

Gemini 3 Pro (Google/DeepMind) et Claude Sonnet 4.5 (Anthropic) sont des modèles phares de l’ère 2025, optimisés pour des workflows agentiques, à long horizon et utilisant des outils — et tous deux mettent fortement l’accent sur le codage. Leurs points forts revendiqués divergent : Google présente Gemini 3 Pro comme un raisonneur multimodal généraliste qui excelle aussi en codage agentique, tandis qu’Anthropic positionne Sonnet 4.5 comme le meilleur modèle codage/agent au monde, avec un taux de réussite particulièrement élevé sur les tâches d’édition/outillage et des agents de longue durée.
Réponse courte d’emblée : les deux modèles sont de tout premier plan pour les tâches d’ingénierie logicielle fin 2025. Claude Sonnet 4.5 devance légèrement sur certains indicateurs de bancs “pure ingénierie logicielle”, tandis que Gemini 3 Pro (aperçu) de Google est une puissance multimodale et agentique plus large — surtout lorsque le contexte visuel, l’usage d’outils, le long contexte et les workflows d’agents profonds comptent.
J’utilise actuellement les deux modèles, et chacun a des avantages différents dans l’environnement de développement. Je vais maintenant les comparer dans cet article.
Gemini 3 Pro n’est disponible que pour les abonnés Google AI Ultra et les utilisateurs payants de l’API Gemini. Toutefois, la bonne nouvelle est que CometAPI, en tant que plateforme IA tout-en-un, a intégré Gemini 3 Pro, et vous pouvez l’essayer gratuitement.
Qu’est-ce que Gemini 3 Pro Preview et quelles sont ses fonctionnalités phares ?
Vue d’ensemble
Gemini 3 Pro (disponible initialement sous gemini-3-pro-preview) est le dernier LLM “frontière” de Google/DeepMind dans la famille Gemini 3. Il est positionné comme un modèle à haut raisonnement, multimodal, optimisé pour les workflows agentiques (c’est-à-dire des modèles capables d’utiliser des outils, d’orchestrer des sous-agents et d’interagir avec des ressources externes). Il met l’accent sur un raisonnement renforcé, la multimodalité (images, trames vidéo, PDF) et des contrôles d’API explicites pour la profondeur de “pensée” interne.
Points clés (orientés développeurs)
- Utilisation agentique d’outils : appel de fonctions et outils intégrés (exécution de code, ancrage sur le Web, contexte fichiers & URL, utilisation du terminal/des outils).
- Prise en charge de la “pensée” / chaîne de raisonnement : primitives de “pensée” pour la planification multi-étapes et signatures internes de raisonnement pour rendre le raisonnement multi-étapes plus explicite.
- Entrées/sorties multimodales : texte, images, audio, vidéo, et sorties structurées avec gestion de long contexte.
- Outil d’exécution de code & intégrations IDE : un outil hébergé d’exécution de code et des intégrations dans les IDE ainsi que le nouvel IDE agentique Google Antigravity pour le codage autonome collaboratif. Antigravity est actuellement en aperçu public.
- Contrôles de pensée élevée/étendue (paramètre
thinking_level) pour échanger latence contre un raisonnement interne plus profond.highest la valeur par défaut pour Gemini 3 Pro. - Contrôles multimodaux granulaires (
media_resolution) pour ajuster la fidélité image/vidéo vs coût — utile lorsque vous voulez que le modèle lise du petit texte dans des captures d’écran ou analyse des trames.
Où Gemini 3 Pro excelle pour le codage
- Développement agentique : orchestration de tâches multi-étapes à travers éditeur/terminal/navigateur. Le système d’artefacts d’Antigravity + les outils de Gemini en font un excellent choix pour les travaux de fonctionnalités plus vastes et l’automatisation.
- Combinaisons visuel + code : correction de bugs UI à partir de captures d’écran, génération de harnais de tests UI ou conversion d’images de design en code grâce à une forte compréhension image-vers-code.
Qu’est-ce que Claude Sonnet 4.5 et quelles sont ses principales fonctionnalités ?
Claude Sonnet 4.5 est la version 2025 d’Anthropic que l’éditeur présente comme son modèle le plus performant pour le codage, les workflows agentiques et “l’utilisation des ordinateurs” (contrôle d’outils, navigateurs, terminaux, feuilles de calcul, etc.). Il met l’accent sur une meilleure capacité d’édition, la réussite avec les outils, une pensée étendue, la cohérence d’agents longue durée (30+ heures d’exécution autonome démontrées) et des taux d’erreurs d’édition de code plus bas par rapport aux générations précédentes. Anthropic qualifie Sonnet 4.5 de son “meilleur modèle de codage” avec de grands gains en fiabilité d’édition et en cohérence de tâches à long horizon.
Fonctionnalités clés (orientées développeurs)
- Haute précision en codage sur des benchmarks d’ingénierie réels : Anthropic rapporte des scores de pointe sur SWE-bench Verified et revendique de fortes améliorations des taux d’erreurs d’édition et de la réussite des agents basés sur des outils.
- Améliorations agentiques et d’utilisation de l’ordinateur : Sonnet 4.5 est conçu pour exécuter plusieurs outils (bash, édition de fichiers, automatisation du navigateur) et orchestrer des sous-agents via le Claude Agent SDK. Anthropic met en avant “30+ heures” de travail multi-étapes continu dans ses évaluations internes.
- Grandes fenêtres de contexte : 200k jetons par défaut pour la plupart des clients, avec une fenêtre de contexte de 1M de jetons disponible en bêta pour les organisations de niveau supérieur (la même capacité 1M que propose Gemini en aperçu).
- Outil d’exécution de code & API fichiers : des outils intégrés au produit et à l’API permettent une exécution de code sûre, la création/modification de fichiers et des boucles d’exécution de tests.
Où Sonnet 4.5 excelle pour le codage
- Benchmarks d’ingénierie logicielle pure et tâches de code structurées (génération de tests unitaires, refactorisation à l’échelle d’un dépôt) où la rigueur algorithmique et la stabilité à long horizon comptent.
- CLIs orientés code et flux “assistant de code” comme Claude Code, où l’intégration étroite au terminal et l’analyse de dépôt sont fournies nativement.
Tableau de comparaison rapide
| Aspect | Gemini 3 Pro (aperçu) | Claude Sonnet 4.5 |
|---|---|---|
| Modèle / statut de sortie | gemini-3-pro-preview — modèle frontière Google / DeepMind (aperçu). Sorti en nov. 2025 (aperçu). | claude-sonnet-4-5 — modèle frontière de classe Sonnet (GA / annoncé le 29 sept. 2025). |
| Positionnement cible (codage & agents) | Modèle frontière généraliste avec emphase sur le raisonnement + la multimodalité + les workflows agentiques ; présenté comme le meilleur modèle de Google pour le codage/agents. | Spécialisé pour le codage, l’agentique à long horizon et l’utilisation de l’ordinateur (le “meilleur pour le codage & les agents complexes” chez Anthropic). |
| Fonctionnalités clés pour développeurs | Contrôle thinking_level pour un raisonnement interne plus profond ; intégrations d’outils Google natives (ancrage via la recherche, exécution de code, contexte fichiers/URL) ; variante image dédiée pour les workflows texte+image. | SDKs d’agents, intégration VS Code (Claude Code), outils fichiers & exécution de code, améliorations d’agents à long horizon (testés explicitement pour des exécutions multi-heures). Accent sur les workflows itératifs édition/exécution/tests et le checkpointing. |
| Fenêtre de contexte (entrée / sortie) | 1,000,000 jetons en entrée / 64k jetons en sortie pour gemini-3-pro-preview | 1,000,000 jetons en entrée / 64k jetons en sortie |
| Tarification (barème publié) | $2 / $12 par 1M de jetons (entrée / sortie) pour le palier <200k ; tarifs plus élevés au-delà de 200k (les docs montrent $4 / $18 pour >200k). | Barème publié par Anthropic : $3 / $15 par 1M de jetons (entrée / sortie) pour Sonnet 4.5 ; |
| Capacité multimodale (vision/vidéo/audio) | Prise en charge multimodale complète : texte, images, audio, trames vidéo avec paramètres de résolution image/vidéo configurables ; gemini-3-pro-image-preview dédié. Fort accent sur l’OCR/extraction visuelle pour UIs/captures d’écran côté codage. | Prend en charge les entrées vision (texte+image) et exploite la vision pour les workflows de codage ; l’accent principal est l’intégration agentique (utiliser le contexte visuel dans les flux d’agents plutôt que la parité en génération d’images). |
| Performances agentiques à long horizon & persistance | Primitives de “pensée” pour un raisonnement interne multi-étapes explicite ; forts scores en math/raisonnement & raisonnement multimodal profond. Très bon pour la décomposition de tâches algorithmiques complexes. Idéal pour un raisonnement lourd en une seule réponse + analyse multimodale. | Anthropic met en avant la cohérence agentique à long horizon — tests internes où Sonnet 4.5 maintient un usage d’outils cohérent pendant 30+ heures et améliore la stabilité des agents continus vs générations précédentes. Bon choix pour l’automatisation persistante et les workflows d’agents type CI. |
| Qualité de sortie pour le codage (modifications, tests, fiabilité) | Très fort en raisonnement single-shot + génération de code ; outils intégrés pour exécuter du code via l’outillage Google ; excellents résultats sur des benchmarks algorithmiques selon l’éditeur. Avantage pratique lorsque le workflow mêle spécifications visuelles + code. | Conçu pour des boucles itératives éditer→exécuter→tester ; Sonnet 4.5 met en avant une fiabilité de “patching” améliorée (tentatives parallèles / techniques de scoring pour sélectionner des patchs robustes) et un outillage soutenant les workflows développeurs itératifs (checkpoints, tests). |
Comment comparent leurs architectures et capacités de base ?
Architecture et intention de conception (haut niveau)
Gemini 3 Pro : présenté comme un modèle de fondation multimodal, généraliste, avec une ingénierie explicite pour la “pensée” et l’usage d’outils : l’accent est mis sur le raisonnement profond, la compréhension vidéo/audio et l’orchestration agentique via un appel de fonctions intégré et des environnements d’exécution de code. Google présente Gemini 3 Pro comme “le plus intelligent” de la famille, optimisé pour un large éventail de tâches au-delà du code (même si le codage agentique est une priorité).
Claude Sonnet 4.5 : optimisé spécifiquement pour les workflows agentiques et le code : Anthropic met l’accent sur le suivi d’instructions, la fiabilité des outils, la compétence d’édition/correction et la gestion d’état à long horizon. L’objectif d’ingénierie est de minimiser les éditions destructrices ou hallucinées et de rendre robustes les interactions informatiques réelles.
À retenir : Gemini 3 Pro est présenté comme un généraliste de premier plan poussé sur le raisonnement multimodal et l’intégration agentique ; Sonnet 4.5 est présenté comme un spécialiste du codage et de l’usage d’outils agentiques avec des garanties accrues d’édition/correction.
Outillage et intégrations
- Gemini : jeu d’outils Google intégré incluant ancrage via la recherche, recherche de fichiers, exécution de code, et paramètres image/vidéo de premier ordre ; paramètre
thinking_levelpour contrôler le compromis calcul/latence interne. Intégration profonde à l’infrastructure Google, pratique pour les équipes déjà sur Google Cloud. - Claude : SDK d’agents robuste et emphase sur la stabilité d’exécutions longues (cohérence 30+ heures pour Sonnet selon Anthropic). Anthropic expose également l’exécution de code, des APIs fichiers et une nouvelle UX de “checkpoints” d’édition dans Claude Code et l’extension VS Code — des fonctionnalités qui améliorent de manière tangible les workflows de codage itératifs.
Que disent les spécifications techniques et les benchmarks ?
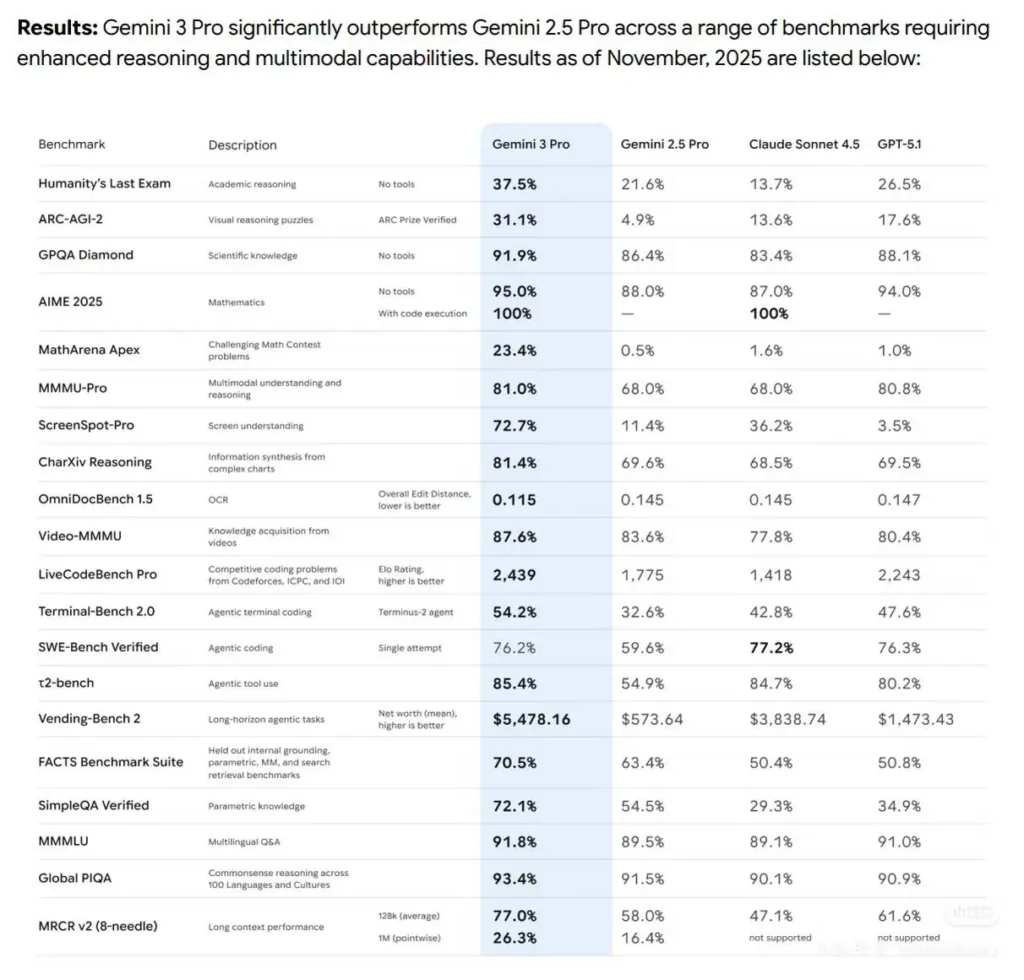
Les benchmarks varient légèrement selon l’évaluateur et la configuration (tentative unique vs multi-tentatives, accès aux outils, paramètres de “pensée” étendue). Ci-dessous, une analyse de données de benchmark sur la capacité de codage :
SWE-bench Verified (tests d’ingénierie logicielle réels)
Claude Sonnet 4.5 (rapporté par Anthropic) : 77.2% (budget de pensée 200k ; 78.2% en configuration 1M). Anthropic rapporte également un score 82.0% à haut calcul en utilisant des tentatives parallèles/échantillonnage par rejet.
Gemini 3 Pro (rapport DeepMind / tableaux associés) : ~76.2% tentative unique sur SWE-bench (tableau éditeur). Les classements publics varient (Gemini et Sonnet se disputent de faibles marges).
Terminal-Bench & tâches agentiques
Gemini 3 Pro : les chiffres de banc terminal/agentique (tableau éditeur) montrent de solides performances (par ex., Terminal-Bench 54.2% dans le tableau éditeur), compétitifs avec les atouts agentiques de Sonnet.
Sonnet 4.5 : excelle en orchestration d’outils agentiques (Anthropic rapporte des gains substantiels sur OSWorld et des benchmarks de type Terminal, et souligne des performances sur des tâches continues plus longues).
À retenir : les deux modèles sont très proches sur les benchmarks modernes de compréhension et génération de code ; Sonnet 4.5 a un léger avantage sur certaines suites de vérification d’ingénierie logicielle (chiffres publiés par Anthropic), tandis que Gemini 3 Pro est extrêmement compétitif et mène souvent sur les classements multimodaux et certains concours de codage. Toujours valider avec la configuration d’évaluation exacte (accès aux outils, taille de contexte, budgets de pensée), car ces paramètres modifient sensiblement les scores.
Comment comparent leurs capacités multimodales ?
Vision & gestion des images
- Gemini 3 Pro : contrôles multimodaux fins avec
media_resolutionpour images/vidéo (budgets de jetons bas/moyen/haut par image/trame), génération/édition d’images (modèle d’aperçu image séparé) et consignes explicites pour l’OCR/le détail visuel. Cela rend Gemini particulièrement performant lorsque les tâches de codage exigent la lecture de captures d’écran, de maquettes UI ou de trames vidéo. - Claude Sonnet 4.5 : prend en charge la multimodalité texte+image et les intégrations produits d’Anthropic (applications Claude) exposent des workflows visuels ; l’accent de Sonnet 4.5 est d’intégrer le contexte visuel dans les workflows agentiques plutôt que la parité en synthèse d’images.
Quand la multimodalité importe pour le codage
Si votre workflow repose fortement sur des captures d’écran d’UI, des spécifications de design en images ou des démonstrations vidéo que le modèle doit analyser pour produire ou modifier du code, les contrôles dédiés de résolution d’images de Gemini et la variante de génération d’images peuvent constituer un avantage pratique. Si votre pipeline est une automatisation pilotée par agents (clics, exécution de commandes, édition de fichiers à travers des outils), le SDK d’agents de Claude et l’outillage d’exécution de code sont de premier ordre.
Raisonnement avancé & planification à long horizon — lequel est meilleur ?
Sonnet 4.5 : endurance et alignement
Sonnet 4.5 peut maintenir un travail cohérent pendant plus de 30 heures sur des tâches complexes multi-étapes (planification, recherche, rédaction juridique, tâches de code longue durée). Cette endurance, conjuguée à l’accent d’Anthropic sur l’alignement, rend Sonnet attractif pour une automatisation de bout en bout où le modèle doit garder trace des objectifs et maintenir un comportement sûr.
Gemini 3 Pro : raisonnement profond + orchestration d’agents
Gemini 3 Pro introduit une variante “Deep Think” et des API de pensée internes plus riches pour la planification multi-étapes, couplées à l’IDE agentique de Google. En pratique, cela signifie que Gemini peut à la fois planifier et exécuter des étapes agentiques à travers des outils (éditeur, shell, web). Si votre automatisation requiert un accès à des outils externes avec création d’artefacts, l’outillage agentique intégré de Gemini (Antigravity) est un atout majeur. Remarque : Deep Think échange latence contre profondeur.
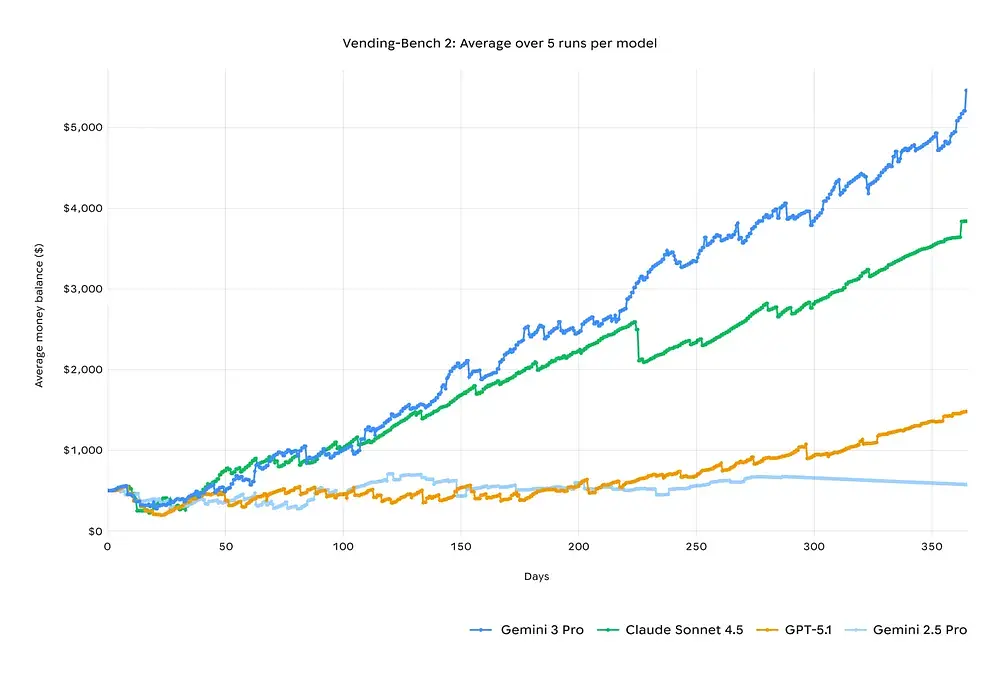
Comparaison de planification à long horizon : Vending-Bench 2
Dans le test de simulation “Vending-Bench 2”, Gemini 3 a surpassé Claude 4.5 en dirigeant une entreprise virtuelle pendant une année complète tout en demeurant rentable. Dans les tests de court terme, les données de Gemini 3 Pro et de Claude 4 Sonnet étaient similaires, mais l’écart s’est accentué sur des périodes d’évaluation plus longues.
Différence pratique
- Pour les tâches de haut raisonnement en une seule passe (débogage algorithmique complexe, preuves logiques profondes intégrées au code),
thinking_levelde Gemini et Deep Think promettent une plus grande profondeur de réponse unique. - Pour l’automatisation longue durée pilotée par outils (agents persistants exécutant de nombreuses commandes, écrivant des tests, itérant et gérant l’état), l’orientation long-horizon de Claude Sonnet 4.5 et son SDK d’agents sont des différenciateurs forts.
Comment l’accès API et la tarification se comparent pour un usage développeur ?
Gemini 3 Pro (Google) — accès et tarification
- Accès : l’aperçu de Gemini 3 Pro est disponible via Google AI Studio et Vertex AI (model garden). Les SDK incluent google-genai pour Python/JS/Go/etc., plus des couches compatibles OpenAI pour faciliter la migration, avec des endpoints REST et l’appel de fonctions / des outils d’exécution de code. Antigravity fournit une surface IDE qui utilise Gemini 3 Pro en aperçu.
- Prix : tarification d’aperçu indiquée dans la documentation Google : $2 / $12 par 1M de jetons (entrée / sortie) pour le palier <200k ; tarifs plus élevés au-delà de 200k (exemples dans la doc montrant $4 / $18 pour >200k).
Claude Sonnet 4.5 — accès et tarification
- APIs & SDKs : Anthropic fournit l’API Claude, le Claude Agent SDK pour construire des workflows agentiques, des APIs fichiers et des outils d’exécution de code (extension VS Code native, améliorations Claude Code et une fonctionnalité de “checkpoint”).
- Prix : fenêtre de contexte 200k jetons par défaut, fenêtre 1M jetons en bêta pour l’entreprise ; tarification $3 / $15 par 1M de jetons (respectivement entrée/sortie)
En tant que développeur, vous devriez choisir un modèle selon vos besoins et ses caractéristiques, pas seulement le moins cher. Si la tâche peut être gérée par deux modèles, décidez en fonction du contexte.
Si vous souhaitez utiliser deux modèles simultanément, je recommande CometAPI, qui fournit à la fois l’API Gemini 3 Pro Preview et l’API Claude Sonnet 4.5, et est proposée à 20% du prix officiel.
| Gemini 3 Pro Preview | GPT-5.1 | |
| Input Tokens | $1.60 | $2.4.00 |
| Output Tokens | $9.60 | $12.00 |
Conclusion
Gemini 3 Pro (aperçu) et Claude Sonnet 4.5 sont tous deux des choix à l’état de l’art pour des assistants de codage fin 2025. Sonnet 4.5 devance Gemini sur des benchmarks spécifiques de vérification d’ingénierie logicielle et en endurance sur les tâches à long horizon, tandis que Gemini 3 Pro apporte une compréhension multimodale plus robuste et un outillage agentique profond capable d’exécuter dans des environnements éditeur/terminal/navigateur. Le bon choix dépend de votre besoin principal : raisonnement pur sur le code et vérification (Sonnet), ou développement multimodal, agentique et augmenté par des outils (Gemini). Pour un déploiement de niveau entreprise, beaucoup d’équipes adopteront raisonnablement une approche hybride, en utilisant le modèle le plus fort pour chaque étape du workflow de développement.
Les développeurs peuvent accéder à l’API Gemini 3 Pro Preview et à l’API Claude Sonnet 4.5 via CometAPI. Pour commencer, explorez les capacités des modèles de CometAPI dans le Playground et consultez le guide de l’API pour des instructions détaillées. Avant d’y accéder, assurez-vous d’être connecté à CometAPI et d’avoir obtenu la clé d’API. CometAPI proposent un prix bien inférieur au prix officiel pour vous aider à intégrer.
Ready to Go?→ Free trial of Gemini 3 pro and GPT-5.1 models !
Si vous souhaitez plus d’astuces, de guides et d’actualités sur l’IA, suivez-nous sur VK, X et Discord !