

Wan2.7-Image d’Alibaba, lancé le 1er avril 2026, marque une avancée majeure dans la génération visuelle par IA. Ce modèle unifié intègre la création texte‑vers‑image, l’édition interactive, la composition multi‑images et la compréhension sémantique au sein d’une seule architecture. Contrairement aux chaînes séparées traditionnelles pour la génération et l’édition, il élimine des incohérences telles que les « visages IA standardisés », le texte brouillé et les couleurs imprévisibles.
Créateurs, designers, marketeurs et entreprises obtiennent désormais des résultats photoréalistes, parfaitement conformes aux instructions, avec moins d’itérations. Le modèle prend en charge jusqu’à 12 images séquentielles, 9 fusions de références, le rendu de texte en 12 langues (jusqu’à 3,000 tokens) et un contrôle au niveau du pixel.
Qu’est-ce que Wan2.7-Image ?
Wan2.7-Image est le modèle d’image unifié phare du Tongyi Lab d’Alibaba, au sein de la série Wan (Tongyi Wanxiang). Il gère des workflows visuels de bout en bout : génération texte‑vers‑image, transformation image‑vers‑image, édition à base de commandes et affinements interactifs au niveau du pixel — le tout dans un espace latent partagé.
Sorti le 1er avril 2026, il s’appuie sur les modèles vidéo Wan 2.x (qui ont dominé les benchmarks VBench) tout en recentrant l’objectif sur la précision d’image. Il s’attaque directement à la « fatigue esthétique » due aux visages répétitifs, aux couleurs instables et au faible alignement des prompts courants dans les outils d’IA antérieurs. La famille du modèle comprend deux noms qui comptent le plus pour les utilisateurs : wan2.7-image et wan2.7-image-pro. La version standard est optimisée pour une vitesse de génération plus rapide, tandis que la version Pro vise une qualité professionnelle, avec prise en charge 4K haute définition.
Différenciateur clé : architecture unifiée. Les modèles traditionnels utilisent des étapes déconnectées (encodeur → diffusion → décodeur), exigeant un inpainting séparé pour les éditions. Wan2.7-Image cartographie directement la sémantique dans un espace partagé, permettant une véritable compréhension plutôt qu’un simple appariement de motifs de pixels.
Pourquoi Wan2.7-Image compte (contexte sectoriel)
Les outils d’images IA traditionnels souffrent de :
| Problème | Explication |
|---|---|
| Flux de travail fragmenté | Outils séparés pour la génération, l’édition, l’inpainting |
| « syndrome du visage IA » | Visages humains répétitifs et irréalistes |
| Faible alignement aux instructions | Les prompts ne sont pas suivis avec précision |
| Mauvais rendu du texte | Texte déformé ou illisible |
| Sorties multi‑images incohérentes | Les personnages changent d’une image à l’autre |
Wan2.7-Image répond directement à ces limites grâce à une architecture unifiée + couche de compréhension sémantique.
5 fonctionnalités clés de Wan2.7-Image
1. Personnalisation d’avatar au niveau de l’ossature pour des visages vraiment uniques
Wan2.7-Image excelle à « un visage unique par individu ». Il offre un contrôle fin sur la structure osseuse, la forme des yeux (en amande, « phoenix », enfoncés, bouffis, souriants), les contours du visage et les détails subtils. Cela élimine le problème des « visages IA standardisés » qui a longtemps affecté les modèles précédents.

Exemple de prompt : « Portrait photoréaliste d’une femme est-asiatique de 28 ans, visage ovale, yeux en amande, léger sourire, texture de peau détaillée, éclairage naturel. » Les résultats montrent une diversité saisissante, idéale pour des influenceurs virtuels, des PNJ de jeux ou l’image de marque personnalisée.
2. Contrôle précis de la palette de couleurs
L’une des fonctionnalités les plus pratiques est le nouveau contrôle de palette de couleurs. Alibaba indique que les utilisateurs peuvent saisir des codes couleurs et des proportions spécifiques pour reproduire des styles artistiques ou verrouiller des couleurs de marque. La documentation API formalise cela via un paramètre color_palette acceptant 3 à 10 couleurs, avec 8 recommandées. Pour les équipes de marque, c’est l’une des fonctionnalités les plus clairement orientées entreprise de cette version. Finies les dérives chromatiques — une cohérence parfaite sur l’ensemble des campagnes.
Citation officielle : « Dites adieu à la génération de couleurs aléatoires. Obtenez des ratios de couleurs précis et donnez vie à votre vision créative. » — Tongyi Wanxiang.
3. Rendu de texte multilingue avancé (12 langues, 3,000 tokens)
Rendez du texte ultra‑long, des tableaux, formules, graphiques et infographies avec une clarté digne de l’impression (équivalent A4). Prend en charge le chinois, l’anglais, le japonais, le coréen et 8 autres langues. Articles académiques, affiches, étiquettes produits et bannières multilingues atteignent une lisibilité quasi parfaite — corrigeant une faiblesse historique de l’IA.
4. Édition interactive au pixel près avec sélection rectangulaire
Utilisez des boîtes englobantes (editRegions) ou des outils de sélection rectangulaire pour des modifications ciblées. Téléversez jusqu’à 9 références et donnez des instructions telles que « changer l’arrière‑plan en coucher de soleil sur la plage tout en préservant le visage, la pose et les vêtements ». La précision au pixel garantit la préservation de l’identité.
5. Génération compositionnelle multi‑images (jusqu’à 12 images séquentielles)
Le modèle est conçu pour aller au‑delà de la génération sur un seul prompt. Alibaba indique que les utilisateurs peuvent travailler avec jusqu’à neuf images de référence et générer jusqu’à 12 images simultanément, ce qui est idéal pour des storyboards cohérents, l’architecture et des séries e‑commerce. Le flux « cliquer pour éditer » permet de sélectionner des zones spécifiques et de les modifier avec une précision au pixel, et la documentation de l’API ajoute une édition interactive précise via un paramètre de boîte englobante pour les éditions locales.
Comment fonctionne Wan2.7-Image ? (approfondissement technique)
Alibaba décrit Wan2.7-Image comme un cadre qui fait le pont entre langage et visuels en s’entraînant sur de grands jeux de données diversifiés. En termes simples, le modèle n’apprend pas seulement à « dessiner » des images ; il apprend aussi comment les prompts se cartographient sur la structure visuelle, la composition, l’éclairage et le placement du texte. C’est ce qui lui permet d’interpréter l’intention utilisateur plus précisément qu’un système texte‑vers‑image basique.
L’API montre aussi que le modèle est conçu pour l’entrée multimodale. En pratique, les requêtes sont envoyées via une structure de messages en un seul tour, et le contenu peut inclure des éléments texte et image. Pour l’édition, les utilisateurs peuvent transmettre plusieurs images plus des instructions telles que « déplacer », « remplacer » ou « fusionner » pour guider le résultat. C’est un signe clair que Wan2.7 est conçu comme un système à prompts et références plutôt qu’un générateur simple en un seul coup.
La documentation expose également un réglage de mode de réflexion. Activé par défaut, il peut améliorer la qualité de sortie, mais Alibaba note qu’il augmente le temps de génération. C’est un indice utile sur le flux du modèle : des sorties de plus haute qualité peuvent nécessiter plus de temps d’inférence interne, notamment lorsque la requête est riche en texte ou visuellement complexe.
Wan2.7-Image adopte un cadre unifié de génération‑édition dans un espace latent partagé :
- Étape d’entrée : Prompt texte (jusqu’à 3,000 tokens) + images de référence optionnelles (jusqu’à 9).
- Analyse sémantique & mode de réflexion (améliorés en Pro) : un raisonnement en chaîne analyse la composition, les relations spatiales, l’éclairage et la logique avant la génération de pixels.
- Cartographie dans un espace latent partagé : la sémantique se projette directement sur des caractéristiques visuelles — sans fossés encodeur/décodeur déconnectés.
- Inférence unifiée : la génération ou l’édition se déroule en un flux optimisé. Les régions d’édition utilisent des boîtes englobantes ; les palettes de couleurs imposent des ratios.
- Sortie : images haute fidélité (768–2048×2048 en standard ; 4K en Pro), avec options JPG/PNG/WEBP, seeds pour la reproductibilité et contrôles de sécurité.
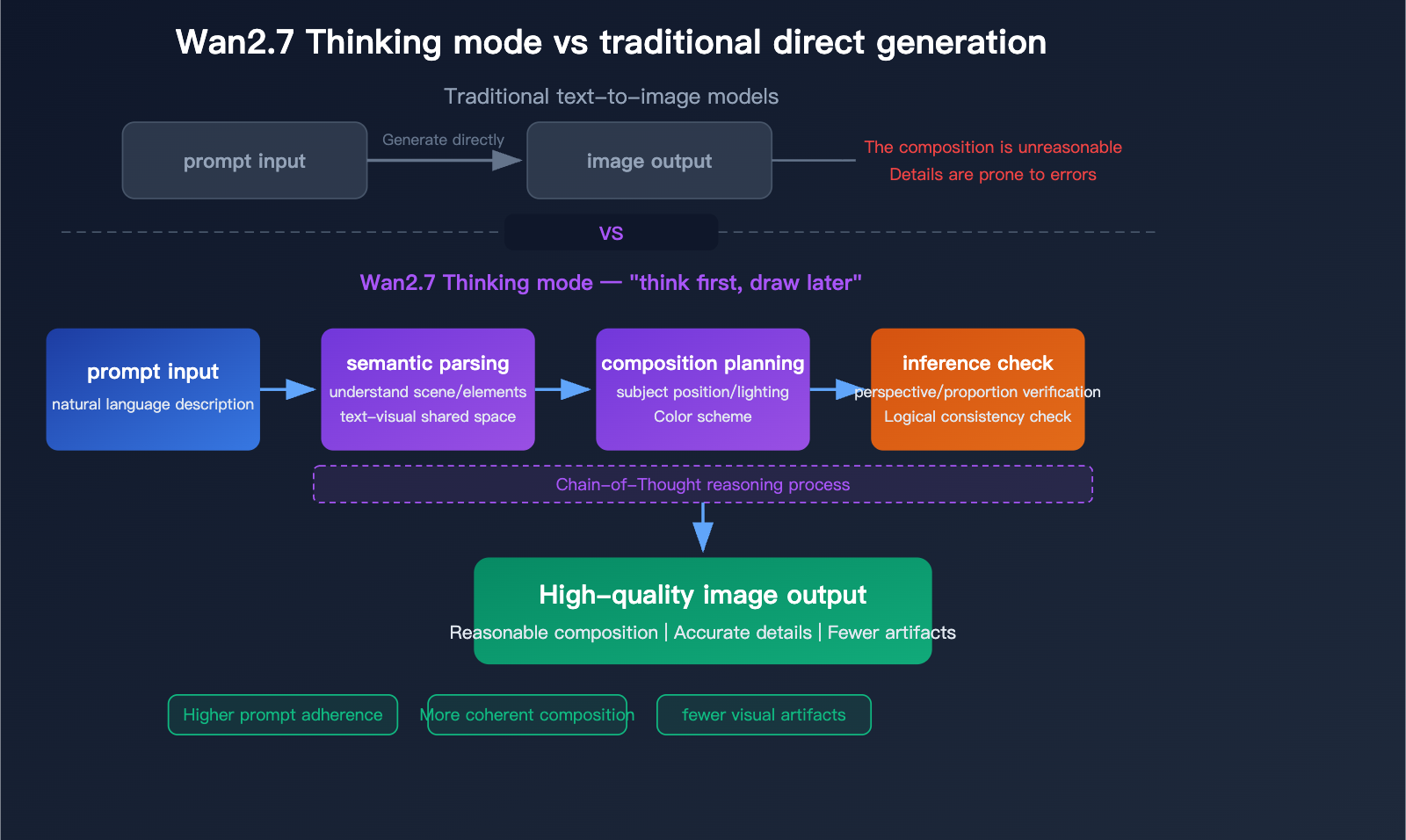
Analyse approfondie de Wan2.7-Image-Pro : un nouveau standard pour la génération d’images par IA en qualité 4K, mode de réflexion et rendu de texte en 12 langues - Blog Apiyi.com
Le schéma du mode de réflexion (Pro) illustre l’analyse sémantique → la planification de composition → la vérification d’inférence, produisant moins d’artefacts et une meilleure adhérence au prompt qu’une génération directe.
Un entraînement sur des jeux de données diversifiés permet une compréhension profonde de l’intention, de l’éclairage et de la mise en page. L’apprentissage à long contexte (référencé dans des études arXiv) alimente la gestion de textes étendus.
Wan2.7-Image vs Wan2.7-Image-Pro : différences clés
Les deux versions sont lancées simultanément, mais la Pro cible des besoins professionnels.
| Fonctionnalité | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Idéal pour |
|---|---|---|---|
| Résolution max | 2048×2048 | 4096×4096 (4K) | Impression/production (Pro) |
| Mode de réflexion | Disponible (par défaut plus rapide) | Amélioré/par défaut avec raisonnement plus profond | Scènes complexes (Pro) |
| Stabilité de composition | Solide | Compréhension sémantique supérieure | Projets commerciaux (Pro) |
| Vitesse vs qualité | Itérations plus rapides | Fidélité supérieure, temps légèrement plus long | Prototypage (Standard) |
| Cas d’usage | Créateurs grand public, contenu social | Conception d’entreprise, académique/impression | Échelle vs précision |
La version Standard convient au prototypage rapide ; la Pro délivre du 4K prêt à imprimer avec une cohérence supérieure.
Comment utiliser Wan2.7-Image (pas à pas)
1. Accès à la plateforme
Disponible via :
- Alibaba Cloud (plateforme BaiLian)
- Outils officiels Wanxiang
- CometAPI
2. Choisir le mode de workflow
Mode A : Texte‑vers‑image
Exemple de prompt :
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Mode B : Édition d’image
- Téléverser une image
- Sélectionner une zone
- Saisir une instruction
Exemple :
Replace background with a futuristic city
Mode C : Composition multi‑images
- Téléverser plusieurs références
- Définir des règles de composition
3. Affiner les paramètres
- Palette de couleurs
- Cohérence de style
- Rendu de texte
4. Exporter le résultat
- Images haute résolution
- Ressources prêtes pour un usage commercial
Performances de benchmark et comparaison avec les concurrents
Dans des tests en aveugle de préférence humaine, Wan2.7-Image dépasse GPT-Image-1.5 en qualité texte‑vers‑image et égale ou dépasse Nano Banana Pro en rendu de texte, photoréalisme et connaissances du monde.
Tableau de comparaison :
| Modèle | Rendu de texte | Suivi des instructions | Personnalisation d’avatar | Références multi‑images | Génération/édition unifiées | Résolution | Open‑source/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Excellent (12 langues) | Supérieur (mode de réflexion) | Niveau « ossature » | 9 | Oui | 2K–4K | Oui/API |
| Midjourney V8 | Bon | Modéré | Artistique fort | Limité | Non | Élevée | Discord uniquement |
| FLUX | Bon | Fort (simple) | Bon | Limité | Non | Élevée | Oui |
| DALL-E 3 | Modéré | Bon | Modéré | Non | Non | 2K | API |
| Nano Banana Pro | Fort | Édition forte | Bon | Fort | Partiel | Élevée | Fermé |
Wan2.7-Image domine par son workflow unifié, son texte multilingue et son contrôle précis — particulièrement précieux pour les marchés non anglophones et les chaînes professionnelles.
CometAPI est une plateforme d’agrégation tout‑en‑un d’API de grands modèles, offrant une intégration et une gestion fluides des services API. Elle prend en charge de multiples API de génération d’images, telles que GPT-image-1.5, série Nano Banana, Midjourney, et Qwen Image Series etc., à un prix inférieur à celui du site officiel.
Qui devrait utiliser Wan2.7-Image
Wan2.7-Image est particulièrement pertinent pour les équipes qui ont besoin de vitesse et de flexibilité plutôt que de simples créations ponctuelles. Cela inclut les marketeurs orientés performance, designers produit, studios e‑commerce, équipes de contenu social et agences produisant de nombreuses variantes à partir d’un même brief. La prise en charge du multi‑entrée image, de la génération multi‑sorties et de l’édition à base d’instructions le rend particulièrement attractif pour des workflows où comptent cohérence, rapidité et contrôle des prompts.
Cas d’usage concrets
- Jeux/Divertissement : générer 100 PNJ uniques en quelques minutes.
- Marketing/E‑commerce : carrousels cohérents avec des palettes de marque exactes.
- Éducation/Académie : affiches prêtes à imprimer avec formules et tableaux.
- Agences de design : storyboards et retours client via édition interactive.
Les gains de productivité viennent de moins d’itérations et d’une intégration fluide des références.
Conclusion :
Alibaba Wan2.7-Image redéfinit la créativité par IA en unifiant génération, édition et compréhension. Ses 5 fonctionnalités clés, son espace latent partagé et ses améliorations Pro offrent des résultats professionnels que les concurrents peinent encore à égaler. Qu’il s’agisse de prototyper du contenu social ou de produire des visuels académiques prêts à l’impression, il offre une précision et une efficacité inégalées.
Commencez dès aujourd’hui sur wan.video ou via l’API dans CometAPI. Pour les développeurs et les entreprises, la combinaison de puissance, d’accessibilité et de supériorité étayée par les données fait de Wan2.7-Image le leader évident des modèles d’images IA unifiés pour 2026 et au‑delà.