

xAI lanzó silenciosamente Grok 4.1 (17-18 de noviembre de 2025) — una actualización específica de Grok 4 que prioriza inteligencia emocional, expresión creativa y reducción de las alucinaciones Manteniendo la precisión de razonamiento característica de las versiones anteriores de Grok, esta nueva versión se presenta en dos modos (Pensando / Sin Pensar), se lanzó discretamente a principios de noviembre, muestra los mejores resultados de la clasificación en LMArena y está disponible a través de grok.com, las aplicaciones de Grok y la API.
¿Qué es Grok 4.1?
Grok 4.1 es la versión incremental y orientada a la producción de Grok 4: un miembro de la familia construido sobre la misma base de aprendizaje por refuerzo a gran escala, pero perfeccionado y reentrenado con optimizaciones post-entrenamiento exhaustivas dirigidas al estilo, la personalidad, la coherencia y la fiabilidad en el mundo real. Se presenta como un paso adelante pragmático y práctico: más inteligente en pruebas de preferencia a ciegas con humanos, con mayor inteligencia emocional, mejor en escritura creativa y notablemente menos propenso a las «alucinaciones» de confianza errónea que han afectado a los anteriores modelos de aprendizaje automático de alto rendimiento.
Grok 4.1 logra cambios cualitativos en las siguientes cuatro dimensiones:
- Creatividad: Demuestra un estilo lingüístico e imaginación más sólidos en la escritura, la narración de historias y los contextos sociales;
- Inteligencia emocional: Reconoce los cambios de tono y emocionales, respondiendo con una lógica emocional más humana y generando respuestas reconfortantes y comprensivas;
- Coherencia de personalidad: Mantiene un tono y una personalidad consistentes en conversaciones largas, y ya no muestra el comportamiento inconsistente de los modelos anteriores;
- Colaborativo: Mantiene la coherencia y la conciencia de los objetivos en diálogos de múltiples turnos o en la colaboración en tareas.
xAI resume sus características en una frase: “Es más perceptiva, más empática y más parecida a una persona coherente”.
¿Cómo funciona Grok 4.1 internamente?
Grok 4.1 se entiende mejor como la misma estructura básica preentrenada utilizada en toda la familia Grok 4, además de un proceso de post-entrenamiento por capas que se centra en modelado de recompensas, alineación de estilos y evaluadores agentivos.
¿Cuáles son las etapas de entrenamiento y alineación?
Grok 4.1 funciona con un proceso de varias etapas típico de los modernos LLM de vanguardia, adaptado con dos cambios importantes para la versión 4.1:
- Pre-entrenamiento + entrenamiento a mitad de camino: Preentrenamiento con grandes corpus de datos web + entrenamiento intermedio específico para potenciar el conocimiento del dominio y las capacidades multimodales.
- Ajuste fino supervisado (SFT): Demostraciones humanas de los comportamientos deseados (respuestas, estrategias de rechazo).
- Modelado de recompensas (aplicación novedosa): xAI entrenó modelos de recompensa no solo con etiquetas de preferencia humana, sino que también utilizó modelos de razonamiento agentivo de frontera como evaluadores de recompensas, permitiendo efectivamente que evaluadores de alta capacidad basados en modelos califiquen los resultados de los candidatos a gran escala. Esto permitió la optimización de atributos no verificables como estilo, cohesión de la personalidad, empatía y disposición para ayudar sin requerir un presupuesto de etiquetado humano imposiblemente grande.
- Optimización de políticas (RLHF / RL a partir de recompensas del modelo): Optimización estándar de políticas utilizando las señales de recompensa aprendidas para producir la política implementada (el modelo con el que interactúan los consumidores).
¿Qué novedades presenta el enfoque de modelado de recompensas?
En el aprendizaje por refuerzo tradicional, se recopilan etiquetas de preferencia humanas (A/B), se entrena un modelo de recompensa para predecir dichas etiquetas y, posteriormente, se optimiza el modelo base mediante aprendizaje por refuerzo (o muestreo por rechazo) en función de la recompensa aprendida. Sin embargo, xAI destaca dos innovaciones prácticas:
- Modelos de recompensa agentiva: En lugar de jueces puramente humanos, xAI utilizó modelos de razonamiento «agente» avanzados como evaluadores para analizar propiedades más sutiles (tono, matices emocionales, creatividad). Estos evaluadores pueden realizar miles de comparaciones por pares rápidamente, lo que permite a los ingenieros iterar con mayor agilidad. Este es el mecanismo que permite importantes mejoras en el estilo y la inteligencia emocional.
- Alineación posterior al entrenamiento para señales no verificables: Para los atributos que no se pueden medir con una métrica determinista (por ejemplo, "calidez" o "personalidad coherente"), introdujeron objetivos de recompensa especializados y programas de aprendizaje escalables para que el modelo aprenda estilo de resultados sin sacrificar la precisión fáctica fundamental.
¿Cómo funciona técnicamente la distinción entre “pensamiento” y “no pensamiento”?
- Grok 4.1 Pensamiento (nombre en clave)
quasarflux) — Expone los pasos de razonamiento explícitos (tokens de pensamiento) antes de generar la respuesta final; optimizado para tareas complejas y un nivel Elo más alto en LMArena. Los tokens adicionales aumentan el tiempo de inferencia, pero facilitan las tareas de razonamiento de varios pasos, la depuración y la explicabilidad. - Grok 4.1 No Pensar (nombre en clave)
tensor) Se omiten los tokens intermedios explícitos para obtener una respuesta final única e inmediata. Esto reduce la latencia y el coste de tokens, manteniendo las mismas ponderaciones de política optimizadas. El modo sin procesamiento se optimizó para ofrecer una latencia extremadamente baja sin sacrificar su capacidad.
Optimización de la alineación del sentimiento y el estilo
Más allá de las simples señales de «veracidad», Grok 4.1 incluye una optimización de alineación específica para el sentimiento, el tono y el estilo interpersonal. Esto significa que el proceso de entrenamiento incluye componentes de recompensa o penalización que castigan explícitamente el tono inadecuado (por ejemplo, ser innecesariamente cortante cuando la empatía es apropiada) y recompensan las respuestas que se ajustan al estilo o perfil de sentimiento deseado. En Grok 4.1, la IA introdujo por primera vez el objetivo de optimización de «Alineación de Personalidad».
Su objetivo es ayudar al modelo a mantener una identidad coherente y estable. En comparación con Grok 4, la versión 4.1 añade lo siguiente a los objetivos de entrenamiento:
- Recompensas positivas para la dimensión de expresión emocional (recompensa por alineación emocional);
- Una métrica de coherencia de la personalidad.
¿Cómo se evaluó Grok 4.1 y cuál fue su rendimiento?
¿Qué mostraron las pruebas de preferencia humana a ciegas?
Durante un despliegue silencioso, Grok 4.1 fue preferido el 64.78% de las veces frente al modelo de producción anterior en tráfico real, una fuerte señal de preferencia humana que indica mejores resultados conversacionales en situaciones reales.
¿Grok 4.1 lidera las clasificaciones?
xAI informa que Grok 4.1 Ideas el modo se encuentra en N.° 1 en la sección de textos de LMArena, con un Elo reportado de 1483, y su modo no racional (rápido) ocupa el puesto número 2 con 1465 Elo; una sólida posición en las clasificaciones públicas tanto por su precisión como por su presentación (el control del estilo juega un papel importante).
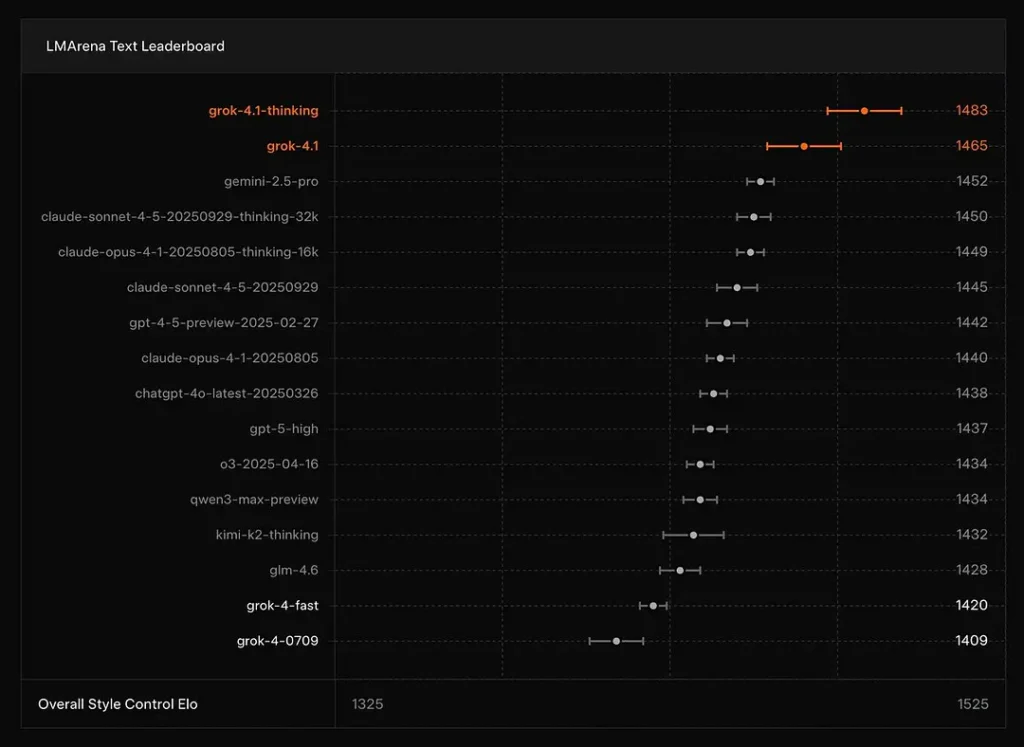
Conclusión: Grok 4.1 supera a los modelos principales GPT-4.5 y de la serie Claude en comprensión de texto, generación y calidad general, siendo superado únicamente por la versión GPT-5 Advanced Preview.
Inteligencia Emocional
xAI ejecutó EQ-Bench3, una prueba especializada de inteligencia emocional que abarca 45 escenarios desafiantes de juegos de rol, e informa que Grok 4.1 muestra fuertes avances en empatía, ritmo y comprensión interpersonal. Grok 4.1 obtuvo la puntuación más alta en comprensión de contextos de tristeza, empatía y consuelo.

La escritura creativa: ¿es realmente más imaginativa?
Grok 4.1 fue evaluado el Escritura creativa v3 (32 preguntas en 3 iteraciones con rúbrica y puntuación Elo). xAI afirma que el estilo de escritura, la coherencia de la voz y la creatividad narrativa de la versión 4.1 mejoraron sustancialmente, situándola entre las mejores en las clasificaciones recientes de tareas creativas (se incluyen ejemplos de preguntas en la publicación). Informes independientes corroboraron estos hallazgos: los revisores observaron una voz distintiva mucho más marcada y una mayor coherencia en los textos extensos. En cuanto a la calidad de la escritura, Grok 4.1 solo es superado por los modelos de la serie GPT-5 y supera a las líneas de productos completas de Claude, Gemini y Kimi.

Alucinaciones reducidas / honestidad
xAI afirma una notable reducción en las tasas de alucinaciones: informaron (en el anuncio y las publicaciones en redes sociales) que Grok 4.1 es ~3 veces menos probabilidades de tener alucinaciones En comparación con modelos Grok anteriores, basados en análisis de tráfico de producción y evaluaciones al estilo FActScore (por ejemplo, conjuntos de preguntas biográficas, donde un valor menor indica mejor puntuación), la consistencia de los datos es más estable, especialmente en el modo de búsqueda externa, donde se dispone de herramientas de búsqueda externas.

¿Por qué Grok 4.1 “aplasta” a otros modelos? ¿Es eso una hipérbole?
“Crushes” tiene tintes de marketing, pero detrás de esa afirmación hay argumentos objetivos:
- Tablas de clasificación: Grok 4.1 ocupa los primeros puestos en las clasificaciones públicas de LMArena para generación de texto (1483 Elo en el modo Pensamiento) y destaca por su creatividad y su inteligencia emocional, según la versión de xAI. Se trata de métricas competitivas comparables utilizadas por toda la comunidad.
- La preferencia por el tráfico real se impone: xAI reporta una mayor preferencia humana en comparaciones a ciegas (aproximadamente un 65 % de preferencia frente al modelo de producción anterior) tras un despliegue silencioso en tráfico real. Esto refleja mejoras reales para el usuario, no solo resultados de pruebas teóricas.
- Nueva capacidad práctica: La combinación de evaluadores de modelos, aprendizaje por refuerzo en señales no verificables y filtros de entrada más estrictos es un paso de ingeniería pragmático que mejora directamente la experiencia del usuario en tareas conversacionales, empáticas y creativas donde los competidores históricamente han tenido un rendimiento inferior.
Así pues, aunque «enamoramiento» es una forma colorida de decir «lidera en múltiples evaluaciones públicas e internas», las métricas públicas subyacentes que publicó xAI respaldan esa conclusión.
Cómo acceder a Grok 4.1
Acceso del consumidor/aplicación
xAI ha ofrecido periódicamente acceso a Grok 4.1 en modo “Automático” de forma gratuita o como parte de una promoción, pero existen y se mantienen como ofertas de pago niveles premium (SuperGrok, SuperGrok Heavy) y acceso a la API con cuotas más altas.
Grok 4.1 está disponible para todos los usuarios. on es:grok.com, X (anteriormente Twitter), y las aplicaciones Grok para iOS y Android, que se implementarán de inmediato en modo automático y también se podrán seleccionar explícitamente como “Grok 4.1” en el selector de modelos.
Acceso a la API y planes para desarrolladores
Los endpoints de Grok 4.1 están disponibles a través de la API de xAI. A la fecha de publicación de este artículo, la API oficial de GPT 4.1 aún no se ha publicado.
CometAPI promete mantenerse al tanto de la dinámica del modelo más reciente, incluyendo API de Grok 4.1, que se lanzará simultáneamente con la versión oficial. Estén atentos y sigan pendientes de CometAPI. Mientras tanto, pueden consultar otros modelos de Grok, como Código Grok rápido 1 y Grok 4Explore sus funcionalidades en el entorno de pruebas y consulte la guía de la API para obtener instrucciones detalladas sobre cómo realizar llamadas. Antes de acceder, asegúrese de haber iniciado sesión en CometAPI y de haber obtenido la clave de API.
Consejos prácticos para usar Grok 4.1 en producción
Cómo reducir el riesgo de alucinaciones
- Habilitar búsqueda en vivo o una cadena de herramientas verificada para consultas de búsqueda de información.
- Proporcionar pasos de verificación: pedirle al modelo que proporcione fuentes y pruebas para las afirmaciones fácticas; usar el
responsemetadatos para inspeccionar las citas (si están disponibles). - Ejecutar comprobaciones deterministas (verificación de datos LLM, validadores de datos estructurados) como paso de postprocesamiento para resultados de alto riesgo.
Cómo controlar el tono y el estilo
- Utilice las indicaciones explícitas del sistema para corregir la voz (“Usted es formal y empático”).
- Utilice avisos supervisados y pequeñas plantillas locales para lograr una voz coherente en todas las aplicaciones.
- Cuando estén disponibles, aproveche la opción de control de estilo de xAI y los mandos de dirección basados en recompensas.
Veredicto final: ¿Grok 4.1 supone un cambio radical?
Grok 4.1 es no una arquitectura completamente nueva; más bien, es una arquitectura sofisticada y bien pensada. post-entrenamiento / alineación Una versión que se centra en lo que realmente le importa a la gente en el chat: personalidad, inteligencia emocional, creatividad y menos errores fácticosMejoras significativas en las clasificaciones, preferencias de tráfico real a gran escala y herramientas de seguridad optimizadas. Para aplicaciones que dependen de conversaciones de alta calidad, colaboración creativa o asistencia sensible al tono, Grok 4.1 representa un gran avance y, en varias pruebas comparativas de la comunidad, fue la aplicación con mejor rendimiento en el momento de su lanzamiento.
CometAPI es una plataforma comercial de agregación de API que ofrece a los desarrolladores acceso REST unificado, al estilo de OpenAI, a cientos de modelos de IA de múltiples proveedores (modelos de aprendizaje automático de texto, generadores de imágenes/vídeo, embeddings y más) a través de una única interfaz consistente. En lugar de configurar SDK independientes o endpoints personalizados para OpenAI, Anthropic, Google, Meta o proveedores de modelos especializados más pequeños, CometAPI permite invocar diferentes modelos modificando las cadenas de modelo y algunos parámetros.
¿Listo para probar?→ Regístrate en CometAPI hoy !
Si quieres conocer más consejos, guías y novedades sobre IA síguenos en VK, X y Discord!