

Gemini Embedding 2 es el primer modelo de embeddings nativamente multimodal de Google que mapea texto, imágenes, audio, video y PDFs a un único espacio vectorial semántico de 3,072 dimensiones (con tamaños de salida configurables). Introduce Matryoshka Representation Learning para ofrecer embeddings anidados/truncados, rendimiento multilingüe mejorado (100+ idiomas) y controles optimizados para embeddings específicos de tarea (p. ej., task:search, task:code).
¿Qué es Gemini Embedding 2?
Gemini Embedding 2 es un modelo de embeddings unificado de Google que mapea múltiples modalidades de entrada —texto, imágenes, audio, video y documentos— a un único espacio vectorial semántico. Cada embedding es (por defecto) un vector de coma flotante de 3,072 dimensiones que representa el significado semántico de la entrada, de modo que los elementos semánticamente similares (independientemente de la modalidad) estén cerca en el espacio vectorial. Las capacidades principales son:
- Amplia cobertura de idiomas y formatos: un único modelo que acepta texto, imágenes, audio, video y documentos y los sitúa en un mismo espacio vectorial semántico. Se documenta que Gemini Embedding 2 captura la intención semántica en 100+ idiomas y acepta formatos de archivo comunes (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), con límites concretos por solicitud (p. ej., hasta un puñado de imágenes o decenas de segundos de audio/video por solicitud; consulta “Cómo usar” abajo).
- Multimodalidad real: un único modelo que acepta texto, imágenes, audio, video y documentos y los sitúa en un mismo espacio vectorial semántico para que puedas comparar o recuperar entre modalidades (p. ej., texto → imagen, audio → texto).
- Gran dimensionalidad por defecto con truncado flexible: el modelo produce vectores de 3072 dimensiones por defecto, pero usa Matryoshka Representation Learning (MRL) para concentrar el contenido semántico más importante en las primeras dimensiones, de modo que puedas truncar a 1536, 768 (o menos) con solo caídas modestas en la calidad de recuperación. Esto reduce los compromisos de almacenamiento y cómputo.
Por qué es importante. Históricamente, los embeddings eran principalmente solo de texto o requerían codificadores separados por modalidad con capas complejas de alineación cruzada. Gemini Embedding 2 elimina esa barrera al admitir nativamente múltiples formatos, de modo que una consulta de texto puede recuperar una imagen o un clip corto por similitud semántica sin transcripción intermedia ni mapeo manual. Eso simplifica RAG (generación aumentada por recuperación), la búsqueda semántica y los pipelines de recuperación multimodal.
Funciones y capacidades clave (lo nuevo)
1. Multimodalidad nativa real (un único espacio de embeddings)
Un único modelo que acepta texto, imágenes, audio, video y documentos y los coloca en un mismo espacio vectorial semántico. Gemini Embedding 2 mapea texto, imágenes, audio, video y documentos en el mismo espacio de embeddings, por lo que la recuperación cruzada (texto→imagen, audio→texto) funciona directamente sin alineación entre modelos. Esto reduce la complejidad del pipeline y simplifica los stacks de RAG (Retrieval-Augmented Generation).
2. Vectores por defecto de 3,072 dimensiones con salida ajustable
Gemini Embedding 2 produce vectores de 3072 dimensiones por defecto, pero usa Matryoshka Representation Learning (MRL) para concentrar el contenido semántico más importante en las primeras dimensiones, de modo que puedas truncar a 1536, 768 (o menos) con solo caídas modestas en la calidad de recuperación. Esto reduce los compromisos de almacenamiento y cómputo.
3. Matryoshka Representation Learning (MRL)
MRL produce embeddings “anidados”, como las muñecas rusas, por lo que los cortes de menor dimensión preservan la semántica de alto nivel. Esto permite a los sistemas elegir un punto operativo (compromiso almacenamiento/precisión) sin mantener varios modelos de embeddings separados. Análisis de blogs iniciales y documentación describen esta técnica como una innovación central para la flexibilidad.
4. Pistas de tarea / objetivos de embedding personalizados
La API acepta pistas task (p. ej., task:search, task:code retrieval, task:semantic-similarity) para que el modelo pueda optimizar la geometría del embedding para relaciones específicas del downstream—similar al condicionamiento por tarea usado en sistemas de embeddings anteriores, pero extendido a entradas multimodales.
5. Amplitud de idioma y modalidad
Se documenta que Gemini Embedding 2 captura la intención semántica en 100+ idiomas y acepta formatos de archivo comunes (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), con límites concretos por solicitud (p. ej., hasta un puñado de imágenes o decenas de segundos de audio/video por solicitud—ver “Cómo usar” abajo).
Benchmarks de rendimiento
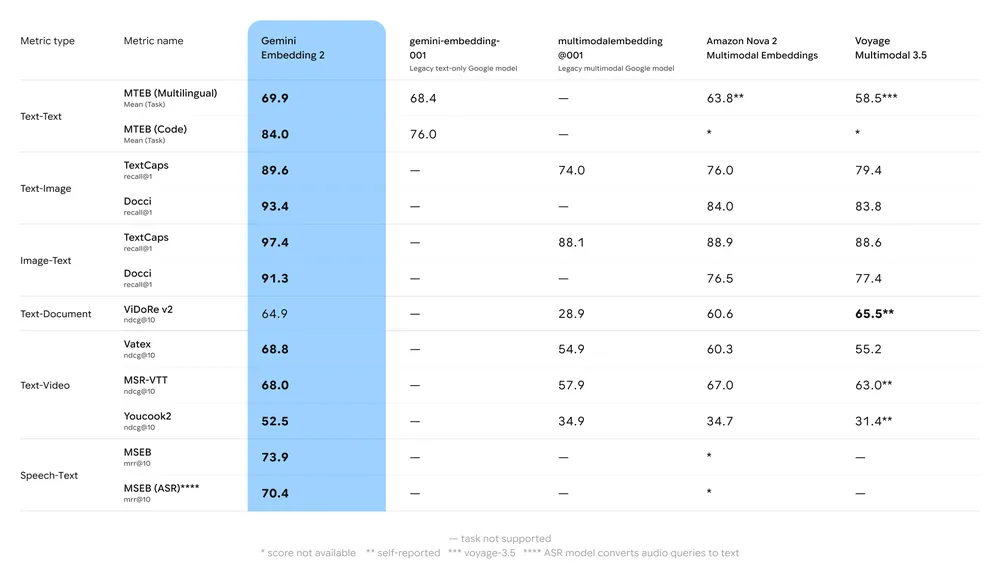
Resumen clave de benchmarks:
- MTEB (Massive Text Embedding Benchmark): Se reporta una fuerte posición en los rankings multilingües de MTEB para tareas en inglés y multilingües; los análisis muestran una mejora significativa frente a los modelos de embeddings previos de Gemini y muchas alternativas propietarias.
- Recuperación multimodal: Supera o iguala a los principales embeddings monomodales cuando se usa para similitud cruzada (p. ej., recuperación texto→imagen), gracias al entrenamiento multimodal nativo.
- Latencia y rendimiento: Generación de embeddings alojada en la nube, pero los casos sensibles a la latencia pueden preferir vectores truncados o modelos de embeddings ligeros alternativos para necesidades en el edge.
Gemini Embedding 2 vs gemini-embedding-001 y text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Earlier Gemini embedding (text-only variants) — GA earlier. | Announced Jan 2024 (text-only GA). |
| Modalities supported | Text, images, audio, video, documents (PDF) — unified vector space. | Text (primarily). | Text only (high-quality multilingual). |
| Default embedding dim. | 3072 (MRL / truncation recommended: 1536, 768). | 3072 (for large) — text only. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s on MTEB; shows 68.17 at 1536 in vendor table (see docs). | gemini-embedding-001 reported ~68.32 mean in some leaderboards. | ~64.6 (MTEB average reported by OpenAI for text-embedding-3-large). |
| Native audio/video support | Yes (direct audio/video embedding). | No (text only). | No (text only). |
| Typical use cases | Multimodal retrieval, RAG, semantic search across file types, speech retrieval, video search. | Text retrieval, multilingual RAG. | Text retrieval, semantic search, RAG — strong multilingual text performance. |
Especificaciones técnicas y límites
Tamaño de embedding predeterminado y ajustable
- Por defecto: 3,072 dimensiones.
- Ajustable: el parámetro
output_dimensionalitypermite solicitar salidas de menor dimensión para ahorrar almacenamiento/CPU. Los casos con almacenes vectoriales masivos a menudo reducen las dimensiones a 512–1,024 por razones de costo, aceptando cierta pérdida de precisión.
Modalidades admitidas y límites por solicitud
- Imágenes: PNG, JPEG — hasta 6 imágenes por solicitud (límites reportados por el proveedor).
- Video: MP4, MOV — el proveedor reporta hasta ~128 segundos por video para embeddings en una sola solicitud.
- Audio: MP3, WAV — el proveedor reporta hasta ~80 segundos por entrada de audio.
- Documentos: PDFs — hasta 6 páginas por solicitud (según el proveedor).
- Límite de tokens para contenido textual: el modelo admite entradas de tokens grandes; existen límites prácticos por solicitud (consulta la documentación de la API y las cuotas de Vertex AI).
Disponibilidad y acceso
- Vista previa pública: Gemini Embedding 2 se lanzó como vista previa pública y está disponible a través de Gemini API y Vertex AI de Google Cloud para uso experimental inmediato
Preguntas frecuentes (FAQ)
Q1: ¿Qué modalidades admite Gemini Embedding 2?
A: Texto, imágenes (PNG/JPEG), video (MP4/MOV), audio (MP3/WAV) y documentos PDF, todos mapeados a un mismo espacio vectorial semántico.
Q2: ¿Cuál es el tamaño de vector por defecto en Gemini Embedding 2?
A: El defecto es 3,072 dimensiones. Puedes solicitar una dimensionalidad de salida menor a través de la API.
Q3: ¿Está disponible Gemini Embedding 2 ahora?
A: Sí — se anunció como vista previa pública y está disponible mediante Gemini API y Vertex AI (consulta el id del modelo gemini-embedding-2-preview y el registro de cambios actual).
Q4: ¿Cómo se compara con los embeddings de otros proveedores?
A: Pruebas de proveedores independientes informan que Gemini Embedding 2 se ubica entre los mejores modelos propietarios para texto multilingüe y muestra rendimiento de última generación en varias tareas multimodales. Las clasificaciones exactas varían por tarea y dataset; prueba con tus propios datos.
Q5: ¿Necesito transcribir audio para usar Gemini Embedding 2?
A: No — Gemini Embedding 2 puede aceptar audio directamente y producir embeddings sin transcribir antes a texto, habilitando recuperación semántica de audio de extremo a extremo.
Q6: ¿Cómo reduzco los costos de almacenamiento para vectores de 3,072 dimensiones?
A: Las opciones incluyen solicitar una menor output_dimensionality, usar float16/cuantización/PQ y almacenar representaciones comprimidas en tu base de datos vectorial. Publicaciones del proveedor ofrecen flujos de trabajo y buenas prácticas.
¿Qué sigue — debería adoptarlo ahora?
Gemini Embedding 2 es un gran paso hacia la unificación de la recuperación multimodal y simplifica arquitecturas que antes requerían recuperadores separados para texto, visión y voz. Puntos clave para decidir la adopción:
- Adopta cuanto antes si tu producto necesita recuperación cruzada robusta (texto↔imagen/video/audio), o si mantener múltiples recuperadores monomodales es costoso y complejo.
- Haz un piloto ahora si quieres evaluar el truncado MRL y medir costo vs. calidad (mantén un despliegue híbrido: 1536 como principal, 3072 para re-ranking).
- Espera si tu carga es extremadamente sensible a costos y solo requieres recuperación de texto: los mejores modelos solo de texto (p. ej., OpenAI text-embedding-3-large) siguen siendo competitivos y a veces más baratos según tu pipeline y contrato.
Los desarrolladores pueden acceder a Gemini Embedding 2 y a la API de OpenAI text-embedding-3 a través de CometAPI ahora. Para comenzar, explora las capacidades del modelo en el Playground y consulta la guía de la API para instrucciones detalladas. Antes de acceder, asegúrate de haber iniciado sesión en CometAPI y obtenido la clave de API. CometAPI ofrece un precio muy inferior al oficial para ayudarte a integrar.
¿Listo para empezar?→ Sign up for cometapi today
Si quieres conocer más consejos, guías y noticias sobre IA, síguenos en VK, X y Discord!