

Qwen2.5-VL-32B La API ha ganado atención por su rendimiento excepcional en diversas tareas complejas, combinando ambos datos de imagen y texto para una comprensión más profunda del mundo. Desarrollado por AlibabaEste modelo de 32 mil millones de parámetros es una actualización del modelo anterior. Qwen2.5-VL Serie, ampliando los límites de Razonamiento impulsado por IA y comprensión visual.

Descripción general de Qwen2.5-VL-32B
Qwen2.5-VL-32B es un modelo multimodal de vanguardia y código abierto Diseñado para manejar una variedad de tareas que involucran tanto texto como imágenes. Con su 32 mil millones de parámetros, ofrece un arquitectura poderosa para preguntas de reconocimiento de imagen, Razonamiento matemático, generación de diálogo, y mucho más. Su mejorado capacidades de aprendizaje, basado en el aprendizaje de refuerzo, le permite generar respuestas que se alineen mejor con las preferencias humanas.
Funciones y características clave
Qwen2.5-VL-32B demuestra capacidades notables en múltiples dominios:
Comprensión y descripción de imágenes:Este modelo destaca en análisis de imagen, identificando con precisión objetos y escenas. Puede generar descripciones detalladas en lenguaje natural e incluso proporcionar información detallada en los atributos de los objetos y sus relaciones.
Razonamiento matemático y lógica:El modelo está equipado para resolver problemas matemáticos complejos, que van desde geometría al álgebra—mediante el empleo razonamiento de varios pasos con lógica clara y resultados estructurados.
Generación de texto y diálogoCon su modelo de lenguaje avanzado, Qwen2.5-VL-32B genera respuestas coherentes y contextualmente relevantes basadas en texto o imágenes de entrada. También es compatible. diálogo de varios turnos, permitiendo interacciones más naturales y continuas.
Respuesta Visual a Preguntas:El modelo puede responder preguntas relacionadas con el contenido de la imagen, como reconocimiento de objetos y descripción de la escena, proporcionando sofisticadas capacidades de lógica visual e inferencia.
Fundamentos técnicos de Qwen2.5-VL-32B
Para comprender el potencial del Qwen2.5-VL-32B, es fundamental explorar sus principios técnicos. A continuación, se presentan los aspectos clave que contribuyen a su rendimiento:
- Preentrenamiento multimodal:El modelo ha sido entrenado previamente utilizando conjuntos de datos a gran escala que consta de ambos datos de texto e imagenEsto le permite aprender diversas características visuales y lingüísticas, facilitando una comprensión intermodal fluida.
- Arquitectura del transformador:Construido sobre la base robusta Arquitectura transformadora, el modelo aprovecha tanto la codificador y descifrador estructuras para procesar entradas de imágenes y texto, generando resultados de alta precisión. mecanismo de autoatención le permite centrarse en componentes críticos dentro de los datos de entrada, mejorando su precisión.
- Optimización del aprendizaje por refuerzoQwen2.5-VL-32B se beneficia del aprendizaje por refuerzo, donde se ajusta con base en la retroalimentación humana. Este proceso garantiza que las respuestas del modelo sean más precisas. alineado con las preferencias humanas mientras se optimizan múltiples objetivos como la exactitud, lógica e fluidez.
- Alineación visual-lingüística: Mediante aprendizaje contrastivo y estrategias de alineación, el modelo garantiza que ambos características visuales y información textual están debidamente integrados en el espacio lingüístico, lo que lo hace muy eficaz para tareas multimodales.
Destacados Rendimiento
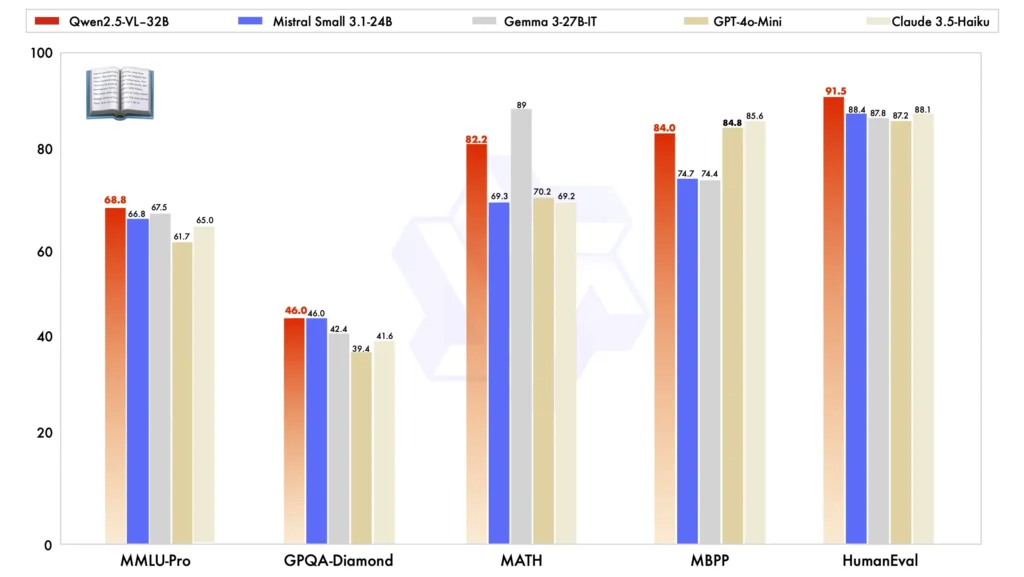
En comparación con otros modelos a gran escala, Qwen2.5-VL-32B se destaca en varios puntos de referencia clave, mostrando su rendimiento superior en ambos multimodal y tareas de texto sin formato:
Comparación de modelos:En comparación con otros modelos como Mistral-Pequeño-3.1-24B y Gemma-3-27B-ITEl Qwen2.5-VL-32B demuestra capacidades significativamente mejoradas. Cabe destacar que incluso... Supera al Qwen2-VL-72B más grande en diversas tareas.
Rendimiento de tareas multimodales:En complejo tareas multimodales como MMMU, MMMU-Pro e MatemáticasVistaQwen2.5-VL-32B se destaca por ofrecer resultados precisos que lo diferencian de otros modelos de tamaño similar.
Punto de referencia MM-MT-Bench:En comparación con su predecesor, Qwen2-VL-72B-Instruct, la nueva versión muestra una mejora significativa, particularmente en su razonamiento logico y razonamiento multimodal capacidades.
Rendimiento de texto simpleEn tareas basadas en texto simple, Qwen2.5-VL-32B ha surgido como el el mejor intérprete En su clase, ofreciendo generación de texto mejorada, razonamiento, y precisión general.
Recursos del proyecto
Para desarrolladores y entusiastas de la IA que deseen explorar más a fondo Qwen2.5-VL-32B, hay varios recursos clave disponibles:
- Website: Proyecto Qwen2.5-VL-32B
- Modelo HuggingFace: HuggingFace Qwen2.5-VL-32B-Instrucciones
Aplicaciones del mundo real
La versatilidad del Qwen2.5-VL-32B lo hace adecuado para una amplia gama de aplicaciones prácticas en diversas industrias:
Servicio al cliente inteligente:El modelo se puede emplear para gestionar automáticamente las consultas de los clientes, aprovechando su capacidad para comprender y generar respuestas basadas en texto e imágenes.
Asistencia educativa:Resolviendo problemas matematicos, interpretando contenido de la imagen, y explicar conceptos, puede mejorar significativamente el proceso de aprendizaje de los estudiantes.
Anotación de imagen:En los sistemas de gestión de contenido, Qwen2.5-VL-32B puede automatizar la generación de subtítulos de imagen y descripciones, lo que lo convierte en una herramienta invaluable para los medios y las industrias creativas.
Conducción autónoma:Al analizar las señales de tráfico y las condiciones del tráfico a través de sus capacidades de procesamiento visual, el modelo puede proporcionar información en tiempo real para mejorar seguridad en la conducción.
Creación de contenidos:En los medios y la publicidad, el modelo puede generar texto Basado en estímulos visuales, ayudando a los creadores de contenido a producir narrativas atractivas para videos y anuncios.
Perspectivas y desafíos futuros
Si bien Qwen2.5-VL-32B representa un gran avance en la IA multimodal, aún existen desafíos y oportunidades por delante. Sintonia FINA el modelo para tareas más específicas, integrándolo con aplicaciones en tiempo real y mejorando su escalabilidad El manejo de conjuntos de datos multimodales más complejos son áreas que requieren investigación y desarrollo continuos.
Además, a medida que se lanzan más modelos de IA con capacidades similares, preocupaciones éticas contenido generado por IA circundante, parcialidad e privacidad de datos Siguen captando la atención. Garantizar que el Qwen2.5-VL-32B y modelos similares se entrenen y utilicen responsablemente será fundamental para su éxito a largo plazo.
Temas relacionados:Comparación de los 8 modelos de IA más populares de 2025
Conclusión
Qwen2.5-VL-32B es una herramienta poderosa en el arsenal de modelos de IA diseñados para abordar tareas multimodales con una precisión y sofisticación impresionantes. Al integrar tecnología avanzada aprendizaje reforzado, arquitectura del transformador e alineación visual-lingüística, no sólo supera los modelos anteriores pero también abre posibilidades interesantes para industrias que van desde educación a conducción autónomaComo tecnología de código abierto, ofrece un enorme potencial para que los desarrolladores y usuarios de IA experimenten, optimicen e implementen en aplicaciones del mundo real.
Cómo llamar a la API Qwen2.5-VL-32B desde CometAPI
1.Iniciar sesión a cometapi.comSi aún no eres nuestro usuario, por favor regístrate primero.
2.Obtener la clave API de credenciales de acceso De la interfaz. Haga clic en "Agregar token" en el token de API del centro personal, obtenga la clave del token: sk-xxxxx y envíela.
-
Obtenga la URL de este sitio: https://api.cometapi.com/
-
Seleccione el punto final Qwen2.5-VL-32B para enviar la solicitud de API y configure el cuerpo de la solicitud. El método y el cuerpo de la solicitud se obtienen de nuestra documentación de la API del sitio webNuestro sitio web también ofrece la prueba Apifox para su comodidad.
-
Procesa la respuesta de la API para obtener la respuesta generada. Tras enviar la solicitud a la API, recibirás un objeto JSON con la finalización generada.