargas de trabajo de alto volumen y baja latencia. Los modelos fueron anunciados por OpenAI como parte del lanzamiento de GPT-5.4.
- GPT-5.4 Mini — Un modelo pequeño y de alto desempeño que “se acerca al rendimiento de GPT-5.4 en varias evaluaciones” mientras está optimizado para velocidad y menor costo. Se destaca específicamente para programación, razonamiento, interpretación de IU multimodal (capturas de pantalla) y como subagente en sistemas agénticos. OpenAI informa que se ejecuta más de 2× más rápido que las variantes “mini” anteriores.
- GPT-5.4 Nano — La variante más pequeña y barata de GPT-5.4; recomendada para clasificación, extracción, ranking y subagentes “de soporte” que manejan tareas estrechas y repetitivas con rendimiento muy alto. Sacrifica razonamiento profundo a cambio de latencia y ahorro de costos.
Disponibilidad y precio
OpenAI proporciona dos puntos de datos concretos que puedes usar para comparar costos:
- Precio de entrada de la API de GPT-5.4 (insignia completa): $2.50 / 1M tokens (y precio de salida más alto en el modelo insignia).
- Precio de entrada de la API de GPT-5.4 mini: $0.75 / 1M tokens y salida $4.50 / 1M tokens.
- Precio de entrada de la API de GPT-5.4 nano: $0.20 / 1M y salida $1.25 / 1M.
Poniéndolo uno al lado del otro: el precio por token de entrada de mini (0.75) es el 30% del de la insignia (2.50), es decir, aproximadamente un tercio del costo de entrada; el precio de salida de mini (4.50) es aproximadamente el 32% del precio de salida de la insignia citado en la tabla de precios de la API, es decir, también cerca de un tercio. Nano es aún más barato: su costo de entrada es alrededor del 8% del costo de entrada de la insignia, y su costo de salida está por debajo del 10% del costo de salida de la insignia. Estas proporciones son exactamente la razón por la que OpenAI presenta mini/nano como “aproximadamente un tercio” (mini) y “una fracción de” (nano) del costo de usar los modelos más grandes para tareas de alto volumen. El precio del token de nano subió de $0.05 a $0.20, y el precio del token de mini subió de $0.25 a $0.75 (para tokens de entrada).
En la plataforma de OpenAI
GPT-5.4 mini está disponible en tres lugares: la API de OpenAI, Codex (la plataforma IDE/app para desarrolladores de OpenAI) y ChatGPT (disponible para usuarios Free y Go a través de la opción “Thinking” y como recurso alternativo por límite de tasa para los niveles de pago). En la API admite entradas de texto e imagen, uso de herramientas (function calling), búsqueda web/archivos, uso del ordenador y skills; y ofrece una ventana de contexto muy grande (400k tokens) para flujos de trabajo con muchos documentos y múltiples capturas de pantalla. El precio en la API es de $0.75 por 1M de tokens de entrada y $4.50 por 1M de tokens de salida.
GPT-5.4 nano solo está disponible a través de la API. Sus precios de lista son $0.20 por 1M de tokens de entrada y $1.25 por 1M de tokens de salida, posicionándolo como la entrada de menor costo en la familia GPT-5.4. El modelo nano deliberadamente intercambia capacidad por costo y velocidad.
En plataforma de terceros
CometAPI es una plataforma de agregación multimodal de APIs de IA que ahora ha lanzado la API de la serie GPT 5.4, incluyendo GPT 5.4 Mini y GPT 5.4 Nano, con un 20% de descuento sobre el precio de OpenAI.
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Características clave y qué hay de nuevo
A continuación se muestran las capacidades principales — por qué importan a ingenieros y equipos de producto.
Codificación y compatibilidad con contexto largo
Ventana de contexto: GPT-5.4 mini admite una ventana de contexto de 400k tokens (OpenAI lista explícitamente a mini con 400k de contexto). Esto es suficiente para bases de código multifichero, documentos extensos o sesiones de agente de múltiples turnos donde el contexto importa. El contexto de Nano es menor en relación con GPT-5.4 completo pero aún sustancial para tareas cortas y rápidas.
Razonamiento
Niveles de razonamiento: OpenAI expone reasoning_effort configurable (none → xhigh); mini y nano pueden ejecutarse con distintos niveles de esfuerzo, pero mini cierra la brecha con GPT-5.4 completo en muchos benchmarks de razonamiento con mayor esfuerzo. En varios benchmarks de inteligencia (por ejemplo, GPQA Diamond), mini alcanza un 88.0% frente al 93.0% de GPT-5.4, y nano logra 82.8%, lo que indica un razonamiento respetable para un modelo pequeño. Estos son los resultados que OpenAI publicó en su post de lanzamiento.
Comprensión multimodal (visión e IU)
Percepción visual y tareas de IU: GPT-5.4 mini muestra un desempeño multimodal muy sólido para tareas de IU (capturas de pantalla, imágenes de documentos densos). En OSWorld-Verified (un benchmark de uso de ordenador), mini obtiene 72.1%, muy cerca del 75.0% de GPT-5.4 y muy por encima de minis anteriores — por eso mini se posiciona para automatizaciones impulsadas por capturas de pantalla y asistentes multimodales receptivos. Nano rinde menos en benchmarks visuales pero sigue siendo útil para tareas de imagen más simples.
Invocación de herramientas y uso del ordenador
Capacidades nativas de herramientas/clic: GPT-5.4 introduce y amplía herramientas nativas de “computer use”; mini hereda la capacidad de llamar herramientas, hacer llamadas a funciones, interpretar capturas de pantalla y orquestar subagentes. Los benchmarks de llamadas a herramientas (Toolathlon, MCP Atlas) muestran puntuaciones respetables para mini y nano (Toolathlon: mini 42.9%, nano 35.5%) — cuantifican su capacidad para llamar y coordinar herramientas externas. Estas métricas provienen del anuncio de OpenAI.
Alucinaciones / factualidad / tasas de error
OpenAI informa que GPT-5.4 es “el modelo más factual hasta ahora” y muestra reducciones de alucinaciones frente a GPT-5.2; mini y nano muestran una factualidad absoluta menor que el modelo completo (por ejemplo, HLE w/ tools: GPT-5.4 52.1%, mini 41.5%, nano 37.7%), lo que sugiere una mayor necesidad de verificación cuando se usan modelos más pequeños en tareas de alta factualidad. Usa verificación basada en herramientas (llamadas a herramientas, recuperación de citas) cuando la corrección sea crítica.
Velocidad
OpenAI informa que GPT-5.4 mini se ejecuta más de 2× más rápido que el anterior GPT-5 mini en estimaciones de latencia típicas de producción (basadas en comportamiento de producción simulado que incluye duraciones de llamadas a herramientas y tokens muestreados). Este aumento de velocidad es una afirmación central de la nueva familia y permite usar mini como un subagente receptivo dentro de aplicaciones interactivas como asistentes de programación.
¿Cómo rinden mini y nano — se “acercan” a GPT-5.4 completo?
OpenAI publicó un conjunto completo de comparaciones de benchmarks en programación, uso de herramientas, tareas multimodales de uso de ordenador, pruebas de inteligencia y evaluaciones de contexto largo. Las cifras principales (razonamiento xhigh donde corresponda) incluyen:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | Notas |
|---|---|---|---|---|---|
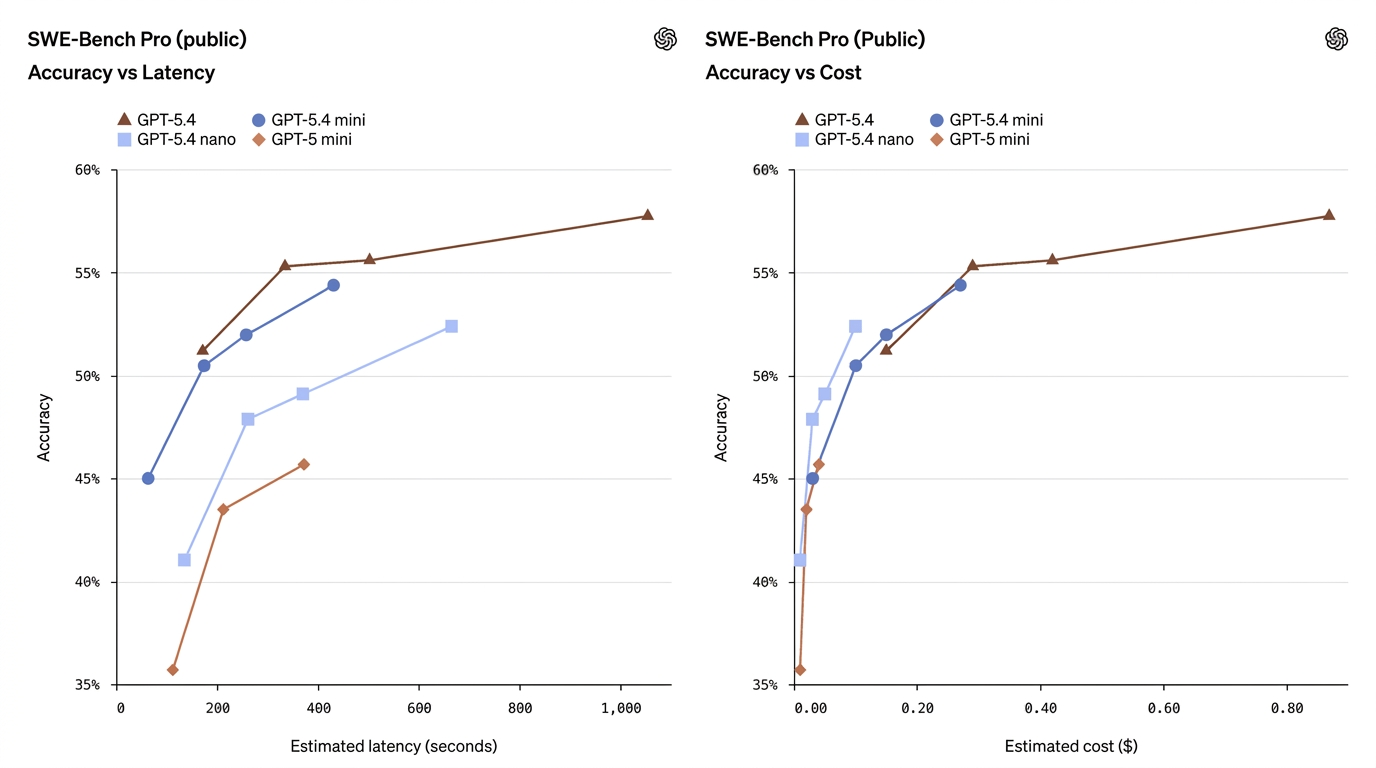
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini se aproxima al rendimiento del modelo completo en programación |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Fuerte capacidad de programación en tiempo real para Mini |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | Mide la orquestación y la invocación de herramientas |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | Benchmark de inteligencia y razonamiento |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | Capacidad de IU/uso del ordenador |
Estas cifras muestran que mini a menudo reduce considerablemente la brecha — especialmente en tareas de programación y uso de ordenador — mientras que nano ocupa un punto medio útil entre capacidad y costo.
¿Qué significan los números en palabras simples?
- GPT-5.4 Mini ≈ “casi al nivel del buque insignia” en muchas tareas de producción. En SWE-Bench Pro (una métrica de tasa de aprobación en programación), mini obtiene 54.4% frente a 57.7% del modelo insignia — una brecha relativa pequeña para muchas tareas reales de programación, especialmente cuando la latencia importa. En OSWorld (uso del ordenador), mini logra 72.1% frente a 75.0% del insignia — de nuevo, muy cerca para tareas de IU/capturas de pantalla.
- GPT-5.4 Nano sacrifica más capacidad por velocidad/costo. La puntuación de programación de nano (52.4% en SWE-Bench Pro) es respetable respecto a minis anteriores, pero su puntuación en OSWorld cae a 39.0%, mostrando que para tareas que requieren comprensión compleja de IU de múltiples pasos o secuencias agénticas de herramientas, nano es menos adecuado. Nano destaca en clasificación de un solo turno, extracción y pequeñas tareas de soporte.
- El uso de herramientas mejora, pero sigue siendo sensible. Toolathlon y otras métricas de uso de herramientas suben sustancialmente al pasar de GPT-5 mini a GPT-5.4 mini/nano, mostrando que la ingeniería de OpenAI mejoró la fiabilidad de invocación de herramientas en los modelos de menor tamaño — pero el modelo completo sigue liderando en orquestaciones de herramientas complejas.
Cómo funcionan en producción
Compresión, destilación y optimizaciones de ingeniería
Los modelos compactos como mini/nano suelen usar una combinación de destilación de modelos, cuantización y poda arquitectónica para preservar capacidades de alto valor (heurísticas de programación, perceptos visuales) mientras reducen el cómputo de inferencia. La redacción de OpenAI indica una ingeniería enfocada en preservar conjuntos de habilidades específicos (programación, comprensión de IU multimodal) en huellas más pequeñas.
Patrones recomendados
- Patrón orquestador + subagentes: Usa GPT-5.4 (grande) como planificador/juez y delega trabajo a subagentes GPT-5.4 mini / nano para ejecución rápida (buscar, parsear, editar). Esto reduce el costo total y baja la latencia para el usuario. OpenAI respalda explícitamente este patrón de diseño.
- Mecanismos de reserva y gestión de límites de tasa: Expón mini como recurso alternativo por límite de tasa en ChatGPT o Codex para que las consultas sensibles al tiempo reciban una respuesta competente cuando el modelo completo no esté disponible.
- Arquitectura en capas para control de costes: Tuberías masivas (indexación, extracción) → GPT-5.4 nano; componentes de IU interactivos → GPT-5.4 mini; juicio editorial final / cadenas complejas → GPT-5.4 completo. Este enfoque multinivel equilibra costo y capacidad.
Latencia y paralelización
Mini y nano están optimizados para subagentes paralelos, donde muchos pequeños trabajadores se ejecutan concurrentemente — por ejemplo, escanear miles de PDF en paralelo. El concepto de OpenAI de “tool yields” mide cómo las llamadas a herramientas paralelas reducen la latencia total; mini/nano están diseñados para hacer que esos patrones sean rentables.
Cómo utilizaría mini y nano en la práctica
¿Debería sustituir mis llamadas al modelo insignia por mini/nano en todas partes?
No automáticamente. El patrón correcto que OpenAI recomienda explícitamente es la delegación: usa un modelo más grande para la planificación, el juicio complejo o la verificación final, y delega muchas subtareas de soporte y más cortas a subagentes mini o nano. Este patrón reduce el costo y la latencia mientras mantiene los controles del modelo grande donde más importan. Casos de uso:
- Asistentes de programación interactivos: el insignia planifica y revisa; mini maneja búsqueda rápida de código, ediciones y tests unitarios cortos.
- Agentes de “uso del ordenador” impulsados por capturas de pantalla: mini puede analizar interfaces densas rápidamente; el insignia resuelve la planificación ambigua de múltiples pasos.
- Tuberías de extracción y clasificación de alto volumen: nano procesa entradas masivas por lotes (formularios, logs) y devuelve resultados estructurados; el insignia maneja excepciones y casos límite complejos.
¿Se pueden usar mini o nano para tareas multimodales o de imagen?
Sí — mini admite entradas de imagen y rinde bien en benchmarks multimodales/vision-driven (MMMUPro/OmniDocBench), acercándose al insignia en algunas pruebas. La fortaleza multimodal de nano es más limitada: aunque mejora respecto a nanos anteriores, no es la mejor opción para razonamiento multimodal profundo o tareas agénticas basadas en imágenes.
La carrera por las capacidades de modelos pequeños se ha intensificado
Hace tres meses, los modelos pequeños se consideraban “suficientemente buenos”. Ahora, GPT-5.4 mini se está acercando a los modelos insignia en benchmarks de programación y casi igualándolos en rendimiento computacional.
La tendencia es clara: las capacidades de los modelos insignia se transfieren rápidamente a modelos más pequeños. OpenAI, Google y Anthropic están haciendo lo mismo: destilar las capacidades centrales de los modelos grandes en versiones más pequeñas, rápidas y económicas.
Conclusión
El lanzamiento de estos dos modelos significa un cambio en las aplicaciones de IA desde un enfoque en la escala hacia un enfoque en la eficiencia práctica. A través de capacidades de respuesta rápida, proporcionan un soporte subyacente más confiable para la interacción de IA en tiempo real y la descomposición de flujos de tareas complejas.
Para los desarrolladores, esto significa que la estructura de costos de los sistemas de agentes se está redefiniendo. Cuando los costos caen a este nivel, muchos escenarios de agentes que antes eran “teóricamente factibles pero económicamente inviables” se vuelven viables.
Los desarrolladores pueden acceder a GPT 5.4 Mini y GPT-5.4 Nano a través de CometAPI (CometAPI es una plataforma integral de agregación de APIs de grandes modelos como GPT APIs, Nano Banana APIs, etc.) ahora. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de la API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para empezar?