
.webp&w=3840&q=75)
GLM-5.1 representa un cambio decisivo en el panorama de la IA. A medida que las empresas chinas de IA aceleran la comercialización mientras abren el código de capacidades de frontera, este modelo reduce la brecha con líderes propietarios como GPT-5.4 de OpenAI, Claude Opus 4.6 de Anthropic y Gemini 3.1 Pro de Google—particularmente en ingeniería de software del mundo real. Entrenado sobre la misma arquitectura MoE de 744B parámetros que GLM-5 pero fuertemente optimizado para flujos de trabajo agénticos, sobresale donde la mayoría de los LLM fallan: tareas largas, ambiguas e iterativas que requieren planificación, experimentación, depuración y autocorrección a lo largo de miles de llamadas a herramientas.
Ahora, CometAPI integra GLM-5.1 y GLM-5, y los desarrolladores también pueden ver otros modelos líderes occidentales y acceder a ellos a un precio de API muy bajo (lo cual también es una ventaja de CometAPI frente a otros competidores).
¿Qué es GLM-5.1?
GLM-5.1 es el nuevo modelo insignia de Z.ai y la apuesta más reciente de la compañía por el trabajo de software de estilo agente y horizonte largo. En palabras de Z.ai, está diseñado para tareas que necesitan ejecución continua en lugar de respuestas de una sola vez, y se posiciona como un modelo que puede planificar, ejecutar, refinar y entregar dentro de una sola ejecución extendida. Las notas de lanzamiento de Z.ai señalan que GLM-5.1 se construyó con ajuste fino supervisado multi-turno, aprendizaje por refuerzo y un marco de evaluación de calidad de proceso, y que mejora la estabilidad, la consistencia y el uso de herramientas en tareas prolongadas.
Ese posicionamiento importa porque GLM-5.1 no se vende simplemente como “otro modelo de chat”. Está orientado a flujos de trabajo de ingeniería donde los modelos necesitan mantener un objetivo en mente, manejar pasos intermedios y recuperarse de errores sin perder el hilo; se presenta como un modelo para la planificación autónoma, la ejecución sostenida, la corrección de errores y la iteración de estrategias, lo cual es una historia de producto muy distinta a la de un asistente casual o un copiloto de código de contexto corto.
Un detalle práctico útil: GLM-5.1 es solo texto, está soportado en el GLM Coding Plan y puede usarse en agentes de programación populares como Claude Code y OpenClaw, lo que lo hace especialmente relevante para equipos que quieren que un modelo se integre en un flujo de trabajo de desarrollo existente en lugar de reemplazarlo.
Especificaciones técnicas principales (heredadas y refinadas de GLM-5):
- Arquitectura: Mixture-of-Experts (MoE) con 744 mil millones de parámetros totales y aproximadamente 40 mil millones de parámetros activos por inferencia.
- Ventana de contexto: 203K–204.8K tokens (con soporte de hasta 131K tokens de salida).
- Mejoras clave: DeepSeek Sparse Attention (DSA) para un manejo eficiente de contextos largos y reducción de costos de despliegue; infraestructura avanzada de aprendizaje por refuerzo asíncrono (mediante el framework “slime” de Z.ai) para un post-entrenamiento más efectivo.
- Disponibilidad: Pesos abiertos (licencia MIT en Hugging Face a través de zai-org/GLM-5.1), acceso por API mediante la plataforma de Z.ai y agregadores como CometAPI, e integrado en las herramientas de GLM Coding Plan (compatible con Claude Code / OpenClaw).
A diferencia de modelos GLM anteriores centrados en inteligencia general o “vibe coding” breve, GLM-5.1 apunta a agentes autónomos de nivel producción. Puede planificar, ejecutar, evaluar, depurar e iterar de forma independiente en proyectos de ingeniería complejos durante horas sin intervención humana—capacidades que lo posicionan como competidor directo de agentes de programación especializados de Anthropic y OpenAI.
El lanzamiento coincidió con un aumento de precio de API de ~10% (tokens de entrada ~$0.54/M, salida ~$4.40/M), pero sigue siendo dramáticamente más barato que equivalentes como Opus 4.6 de Anthropic (250–470% más caro).
Rendimiento de GLM-5.1 en benchmarks
Z.ai posiciona a GLM-5.1 como el modelo de código abierto más sólido del mundo y un top-3 global en programación agéntica. Los datos de rendimiento provienen de evaluaciones oficiales en SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 y escenarios personalizados de horizonte largo.
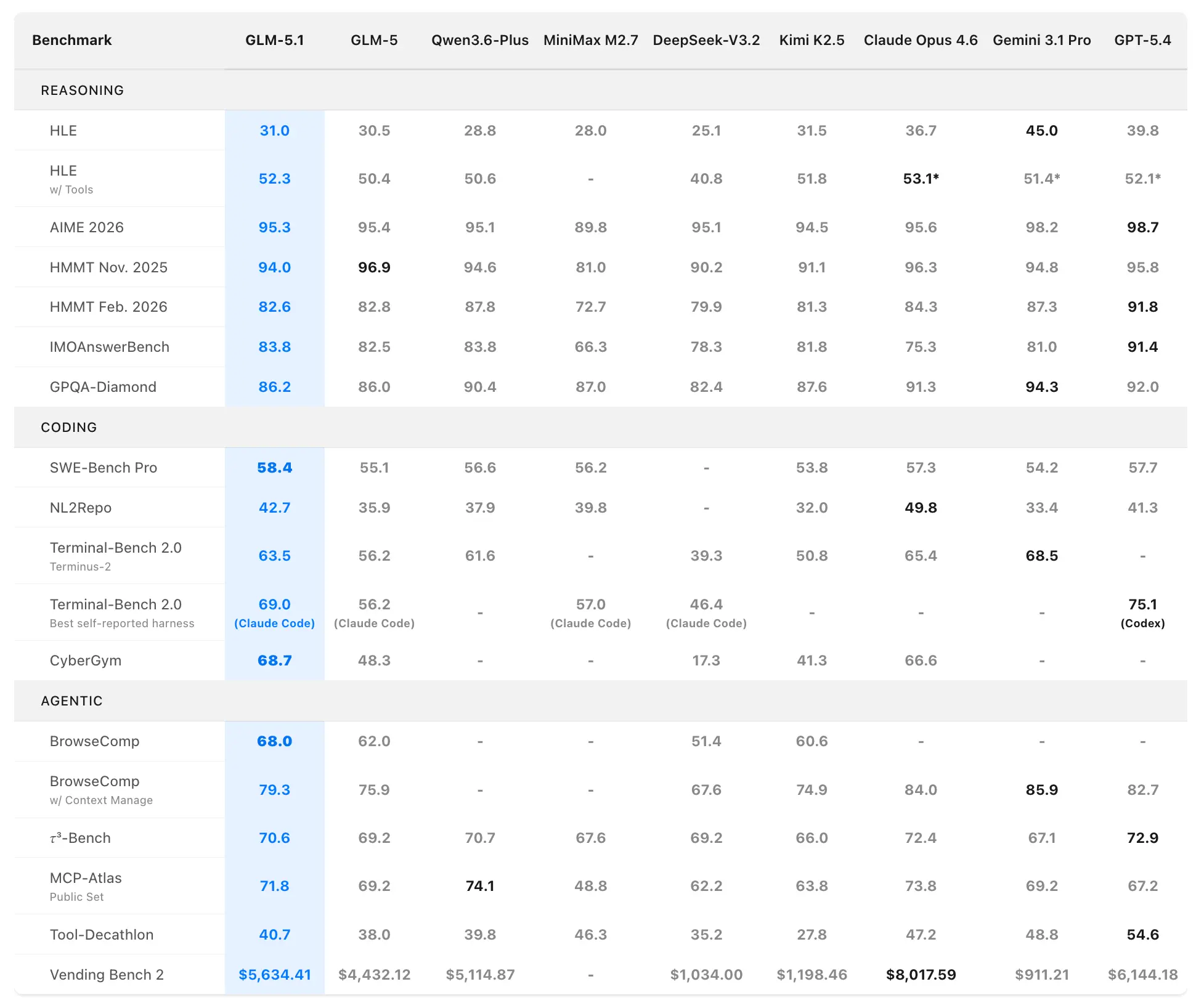
Benchmarks de programación y agentes
SWE-Bench Pro (tareas realistas de ingeniería de software que requieren navegación por repositorio, edición de código y verificación funcional):
- GLM-5.1: 58.4 (nuevo estado del arte)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 es el primer modelo nacional (chino) y de código abierto en reclamar el primer lugar en este riguroso benchmark, que refleja de cerca los flujos de trabajo de desarrolladores profesionales.
NL2Repo (lenguaje natural a generación de repositorio completo):
- GLM-5.1: 42.7 (amplia ventaja sobre el 35.9 de GLM-5)
- Los modelos competitivos oscilan entre 32.0–49.8 (los líderes específicos varían según el harness).
Terminal-Bench 2.0 (tareas de terminal y sistemas del mundo real):
- Harness Terminus-2: GLM-5.1 63.5 (vs. GLM-5 56.2)
- Mejor (auto-reportado) (Claude Code): hasta 69.0.
En una evaluación de coding harness separada (estilo Claude Code), GLM-5.1 obtuvo 45.3—alcanzando 94.6% del 47.9 de Claude Opus 4.6 y una mejora del 28% sobre el 35.4 de GLM-5.
Clasificación compuesta: #1 de código abierto, #1 modelo chino, #3 global en SWE-Bench Pro + NL2Repo + Terminal-Bench.
Rendimiento en tareas de horizonte largo: el verdadero diferenciador
Los benchmarks estándar miden rendimiento de una sola vez o en sesiones cortas. GLM-5.1 brilla en ejecuciones autónomas prolongadas:
- VectorDBBench Optimization (600+ iteraciones, 6,000+ llamadas a herramientas): Partiendo de un esqueleto en Rust, GLM-5.1 rediseñó iterativamente indexación, compresión, enrutamiento y poda, alcanzando 21.5k QPS (6× el mejor resultado previo a 50 turnos de 3,547 QPS de Claude Opus 4.6) manteniendo ≥95% de recall en SIFT-1M. Exhibió progreso en “escalones” con avances estructurales cada 100–200 iteraciones.
- KernelBench Level 3 (optimización completa de modelo de ML, 1,000+ turnos): Media geométrica de aceleración de 3.6× en 50 problemas complejos (superando el 1.49× de torch.compile max-autotune). GLM-5.1 siguió mejorando mucho después de que GLM-5 se estancara; solo Claude Opus 4.6 lo superó con 4.2×.
- Linux Desktop Web App Build (8+ horas, abierto): Con solo una instrucción en lenguaje natural y sin código inicial, GLM-5.1 construyó de forma autónoma un entorno de escritorio estilo Linux funcional—con barra de tareas, ventanas, interacciones y pulido—donde modelos previos solo producían esqueletos básicos.
Estos resultados demuestran la capacidad de GLM-5.1 para mantener coherencia, autoevaluarse, revisar estrategias y escapar de óptimos locales en horizontes extremadamente largos—capacidades que Z.ai diseñó explícitamente para sistemas agénticos del mundo real.
¿En qué se diferencia GLM-5.1 de GLM-5?
GLM-5 y GLM-5.1 están estrechamente relacionados, pero no se posicionan igual. GLM-5 es el modelo base anterior de Z.AI para Ingeniería agéntica. Está diseñado para ingeniería de sistemas complejos y tareas de agentes de alcance largo, con capacidades SOTA de programación y agentes con pesos abiertos, y rendimiento en programación que se acerca a Claude Opus 4.5 en escenarios de programación reales. Obtiene 77.8 en SWE-bench Verified y 56.2 en Terminal Bench 2.0.
GLM-5.1, en cambio, se plantea como el siguiente paso hacia tareas de horizonte largo y una ejecución sostenida más confiable; mejora la estabilidad, la consistencia y el uso de herramientas en tareas extendidas, y está mejor alineado con Claude Opus 4.6 en general. En otras palabras, GLM-5 es el modelo base centrado en ingeniería anterior, mientras que GLM-5.1 es el buque insignia más orientado a la resistencia en la tarea.
También hay diferencias de arquitectura y entrenamiento en la generación GLM-5 que ayudan a explicar el salto. GLM-5 pasó de 355B parámetros (32B activados) a 744B parámetros (40B activados), incrementó los datos de preentrenamiento de 23T a 28.5T, añadió un marco de aprendizaje por refuerzo asíncrono e integró DeepSeek Sparse Attention para preservar la calidad en texto largo mientras mejora la eficiencia. Esos detalles están ligados a GLM-5, pero forman la base sobre la que GLM-5.1 parece construirse.
GLM-5.1 vs otros modelos de frontera
GLM-5.1 destaca como el candidato de código abierto más fuerte, ofreciendo una relación precio/rendimiento convincente.
Tabla comparativa: Principales benchmarks de programación y agentes (abril de 2026)
| Modelo | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Puntuación en Coding Harness | ¿Sostenido en horizonte largo? | ¿Código abierto? | Precio aprox. de API (entrada/salida por M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% de Opus) | Sí (600+ iter, 8 h) | Sí | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limitado | Sí | Inferior (antes del alza) |
| GPT-5.4 | 57.7 | — | — | — | Fuerte | No | Superior |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | El más fuerte | No | ~250–470% más caro |
| Gemini 3.1 Pro | 54.2 | — | — | — | Bueno | No | Superior |
Veredicto: GLM-5.1 gana en accesibilidad de código abierto, costo y métricas específicas de programación de horizonte largo. Se mide de tú a tú con líderes de código cerrado en escenarios agénticos mientras democratiza capacidades de frontera.
Escenarios de aplicación de GLM-5.1
1) Ingeniería de software autónoma
GLM-5.1 resulta más atractivo cuando la tarea se parece a un sprint de ingeniería real: leer la base de código, planificar el cambio, implementarlo, probarlo, corregir regresiones y seguir iterando hasta que el resultado sea estable. Las notas de lanzamiento de Z.ai enfatizan explícitamente la planificación autónoma, la ejecución sostenida, la corrección de errores y la iteración de estrategias, lo que hace que este modelo se sienta hecho a medida para agentes de programación y pipelines de entrega de software.
2) Flujos de trabajo de agentes de larga duración
Si tu caso de uso implica muchas llamadas a herramientas, flujos de trabajo largos de múltiples pasos o autocorrección repetida, el diseño de GLM-5.1 es una gran opción. La documentación destaca la invocación de herramientas, la salida estructurada, la integración con MCP y el soporte de streaming de herramientas, todo lo cual es útil cuando un modelo no solo responde, sino que opera dentro de un sistema mayor.
3) Trabajo de conocimiento y reportes empresariales
GLM-5.1 también se posiciona para tareas de productividad de oficina como flujos de PowerPoint, Word, PDF y Excel. Z.ai afirma que mejora la organización de contenido complejo, el diseño de layout, la salida estructurada y el acabado visual, lo que lo convierte en una opción plausible para generación de informes, materiales didácticos, resúmenes de investigación y otros trabajos documentales.
4) Prototipado front-end y artefactos
Z.ai indica que GLM-5.1 es adecuado para generación de sitios web, páginas interactivas y prototipado front-end, con menos estructura templada y mejor calidad de finalización de tareas. Esto sugiere un buen encaje para equipos de producto que necesitan un puente rápido del brief al prototipo, especialmente cuando el prototipo debe ser usable y no solo estético.
5) Conversación compleja y seguimiento de instrucciones
Aunque el titular es la programación, también se describe a GLM-5.1 como más fuerte en preguntas y respuestas abiertas, instrucciones complejas e interacción multi-turno. Eso lo vuelve útil para flujos tipo asistente en los que el modelo debe mantener restricciones, revisar salidas y preservar el contexto a lo largo de conversaciones extensas.
Conclusión: por qué GLM-5.1 importa en 2026
GLM-5.1 no es solo otro lanzamiento incremental—marca la llegada de una IA agéntica de código abierto realmente capaz. Al sobresalir en los benchmarks de ingeniería del mundo real más difíciles mientras sigue siendo asequible y abierto, Z.ai ha elevado el listón para toda la industria. Ya seas desarrollador independiente, equipo empresarial o investigador, GLM-5.1 ofrece una autonomía inigualable para tareas de programación de horizonte largo a una fracción del costo de los propietarios.
¿Listo para probarlo? Consulta el modelo GLM-5.1 en CometAPI, el repositorio en Hugging Face o GLM Coding Plan para acceso inmediato.