
.png&w=3840&q=75)
GPT-5.4 Mini et GPT-5.4 Nano sont les nouvelles variantes compactes d’OpenAI de sa famille GPT-5.4 « frontier » : Mini vise un compromis performance/latence de premier ordre pour le codage, les tâches d’interface multimodale et les charges de travail de sous-agents ; Nano vise un coût et une latence ultra-faibles pour la classification, l’extraction, le classement et les sous-agents massivement parallèles. Mini offre une précision proche des modèles « frontier » sur de nombreux benchmarks développeurs tout en s’exécutant >2× plus vite que les précédents minis ; Nano est nettement moins cher par token et idéal lorsque le débit et la réactivité priment. Ces modèles sont disponibles dans l’API (GPT 5.4 Mini et Nano sont disponibles sur CometAPI).
Que sont GPT-5.4 Mini et GPT-5.4 Nano ?
Définition courte : GPT-5.4 Mini et GPT-5.4 Nano sont des variantes compactes et conçues de la famille GPT-5.4, destinées à apporter les forces centrales du grand GPT-5.4 (raisonnement, codage, perception multimodale, utilisation d’outils) dans des modèles plus rapides et moins coûteux, ciblés sur des charges de travail à fort volume et faible latence. Les modèles ont été annoncés par OpenAI dans le cadre du lancement de GPT-5.4.
- GPT-5.4 Mini — Un petit modèle performant qui « s’approche des performances de GPT-5.4 sur plusieurs évaluations » tout en étant optimisé pour la vitesse et un coût réduit. Il est spécifiquement mis en avant pour le codage, le raisonnement, l’interprétation d’UI multimodale (captures d’écran) et comme sous-agent dans des systèmes agentiques. OpenAI indique qu’il fonctionne plus de 2× plus vite que les précédentes variantes « mini ».
- GPT-5.4 Nano — La variante GPT-5.4 la plus petite et la moins chère ; recommandée pour la classification, l’extraction, le classement et les sous-agents « de soutien » qui gèrent des tâches étroites et répétitives avec un débit très élevé. Il sacrifie un raisonnement plus profond au profit de gains en latence et en coût.
Disponibilité et prix
OpenAI fournit deux points de comparaison concrets pour évaluer les coûts :
- Prix d’entrée de l’API GPT-5.4 (modèle phare complet) : $2.50 / 1M tokens (et un prix de sortie plus élevé pour le modèle phare).
- Prix d’entrée de l’API GPT-5.4 mini : $0.75 / 1M tokens et sortie $4.50 / 1M tokens.
- Prix d’entrée de l’API GPT-5.4 nano : $0.20 / 1M et sortie $1.25 / 1M.
Mis côte à côte : le prix du token d’entrée de mini (0.75) représente 30 % de celui du modèle phare (2.50), soit environ un tiers du coût d’entrée ; le prix de sortie de mini (4.50) est d’environ 32 % d’un prix de sortie du modèle phare indiqué dans le tableau des tarifs API, soit également environ un tiers. Nano est encore moins cher : son coût d’entrée représente environ 8 % du coût d’entrée du modèle phare, et son coût de sortie est inférieur à 10 % du coût de sortie du modèle phare. Ce sont précisément ces proportions qui expliquent pourquoi OpenAI présente mini/nano comme « environ un tiers » (mini) et « une fraction de » (nano) du coût d’utilisation des plus grands modèles pour les tâches à fort volume. Le prix du token nano est passé de $0.05 à $0.20, et le prix du token mini est passé de $0.25 à $0.75 (pour les tokens d’entrée).
Sur la plateforme OpenAI
GPT-5.4 mini est disponible à trois endroits : l’API OpenAI, Codex (la plateforme IDE/app pour développeurs d’OpenAI) et ChatGPT (disponible pour les utilisateurs Free et Go via l’option « Thinking » et comme solution de repli en cas de limites de débit pour les offres payantes). Dans l’API, il prend en charge les entrées texte et image, l’utilisation d’outils (function calling), la recherche web/fichier, l’utilisation d’ordinateur et des compétences — et il offre une très grande fenêtre de contexte (400k tokens) pour servir des flux de travail riches en documents et multi-captures d’écran. La tarification de l’API est de $0.75 par 1M de tokens d’entrée et $4.50 par 1M de tokens de sortie.
GPT-5.4 nano n’est disponible que via l’API. Ses prix catalogue sont $0.20 par 1M de tokens d’entrée et $1.25 par 1M de tokens de sortie — ce qui en fait l’entrée la moins coûteuse de la famille GPT-5.4. Le modèle nano assume délibérément des compromis de capacité en faveur du coût et de la vitesse.
Sur une plateforme tierce
CometAPI est une plateforme d’agrégation multimodale d’API d’IA qui a désormais lancé l’API de la série GPT 5.4, incluant GPT 5.4 Mini et GPT 5.4 Nano, avec 20 % de remise par rapport au prix OpenAI.
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Fonctionnalités clés et nouveautés
Ci-dessous, les capacités phares — et pourquoi elles intéressent les ingénieurs et les équipes produit.
Encodage et prise en charge du long contexte
Fenêtre de contexte : GPT-5.4 mini prend en charge une fenêtre de contexte de 400k tokens (OpenAI liste explicitement mini avec un contexte de 400k). C’est suffisamment grand pour des bases de code multi-fichiers, des documents étendus ou des sessions d’agents multi-tours où le contexte est important. Le contexte de Nano est plus petit que celui du GPT-5.4 complet mais reste conséquent pour des tâches courtes et rapides.
Raisonnement
Niveaux de raisonnement : OpenAI expose un reasoning_effort configurable (none → xhigh) ; mini et nano peuvent fonctionner à des niveaux d’effort variés, mais mini comble l’écart avec le GPT-5.4 complet sur de nombreux benchmarks de raisonnement lorsque l’effort est élevé. Sur plusieurs benchmarks d’intelligence (par ex., GPQA Diamond), mini atteint un score de 88.0 % contre 93.0 % pour GPT-5.4, et nano obtient 82.8 %, ce qui indique un raisonnement respectable pour un petit modèle. Ce sont les résultats publiés par OpenAI dans leur billet de lancement.
Compréhension multimodale (vision & UI)
Perception visuelle et tâches d’UI : GPT-5.4 mini affiche de très bonnes performances multimodales pour les tâches d’UI (captures d’écran, images de documents denses). Sur OSWorld-Verified (un benchmark d’utilisation d’ordinateur), mini obtient 72.1 %, très proche des 75.0 % de GPT-5.4 et bien au-dessus des précédents minis — c’est pourquoi mini est positionné pour les automatisations basées sur des captures d’écran et les assistants multimodaux réactifs. Nano a des performances plus faibles sur les benchmarks visuels mais reste utile pour des tâches d’image plus simples.
Appel d’outils et utilisation d’ordinateur
Capacités natives d’outils/clics : GPT-5.4 introduit et étend des outils natifs d’utilisation d’ordinateur ; mini hérite de la capacité à appeler des outils, effectuer des appels de fonction, interpréter des captures d’écran et orchestrer des sous-agents. Les benchmarks d’appels d’outils (Toolathlon, MCP Atlas) montrent des scores respectables pour mini et nano (Toolathlon : mini 42.9 %, nano 35.5 %) — ce qui quantifie leur capacité à appeler et coordonner des outils externes. Ces métriques proviennent de l’annonce d’OpenAI.
Hallucination / factualité / taux d’erreur
OpenAI indique que GPT-5.4 est « le modèle le plus factuel à ce jour » et montre des réductions d’hallucinations par rapport à GPT-5.2 ; mini et nano présentent une factualité absolue inférieure à celle du modèle complet (par ex., HLE avec outils : GPT-5.4 52.1 %, mini 41.5 %, nano 37.7 %), ce qui suggère un besoin accru de vérification lorsque des modèles plus petits sont utilisés pour des tâches à fort enjeu factuel. Utilisez la vérification basée sur des outils (appels d’outils, rappel de citations) lorsque l’exactitude compte.
Vitesse
OpenAI rapporte que GPT-5.4 mini s’exécute plus de 2× plus vite que l’ancien GPT-5 mini sur des estimations de latence de style production typiques (celles-ci sont basées sur un comportement de production simulé incluant les durées d’appels d’outils et l’échantillonnage de tokens). Cette accélération est une revendication centrale de la nouvelle famille et permet d’utiliser mini comme sous-agent réactif au sein d’applications interactives telles que les assistants de codage.
Comment mini et nano se comportent-ils — « s’approchent-ils » du GPT-5.4 complet ?
OpenAI a publié un ensemble complet de comparaisons de benchmarks couvrant le codage, l’utilisation d’outils, les tâches multimodales d’utilisation d’ordinateur, les tests d’intelligence et les évaluations de long contexte. Les chiffres principaux (effort de raisonnement xhigh lorsque pertinent) incluent :
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | Notes |
|---|---|---|---|---|---|
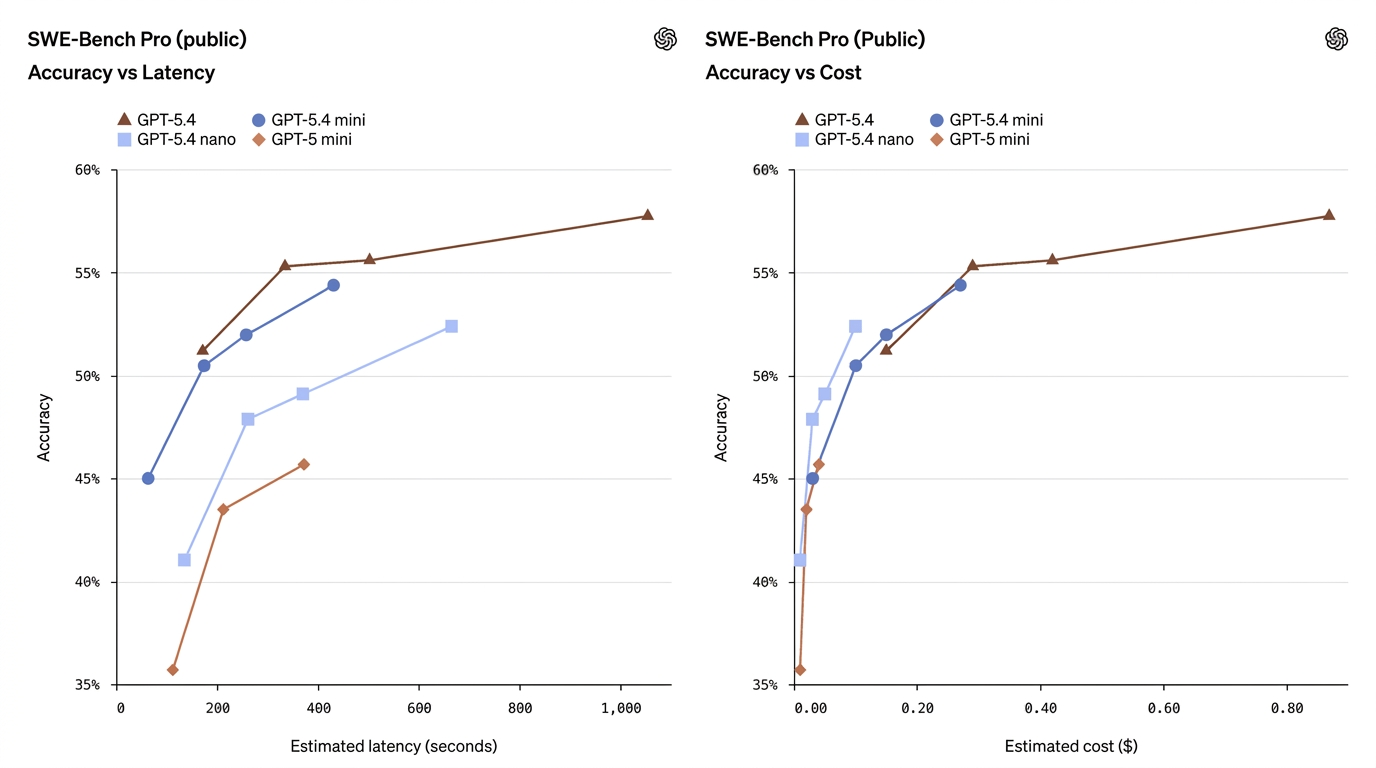
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini se rapproche des performances de codage du modèle complet |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Solides capacités de codage en temps réel pour Mini |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | Mesure l’orchestration et les appels d’outils |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | Benchmark d’intelligence et de raisonnement |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | Capacités d’UI/utilisation d’ordinateur |
Ces chiffres montrent que mini réduit souvent considérablement l’écart — en particulier sur le codage et l’utilisation d’ordinateur — tandis que nano occupe un terrain utile entre capacité et coût.
Que signifient ces chiffres en clair ?
- GPT-5.4 Mini ≈ « quasi-phare » sur de nombreuses tâches de production. Sur SWE-Bench Pro (une métrique de taux de réussite en codage), mini obtient 54.4 % contre 57.7 % pour le modèle phare — un faible écart relatif pour de nombreuses tâches de codage réelles, surtout lorsque la latence compte. Sur OSWorld (utilisation d’ordinateur), mini est à 72.1 % contre 75.0 % pour le modèle phare — là encore, très proche pour les tâches d’UI/capture d’écran.
- GPT-5.4 Nano échange davantage de capacités contre la vitesse/le coût. Le score de nano en codage (52.4 % sur SWE-Bench Pro) est respectable par rapport aux anciens minis, mais son score OSWorld chute à 39.0 %, ce qui montre que pour les tâches nécessitant une compréhension UI multi-étapes complexe ou une orchestration agentique d’outils, nano est moins adapté. Nano excelle dans la classification mono-tour, l’extraction et les petites tâches d’assistance.
- L’usage d’outils s’améliore, mais reste sensible. Toolathlon et d’autres métriques d’utilisation d’outils augmentent substantiellement lors du passage de GPT-5 mini à GPT-5.4 mini/nano, montrant que l’ingénierie d’OpenAI a amélioré la fiabilité des appels d’outils dans des modèles à empreinte plus petite — mais le modèle complet reste en tête pour l’orchestration d’outils complexes.
Comment ils fonctionnent en production
Compression, distillation et optimisations d’ingénierie
Les modèles compacts comme mini/nano utilisent généralement une combinaison de distillation de modèle, de quantification et de pruning architectural pour préserver des capacités à forte valeur (heuristiques de codage, percepts visuels) tout en réduisant le calcul à l’inférence. La formulation d’OpenAI indique un effort d’ingénierie ciblé pour préserver des compétences spécifiques (codage, compréhension d’UI multimodale) dans des empreintes plus petites.
Schémas recommandés
- Schéma orchestrateur + sous-agent : Utilisez GPT-5.4 (grand) comme planificateur/jugement et déléguez le travail à des sous-agents GPT-5.4 mini / nano pour une exécution rapide (recherche, analyse, édition). Cela réduit le coût total et diminue la latence pour l’utilisateur. OpenAI recommande explicitement ce schéma.
- Basculement et gestion des limites de débit : Exposez mini comme solution de repli en cas de limites de débit dans ChatGPT ou Codex afin que les requêtes sensibles au temps reçoivent quand même une réponse capable lorsque le modèle complet est indisponible.
- Architecture en couches pour la maîtrise des coûts : Pipelines de masse (indexation, extraction) → GPT-5.4 nano ; composants d’UI interactifs → GPT-5.4 mini ; jugement éditorial final / chaînes complexes → GPT-5.4 complet. Cette approche multi-niveaux équilibre coût et capacité.
Latence et parallélisation
Mini et nano sont optimisés pour les sous-agents parallèles, où de nombreux petits travailleurs s’exécutent simultanément — par exemple, analyser des milliers de PDF en parallèle. Le concept de « tool yields » d’OpenAI mesure comment des appels d’outils parallèles réduisent la latence mur-à-mur ; mini/nano sont conçus pour rendre ces schémas rentables.
Comment utiliser mini et nano en pratique
Dois-je remplacer partout mes appels au modèle phare par mini/nano ?
Pas automatiquement. Le bon schéma que recommande explicitement OpenAI est la délégation : utilisez un modèle plus grand pour la planification, les jugements complexes ou la vérification finale, et déléguez de nombreuses sous-tâches courtes à des sous-agents mini ou nano. Ce schéma réduit les coûts et la latence tout en conservant les garde-fous du grand modèle là où ils sont les plus importants. Cas d’usage :
- Assistants de codage interactifs : le modèle phare planifie et révise ; mini gère la recherche rapide de code, les modifications et de courts tests unitaires.
- Agents « d’utilisation d’ordinateur » pilotés par captures d’écran : mini peut analyser rapidement des interfaces denses ; le modèle phare résout la planification multi-étapes ambiguë.
- Pipelines à fort volume d’extraction et de classification : nano traite des entrées massives par lots (formulaires, journaux) et renvoie des résultats structurés ; le modèle phare gère les exceptions et les cas limites complexes.
Peut-on utiliser mini ou nano pour des tâches multimodales ou d’image ?
Oui — mini prend en charge les entrées image et obtient de bons résultats sur des benchmarks multimodaux/vision (MMMUPro/OmniDocBench), s’approchant du modèle phare sur certains tests. La force multimodale de nano est plus limitée : bien qu’il s’améliore par rapport aux nanos précédents, ce n’est pas le meilleur choix pour un raisonnement multimodal approfondi ou des tâches agentiques basées sur l’image.
La course aux capacités des petits modèles s’est intensifiée
Il y a trois mois, les petits modèles étaient jugés « suffisants ». Désormais, GPT-5.4 mini se rapproche des modèles phares sur les benchmarks de programmation et les égale presque en performance computationnelle.
La tendance sous-jacente est claire : les capacités des modèles phares sont rapidement transférées vers des modèles plus petits. OpenAI, Google et Anthropic font tous la même chose : distiller les capacités centrales des grands modèles dans des versions plus petites, plus rapides et moins chères.
Conclusion
La sortie de ces deux modèles marque un déplacement des applications d’IA d’un focus sur l’échelle vers un focus sur l’efficacité pratique. Grâce à des capacités de réponse rapides, ils fournissent un support sous-jacent plus fiable pour l’interaction IA en temps réel et la décomposition de flux de tâches complexes.
Pour les développeurs, cela signifie que la structure de coût des systèmes d’agents est redéfinie. Lorsque les coûts chutent à ce niveau, de nombreux scénarios d’agents auparavant « théoriquement faisables mais économiquement infaisables » deviennent viables.
Les développeurs peuvent accéder à GPT 5.4 Mini et GPT-5.4 Nano via CometAPI (CometAPI est une plateforme d’agrégation tout-en-un pour les API de grands modèles telles que les API GPT, les API Nano Banana, etc.) dès maintenant. Avant d’y accéder, veuillez vous assurer que vous êtes connecté à CometAPI et que vous avez obtenu la clé API. CometAPI propose un prix bien inférieur au prix officiel pour vous aider à intégrer.
Prêt à démarrer ?