Especificaciones técnicas de GPT-5.4 Mini
| Elemento | GPT-5.4 Mini (estimado a partir de fuentes oficiales + validación cruzada) |
|---|---|
| Familia de modelos | Serie GPT-5.4 (variante “mini” rentable) |
| Proveedor | OpenAI |
| Tipos de entrada | Texto, Imagen |
| Tipos de salida | Texto |
| Ventana de contexto | 400,000 tokens |
| Máx. de tokens de salida | 128,000 tokens |
| Corte de conocimiento | ~31 de mayo de 2024 (hereda el linaje mini) |
| Soporte de razonamiento | Sí (ligero vs GPT-5.4 completo) |
| Compatibilidad con herramientas | Llamadas a funciones, búsqueda web, búsqueda de archivos, agentes (inferido de la familia GPT-5) |
| Posicionamiento | Modelo de alta velocidad y rentable, cercano a la frontera |
¿Qué es GPT-5.4 Mini?
GPT-5.4 Mini es una variante de GPT-5.4 de alta velocidad y coste eficiente, diseñada para cargas de trabajo de alto volumen y sensibles a la latencia. Aporta una parte significativa de las capacidades de razonamiento, programación y multimodalidad de GPT-5.4 a un modelo más pequeño y rápido, optimizado para sistemas a escala de producción.
En comparación con modelos “mini” anteriores, GPT-5.4 Mini se posiciona como un modelo pequeño cercano a la frontera, lo que significa que se acerca al rendimiento del buque insignia mientras reduce drásticamente el coste y el tiempo de respuesta.
Principales características de GPT-5.4 Mini
- Inferencia de alta velocidad: optimizado para aplicaciones de baja latencia como chatbots, copilotos y sistemas en tiempo real
- Ventana de contexto grande (400K): admite documentos largos, flujos de trabajo de múltiples pasos y memoria de agentes
- Solidez en programación y soporte de agentes: diseñado para el uso de herramientas, razonamiento de múltiples pasos y tareas delegadas a subagentes
- Entrada multimodal: acepta entradas tanto de texto como de imagen para flujos de trabajo más ricos
- Escalado rentable: significativamente más barato que GPT-5.4, conservando una sólida capacidad de razonamiento
- Optimización de canalizaciones de agentes: ideal para arquitecturas multimodelo donde los modelos grandes planifican y los mini ejecutan
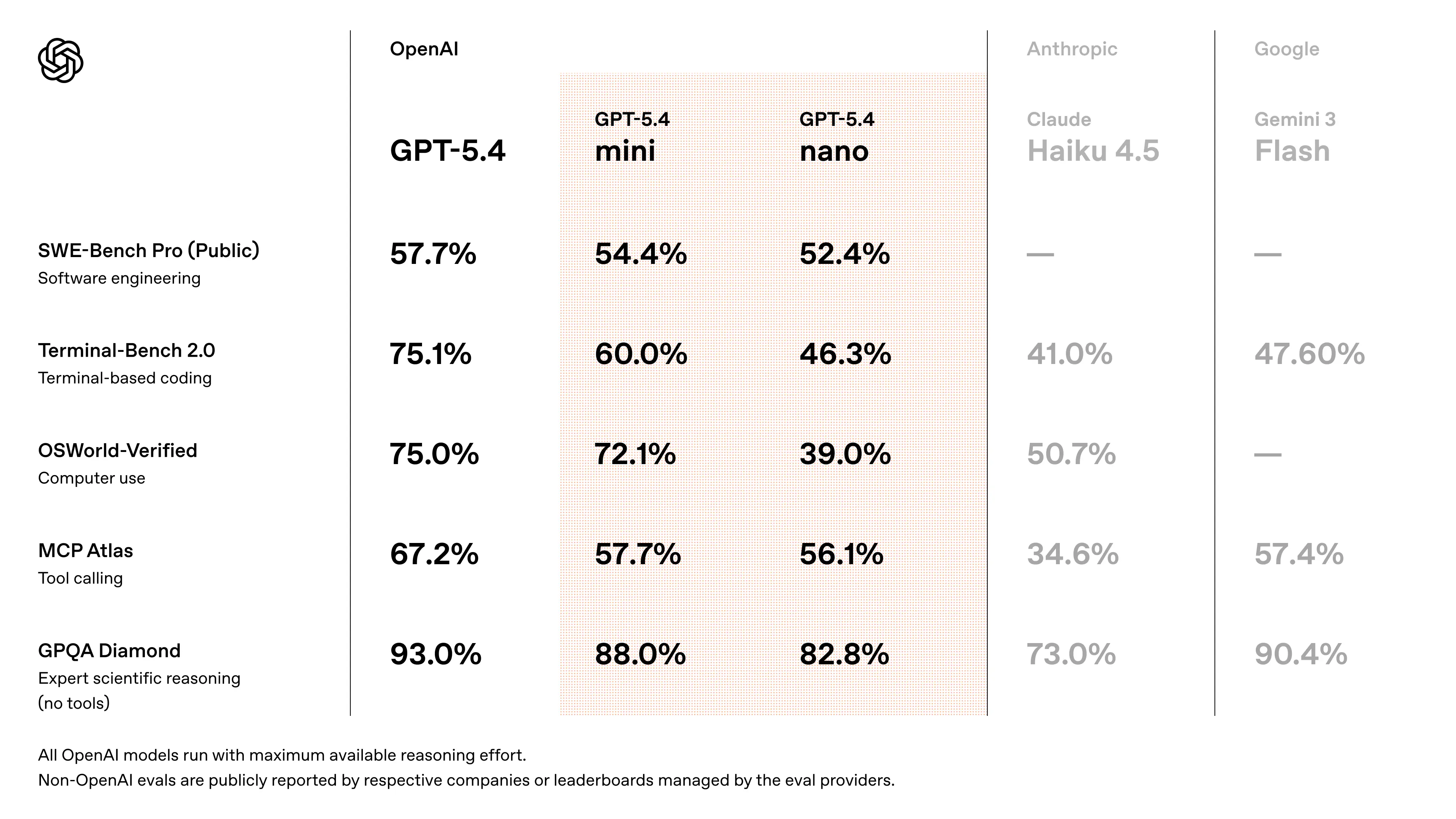
Rendimiento en benchmarks de GPT-5.4 Mini
- Se aproxima al rendimiento de GPT-5.4 en tareas de programación tipo SWE‑Bench (~94–95% del rendimiento del modelo insignia) (estimación con validación cruzada a partir de debates sobre el lanzamiento)
- Mejoras significativas frente a GPT-5 Mini en:
- exactitud de razonamiento
- fiabilidad en el uso de herramientas
- comprensión multimodal
- Diseñado para superar a las generaciones “mini” anteriores en flujos de trabajo de agentes y benchmarks de programación
- mediciones de velocidad: los primeros evaluadores de la API reportan ~180–190 tokens/sec en GPT-5.4 Mini (frente a ~55–120 t/s en variantes GPT-5 mini antiguas, según los modos de prioridad).
👉 Idea clave: GPT-5.4 Mini entrega un rendimiento cercano a la frontera a una fracción del coste y la latencia, lo que lo hace ideal para sistemas escalables.
Casos de uso representativos
- Asistentes y editores de código (plugins de IDE, Copilot): el análisis rápido del contexto, la exploración de bases de código y las completaciones veloces hacen que GPT-5.4 Mini sea ideal para sugerencias en el editor donde el tiempo hasta el primer token importa. GitHub Copilot es una integración temprana.
- Subagentes / trabajadores delegados: donde un agente maestro delega tareas cortas y rápidas (formateo, pasos de razonamiento pequeños, búsquedas tipo grep) a un trabajador barato y veloz. OpenAI posiciona mini/nano para estos roles.
- Automatización de API de alto volumen: generación masiva de código, clasificación automática de tickets, y resumen de registros a escala, donde el coste por llamada y la latencia son las restricciones principales. Las cifras de rendimiento de la comunidad indican ventajas operativas materiales para mini.
- Encapsulación de herramientas y cadenas de herramientas: llamadas a herramientas rápidas donde el modelo orquesta llamadas a herramientas externas (búsqueda, grep, ejecutar pruebas) y devuelve salidas compactas y accionables. La familia GPT-5.4 incluye capacidades mejoradas de “computer use”.
Cómo acceder a la API de GPT-5.4 Mini
Paso 1: Registrarse para obtener una clave de API
Inicie sesión en cometapi.com. Si aún no es usuario, por favor regístrese primero. Inicie sesión en su Consola de CometAPI. Obtenga la clave de API de credenciales de acceso de la interfaz. Haga clic en “Add Token” en el token de API del centro personal, obtenga la clave del token: sk-xxxxx y envíe.

Paso 2: Enviar solicitudes a la API de GPT-5.4 Mini
Seleccione el endpoint “gpt-5.4-mini” para enviar la solicitud de API y establezca el cuerpo de la solicitud. El método de solicitud y el cuerpo se obtienen de la documentación de la API de nuestro sitio web. Nuestro sitio también ofrece pruebas en Apifox para su comodidad. Reemplace <YOUR_API_KEY> con su clave real de CometAPI de su cuenta. La URL base es Chat Completions y Responses.
Inserte su pregunta o solicitud en el campo de contenido: esto es a lo que responderá el modelo. Procese la respuesta de la API para obtener la respuesta generada.
Paso 3: Recuperar y verificar resultados
Procese la respuesta de la API para obtener la respuesta generada. Después del procesamiento, la API responde con el estado de la tarea y los datos de salida.