

Le nom de code GPT-5.3“Garlic” est décrit, dans des fuites et des articles, comme la prochaine version incrémentale/itérative de la série GPT-5.x, destinée à combler des lacunes en raisonnement, en programmation et en performance produit pour OpenAI, en réponse aux pressions concurrentielles de Gemini (Google) et Claude (Anthropic).
OpenAI expérimente une itération GPT-5.x plus dense et plus efficiente, axée sur un raisonnement renforcé, une inférence plus rapide et des workflows à contexte allongé, plutôt que sur une augmentation pure du nombre de paramètres. Il ne s’agit pas simplement d’une nouvelle itération de la série Generative Pre-trained Transformer ; c’est une contre-offensive stratégique. Né d’un « Code Red » interne déclaré par le PDG Sam Altman en décembre 2025, « Garlic » représente un rejet du dogme « plus grand, c’est mieux » qui a gouverné le développement des LLM pendant un demi-décennie. Au lieu de cela, il mise tout sur une nouvelle métrique : la densité cognitive.
Qu’est-ce que GPT-5.3 « Garlic » ?
GPT-5.3 — nom de code « Garlic » — est décrit comme la prochaine étape itérative dans la famille GPT-5 d’OpenAI. Les sources cadrent la fuite en positionnant Garlic non pas comme un simple checkpoint ou un ajustement de jetons, mais comme un raffinement ciblé de l’architecture et de l’entraînement : l’objectif est d’extraire des performances de raisonnement supérieures, une meilleure planification multi‑étapes et un comportement amélioré sur long contexte, à partir d’un modèle plus compact et efficient à l’inférence, plutôt que de s’appuyer uniquement sur l’échelle brute. Ce cadrage s’aligne sur les tendances plus larges du secteur vers des conceptions de modèles « denses » ou « haute efficacité ».
Le surnom « Garlic » — un départ marqué des noms de code célestes (Orion) ou botaniques‑sucrés (Strawberry) du passé — serait une métaphore interne délibérée. Tout comme une seule gousse d’ail peut relever un plat entier plus puissamment que des ingrédients plus volumineux et fades, ce modèle est conçu pour fournir une intelligence concentrée sans la lourde surcharge computationnelle des géants de l’industrie.
La genèse du « Code Red »
L’existence de Garlic ne peut être dissociée de la crise existentielle qui l’a engendrée. Fin 2025, OpenAI s’est retrouvé en « position défensive » pour la première fois depuis le lancement de ChatGPT. Gemini 3 de Google avait pris la tête des benchmarks multimodaux, et Claude Opus 4.5 d’Anthropic était devenu la norme de facto pour les workflows de codage complexes et agentiques. En réponse, la direction d’OpenAI a mis en pause des projets périphériques — y compris des expériences de plateforme publicitaire et des extensions d’agents grand public — pour se concentrer entièrement sur un modèle capable de porter une « frappe tactique » contre ces concurrents.
Garlic est cette frappe. Il n’est pas conçu pour être le plus grand modèle du monde ; il est conçu pour être le plus intelligent par paramètre. Il fusionne les lignes de recherche de projets internes antérieurs, notamment « Shallotpeat », en incorporant des corrections de bogues et des gains d’efficacité en pré‑entraînement qui lui permettent de boxer bien au‑dessus de sa catégorie.
Quel est l’état actuel des itérations observées du modèle GPT-5.3 ?
À la mi‑janvier 2026, GPT-5.3 se trouve dans les dernières étapes de validation interne, une phase souvent décrite dans la Silicon Valley comme un « hardening ». Le modèle est actuellement visible dans des journaux internes et a été testé ponctuellement par des partenaires entreprises sélectionnés sous des accords de non‑divulgation stricts.
Itérations observées et intégration de « Shallotpeat »
La route vers Garlic n’a pas été linéaire. Des mémos internes divulgués du Chief Research Officer Mark Chen suggèrent que Garlic est en réalité un composite de deux pistes de recherche distinctes. Au départ, OpenAI développait un modèle au nom de code « Shallotpeat », destiné à être une mise à jour incrémentale directe. Toutefois, durant le pré‑entraînement de Shallotpeat, les chercheurs ont découvert une méthode novatrice de « compression » des schémas de raisonnement — en enseignant essentiellement au modèle à écarter plus tôt les voies neuronales redondantes durant l’entraînement.
Cette découverte a conduit à l’abandon de la sortie autonome de Shallotpeat. Son architecture a été fusionnée avec la branche plus expérimentale « Garlic ». Le résultat est une itération hybride qui possède la stabilité d’un variant GPT‑5 mûr mais l’efficacité de raisonnement explosive d’une nouvelle architecture.
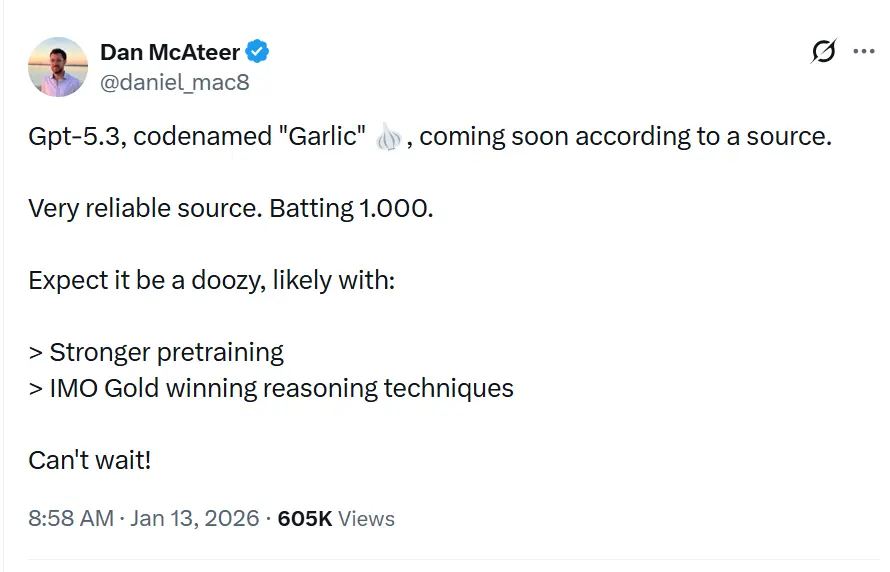
Quand peut-on inférer la date de sortie ?
Prédire les dates de sortie d’OpenAI est notoirement difficile, mais le statut « Code Red » accélère les calendriers standard. En se basant sur la convergence des fuites, des mises à jour fournisseurs et des cycles des concurrents, on peut trianguler une fenêtre de lancement.
Fenêtre principale : T1 2026 (janvier - mars)
Le consensus parmi les initiés est un lancement en T1 2026. Le « Code Red » a été déclaré en décembre 2025, avec une directive de publier « dès que possible ». Étant donné que le modèle est déjà en vérification/validation (la fusion avec Shallotpeat ayant accéléré le calendrier), une sortie fin janvier ou début février semble la plus plausible.
Le déploiement « bêta »
On pourrait voir un lancement échelonné :
- Fin janvier 2026 : une version « preview » pour des partenaires sélectionnés et des utilisateurs ChatGPT Pro (éventuellement sous l’étiquette « GPT-5.3 (Preview) »).
- Février 2026 : disponibilité complète de l’API.
- Mars 2026 : intégration au palier gratuit de ChatGPT (requêtes limitées) pour contrer l’accessibilité gratuite de Gemini.
3 caractéristiques déterminantes de GPT-5.3 ?
Si les rumeurs se confirment, GPT-5.3 introduira une suite de fonctionnalités qui privilégient l’utilité et l’intégration plutôt que la créativité générative brute. L’ensemble de fonctionnalités ressemble à une liste de souhaits pour les architectes systèmes et les développeurs d’entreprise.
1. Pré‑entraînement à haute densité (EPTE)
Le joyau de Garlic est son Efficacité de Pré‑Entraînement Améliorée (EPTE).
Les modèles traditionnels apprennent en voyant des quantités massives de données et en créant un vaste réseau d’associations. Le processus d’entraînement de Garlic comporterait une phase de « pruning » où le modèle condense activement l’information.
- Résultat : un modèle physiquement plus petit (en termes de besoins en VRAM) mais qui conserve la « connaissance du monde » d’un système bien plus vaste.
- Bénéfice : des vitesses d’inférence plus rapides et des coûts d’API significativement plus faibles, répondant au ratio « intelligence/coût » qui a freiné l’adoption de masse de modèles comme Claude Opus.
2. Raisonnement agentique natif
Contrairement aux modèles précédents qui nécessitaient des « wrappers » ou un prompt engineering complexe pour fonctionner comme agents, Garlic dispose de capacités natives d’appel d’outils.
Le modèle traite les appels d’API, l’exécution de code et les requêtes de base de données comme des « citoyens de première classe » dans son vocabulaire.
- Intégration profonde : il ne se contente pas de « savoir coder » ; il comprend l’environnement du code. Il pourrait naviguer dans un répertoire de fichiers, éditer plusieurs fichiers simultanément et exécuter ses propres tests unitaires sans scripts d’orchestration externes.
3. Fenêtres de contexte et de sortie massives
Pour rivaliser avec la fenêtre de contexte à un million de jetons de Gemini, Garlic serait livré avec une fenêtre de contexte de 400 000 jetons. Bien que plus petite que celle de Google, le différenciateur clé est la « mémoire parfaite » sur cette fenêtre, grâce à un nouveau mécanisme d’attention qui empêche la perte de « milieu de contexte » courante dans les modèles de 2025.
- Limite de sortie de 128k : peut‑être plus excitant pour les développeurs, l’extension supposée de la limite de sortie à 128 000 jetons. Cela permettrait au modèle de générer des bibliothèques logicielles entières, des mémoires juridiques exhaustives ou des novellas complètes en un seul passage, supprimant le besoin de « chunking ».
4. Hallucinations drastiquement réduites
Garlic utilise une technique de renforcement post‑entraînement axée sur « l’humilité épistémique » — le modèle est rigoureusement entraîné à savoir ce qu’il ne sait pas. Les tests internes montrent un taux d’hallucination significativement plus faible que GPT‑5.0, le rendant viable pour des secteurs à forts enjeux comme la biomédecine et le droit.
Comment se compare‑t‑il à des concurrents comme Gemini et Claude 4.5 ?
Le succès de Garlic ne se mesurera pas isolément, mais en comparaison directe avec les deux titans qui dominent actuellement l’arène : Gemini 3 de Google et Claude Opus 4.5 d’Anthropic.
GPT-5.3 « Garlic » vs Google Gemini 3
La bataille de l’échelle contre la densité.
- Gemini 3 : actuellement le modèle « couteau suisse ». Il domine dans la compréhension multimodale (vidéo, audio, génération d’images native) et possède une fenêtre de contexte effectivement infinie. C’est le meilleur modèle pour les données « désordonnées » du monde réel.
- GPT-5.3 Garlic : ne peut pas rivaliser avec l’ampleur multimodale brute de Gemini. Il attaque plutôt Gemini sur la pureté du raisonnement. Pour la génération de texte pure, la logique de code et le suivi d’instructions complexes, Garlic vise à être plus précis et moins enclin au « refus » ou au vagabondage.
- Verdict : si vous devez analyser une vidéo de 3 heures, utilisez Gemini. Si vous devez écrire le backend d’une application bancaire, utilisez Garlic.
GPT-5.3 « Garlic » vs Claude Opus 4.5
La bataille pour l’âme du développeur.
- Claude Opus 4.5 : publié fin 2025, ce modèle a conquis les développeurs par sa « chaleur » et ses « vibes ». Il est réputé pour écrire du code propre, lisible par l’humain, et suivre les instructions système avec une précision militaire. Cependant, il est coûteux et lent.
- GPT-5.3 Garlic : c’est la cible directe. Garlic vise à égaler la compétence de codage de Opus 4.5 mais à vitesse doublée et coût divisé par deux. En utilisant le « pré‑entraînement à haute densité », OpenAI veut offrir une intelligence de niveau Opus avec un budget de niveau Sonnet.
- Verdict : le « Code Red » a été déclenché spécifiquement par la domination d’Opus 4.5 en codage. Le succès de Garlic dépend entièrement de sa capacité à convaincre les développeurs de revenir à des clés API OpenAI. Si Garlic code aussi bien qu’Opus mais plus vite, le marché basculera du jour au lendemain.
À retenir
Des builds internes précoces de Garlic surpassent déjà Gemini 3 de Google et Opus 4.5 d’Anthropic dans des domaines spécifiques à forte valeur :
- Compétence en codage : sur des benchmarks « difficiles » internes (au‑delà du HumanEval standard), Garlic montre une tendance réduite à se bloquer dans des « boucles logiques » par rapport à GPT‑4.5.
- Densité de raisonnement : le modèle nécessite moins de jetons de « réflexion » pour parvenir à des conclusions correctes, à l’opposé de la lourdeur « chain‑of‑thought » de la série o1 (Strawberry).
| Indicateur | GPT-5.3 (Garlic) | Google Gemini 3 | Claude 4.5 |
|---|---|---|---|
| Raisonnement (GDP-Val) | 70.9% | 53.3% | 59.6% |
| Codage (HumanEval+) | 94.2% | 89.1% | 91.5% |
| Fenêtre de contexte | 400K Tokens | 2M Tokens | 200K Tokens |
| Vitesse d’inférence | Ultra‑rapide | Modérée | Rapide |
Conclusion
« Garlic » est une rumeur active et plausible : une piste d’ingénierie ciblée d’OpenAI qui privilégie la densité de raisonnement, l’efficacité et les outils du monde réel. Son émergence s’inscrit dans une course aux armements accélérée entre les fournisseurs de modèles (OpenAI, Google, Anthropic) — où le prix stratégique n’est pas seulement la capacité brute mais la capacité exploitable par dollar et par milliseconde de latence.
Si vous êtes intéressé par ce nouveau modèle, veuillez suivre CometAPI. Il met toujours à jour les derniers et meilleurs modèles d’IA à un prix abordable.
Les développeurs peuvent accéder à GPT-5.2, Gemini 3, Claude 4.5 via CometAPI dès maintenant. Pour commencer, explorez les capacités des modèles de CometAPI dans le Playground et consultez le guide API pour des instructions détaillées. Avant d’accéder, assurez‑vous que vous êtes connecté à CometAPI et que vous avez obtenu la clé API. CometAPI propose un prix bien inférieur au prix officiel pour vous aider à intégrer.
Prêt à vous lancer ? → Inscrivez‑vous dès aujourd’hui sur CometAPI !
Si vous souhaitez davantage de conseils, de guides et d’actualités sur l’IA, suivez‑nous sur VK, X et Discord !