

xAI a discrètement lancé Grok 4.1 (17-18 novembre 2025) — une mise à jour ciblée de Grok 4 qui privilégie intelligence émotionnelle, expression créative et réduction des hallucinations Tout en conservant la rigueur du raisonnement des versions précédentes de Grok, cette nouvelle version est disponible en deux modes (Réflexion / Non-Réflexion). Déployée discrètement début novembre, elle affiche les meilleurs résultats du classement sur LMArena et est accessible via grok.com, les applications Grok et l'API.
Qu'est-ce que Grok 4.1 ?
Grok 4.1 est le successeur progressif et axé sur la production de Grok 4 : un membre de la famille construit sur la même base d’apprentissage par renforcement à grande échelle, mais affiné et réentraîné grâce à d’importantes optimisations post-entraînement visant à améliorer le style, la personnalité, l’alignement et la fiabilité en situation réelle. Il est présenté comme une avancée pragmatique et « utilisable » : plus performant lors de tests de préférence humaine à l’aveugle, doté d’une intelligence émotionnelle supérieure, meilleur en écriture créative et nettement moins sujet aux « hallucinations » de confiance erronée qui ont affecté les précédents LLM performants.
Grok 4.1 permet d'obtenir des changements qualitatifs dans les quatre dimensions suivantes :
- Créativité : Fait preuve d'un style linguistique et d'une imagination plus affirmés dans ses écrits, ses récits et ses interactions sociales ;
- Intelligence émotionnelle : reconnaît les changements de ton et d’émotion, répond avec une logique émotionnelle plus humaine et génère des réponses réconfortantes et compréhensives ;
- Cohérence de la personnalité : Maintient un ton et une personnalité constants lors de longues conversations, ne présentant plus le comportement incohérent des modèles précédents ;
- Collaboratif : Maintient la cohérence et la conscience de l'objectif dans les dialogues à plusieurs tours de parole ou la collaboration sur une tâche.
xAI résume ses caractéristiques en une phrase : « Elle est plus perspicace, plus empathique et plus semblable à une personne cohérente. »
Comment fonctionne Grok 4.1 en interne ?
Grok 4.1 peut être compris comme la même structure de base pré-entraînée utilisée dans toute la famille Grok 4, à laquelle s'ajoute un pipeline de post-entraînement par couches axé sur modélisation des récompenses, alignement des styles et évaluateurs agents.
Quelles sont les étapes de formation et d'alignement ?
Grok 4.1 fonctionne sur un pipeline multi-étapes typique des LLM de pointe modernes, adapté avec deux changements importants pour la version 4.1 :
- Avant l'entraînement + pendant l'entraînement : Pré-entraînement sur un vaste corpus de données web + entraînement intermédiaire ciblé pour renforcer les connaissances du domaine et les capacités multimodales.
- Réglage fin supervisé (SFT) : Démonstrations humaines des comportements souhaités (réponses, stratégies de refus).
- Modélisation des récompenses (application novatrice) : xAI a entraîné des modèles de récompense non seulement sur des étiquettes de préférence humaine, mais aussi sur des étiquettes de préférence humaine. modèles de raisonnement agentique de frontière en tant qu'évaluateurs de récompenses — permettant ainsi à des évaluateurs hautement compétents, s'appuyant sur des modèles, d'évaluer les résultats candidats à grande échelle. Cela a permis l'optimisation d'attributs non vérifiables comme style, cohérence de la personnalité, empathie et serviabilité sans nécessiter un budget d'étiquetage humain exorbitant.
- Optimisation de la politique (RLHF / RL à partir des récompenses du modèle) : Optimisation de politique standard utilisant les signaux de récompense appris pour produire la politique déployée (le modèle avec lequel les consommateurs interagissent).
Quelles sont les nouveautés dans l'approche de modélisation des récompenses ?
Dans l'apprentissage par renforcement traditionnel, on recueille les préférences humaines (A/B), on entraîne un modèle de récompense à prédire ces préférences, puis on optimise le modèle de base par apprentissage par renforcement (ou échantillonnage par rejet) en fonction de cette récompense apprise. Mais xAI met en avant deux innovations pratiques :
- Modèles de récompense des agents : Au lieu de s'appuyer uniquement sur des juges humains, xAI a utilisé des modèles de raisonnement « agentifs » performants pour évaluer des propriétés plus subtiles (ton, nuances émotionnelles, créativité). Ces modèles peuvent effectuer rapidement des milliers de comparaisons par paires, permettant ainsi aux ingénieurs d'itérer plus vite. C'est ce mécanisme qui a permis des progrès majeurs en matière de style et d'intelligence émotionnelle.
- Alignement post-formation pour les signaux non vérifiables : Pour les attributs qu'on ne peut mesurer avec une métrique déterministe (par exemple, la « chaleur humaine » ou la « personnalité cohérente »), ils ont introduit des objectifs de récompense spécifiques et des programmes d'apprentissage progressifs afin que le modèle apprenne à les évaluer. Catégorie des résultats sans sacrifier l'exactitude des faits fondamentaux.
Comment fonctionne techniquement la distinction entre « penser » et « ne pas penser » ?
- Grok 4.1 Pensée (nom de code)
quasarflux) — Affiche les étapes de raisonnement explicites (jetons de réflexion) avant de fournir la réponse finale ; optimisé pour les tâches complexes et un niveau Elo élevé sur LMArena. Les jetons supplémentaires augmentent le temps d’inférence, mais facilitent les tâches de raisonnement en plusieurs étapes, le débogage et l’explicabilité. - Grok 4.1 Non-pensée (nom de code)
tensor) Ce système contourne les jetons intermédiaires explicites pour une réponse finale unique et immédiate. Cela réduit la latence et le coût des jetons tout en conservant les mêmes pondérations de politique affinées. Le mode « sans réflexion » a été optimisé pour une latence extrêmement faible tout en restant très performant.
Optimisation de l'alignement du sentiment et du style
Au-delà des simples signaux de « sincérité », Grok 4.1 intègre une optimisation ciblée de l'alignement en fonction du sentiment, du ton et du style interpersonnel. Autrement dit, le processus d'apprentissage comprend des mécanismes de récompense ou de sanction qui pénalisent explicitement un ton inapproprié (par exemple, être inutilement brusque alors que l'empathie serait de mise) et récompensent les réponses conformes au style ou au profil de sentiment souhaité. Dans Grok 4.1, l'IA a introduit pour la première fois l'objectif d'optimisation d'« alignement de la personnalité ».
Son objectif est d'aider le modèle à conserver une identité cohérente et stable. Par rapport à Grok 4, la version 4.1 ajoute les éléments suivants aux objectifs de formation :
- Récompenses positives pour la dimension de l'expression émotionnelle (récompense d'alignement émotionnel) ;
- Une mesure de la cohérence de la personnalité.
Comment Grok 4.1 a-t-il été évalué — et quelles ont été ses performances ?
Qu’ont montré les tests de préférence réalisés à l’aveugle par des humains ?
Lors d'un déploiement silencieux, Grok 4.1 a été préféré dans 64.78 % des cas au modèle de production précédent dans le trafic réel, ce qui indique une forte préférence humaine et de meilleurs résultats conversationnels en situation réelle.
Grok 4.1 figure-t-il en tête des classements ?
xAI signale que Grok 4.1 En pensant le mode se trouve à N° 1 sur la Text Arena de LMArena, avec un Elo déclaré de 1483, et son mode non raisonné (rapide) se classe n°2 avec 1465 Elo — un excellent classement public tant pour la précision que pour la présentation (le contrôle du style joue un rôle).
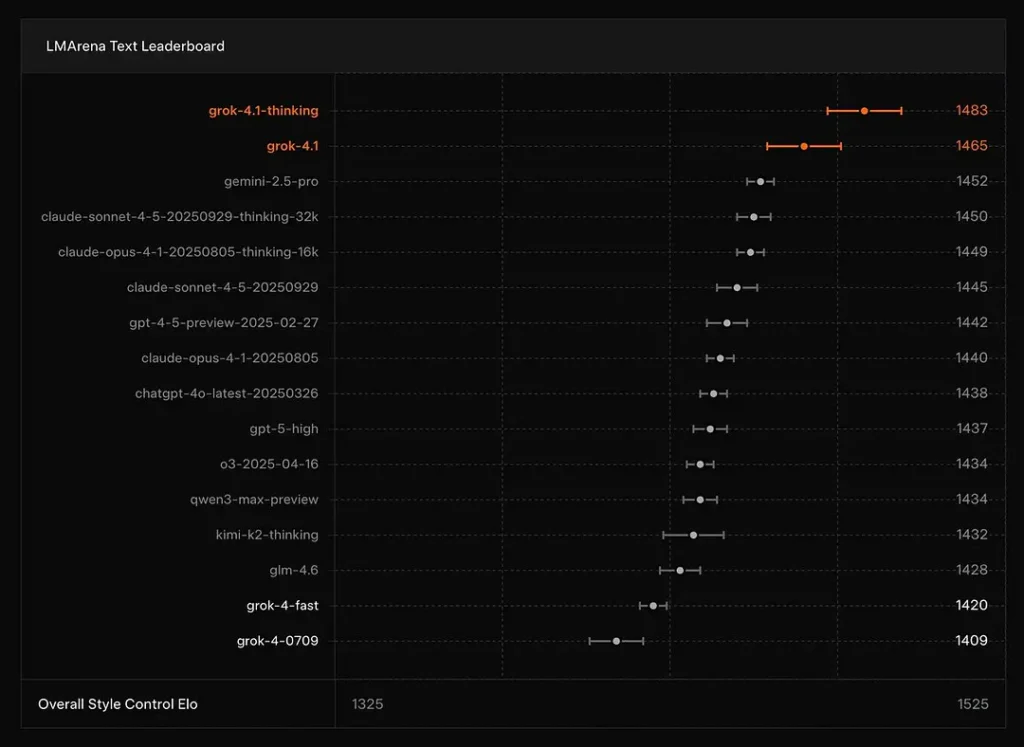
Conclusion : Grok 4.1 surpasse les modèles GPT-4.5 et Claude, largement utilisés, en matière de compréhension, de génération et de qualité globale du texte, et n'est devancé que par la version GPT-5 Advanced Preview.
Intelligence émotionnelle
xAI a exécuté EQ-Bench3, un test spécialisé d'intelligence émotionnelle comprenant 45 scénarios de jeu de rôle difficiles, et rapporte que Grok 4.1 montre de forts progrès en matière d'empathie, de gestion du rythme et de perspicacité interpersonnelle. Grok 4.1 a obtenu les meilleurs scores en matière de compréhension des contextes de tristesse, d'empathie et de réconfort.

L'écriture créative — est-elle réellement plus imaginative ?
Grok 4.1 a été évalué sur Écriture créative v3 (32 consignes réparties sur 3 itérations avec grille d'évaluation et notation Elo). xAI indique que le style d'écriture, la cohérence du ton et la créativité narrative de Grok 4.1 ont considérablement progressé, le plaçant parmi les meilleurs des classements récents pour les tâches créatives (des exemples de consignes sont inclus dans la version). Des évaluations indépendantes ont confirmé ces résultats : les examinateurs ont constaté un ton nettement plus distinctif et une meilleure cohérence des textes longs. En termes de qualité d'écriture, Grok 4.1 n'est devancé que par les modèles de la série GPT-5 et surpasse l'ensemble des gammes Claude, Gemini et Kimi.

Hallucinations réduites / honnêteté
xAI affirme avoir constaté une réduction notable du taux d'hallucinations : ils ont indiqué (dans l'annonce et les publications sur les réseaux sociaux) que Grok 4.1 est ~3 fois moins de risques d'halluciner Comparativement aux modèles Grok précédents, et en s'appuyant sur des analyses de trafic et des évaluations de type FACtScore (par exemple, des séries de questions biographiques, où un score plus bas est préférable), la cohérence des faits est particulièrement stable en « mode sans raisonnement », où des outils de recherche externes sont disponibles.

Pourquoi la Grok 4.1 « écrase »-t-elle les autres modèles ? Est-ce une exagération ?
« Crushes » a des allures de technique marketing, mais cette affirmation repose sur des arguments objectifs :
- Classements: Grok 4.1 se classe parmi les meilleurs des classements publics de LMArena pour la génération de texte (1483 Elo en mode Réflexion) et affiche d'excellentes performances en matière de créativité et d'intelligence émotionnelle, selon les données publiées par xAI. Il s'agit de critères de comparaison pertinents utilisés par l'ensemble de la communauté.
- Victoire de la préférence pour le trafic réel : xAI annonce une préférence accrue des utilisateurs lors de tests comparatifs à l'aveugle (environ 65 % de préférence par rapport au modèle de production précédent) suite à un déploiement discret sur du trafic réel. Cela reflète des améliorations concrètes pour les utilisateurs, et non de simples résultats théoriques.
- Nouvelle capacité pratique : La combinaison de systèmes d'évaluation de modèles, d'apprentissage par renforcement sur des signaux non vérifiables et de filtres d'entrée plus stricts constitue une mesure d'ingénierie pragmatique qui améliore directement l'expérience utilisateur dans les tâches conversationnelles, empathiques et créatives où les concurrents ont historiquement obtenu de moins bons résultats.
Ainsi, même si « dominer » est une façon imagée de dire « se distingue dans de multiples évaluations publiques et internes », les indicateurs publics sous-jacents publiés par xAI confirment cette conclusion.
Comment accéder à Grok 4.1
Accès consommateur/application
xAI a périodiquement rendu Grok 4.1 accessible en mode « Auto » gratuitement ou dans le cadre d'une promotion, mais les niveaux premium (SuperGrok, SuperGrok Heavy) et l'accès API avec des quotas plus élevés existent et persistent en tant qu'offres payantes.
Grok 4.1 est disponible pour tous les utilisateurs on grok.com, X (anciennement Twitter), et les applications iOS et Android Grok, déployées immédiatement en mode automatique tout en étant également sélectionnables explicitement comme « Grok 4.1 » dans le sélecteur de modèle.
Accès API et plans pour développeurs
Les points d'accès Grok 4.1 sont disponibles via l'API xAI. À la date de publication de cet article, l'API GPT 4.1 officielle n'est pas encore disponible.
API Comet promet de suivre l'évolution des dernières dynamiques des modèles, notamment API Grok 4.1qui sera disponible simultanément avec la version officielle. Nous espérons qu'elle sortira prochainement et que vous continuerez à suivre CometAPI. En attendant, vous pouvez vous intéresser aux autres modèles de Grok, tels que : Grok-code-fast-1 et Grok 4Explorez leurs fonctionnalités dans l'environnement de test et consultez le guide de l'API pour obtenir des instructions détaillées sur leur utilisation. Avant d'y accéder, assurez-vous de vous être connecté à CometAPI et d'avoir obtenu la clé API.
Conseils pratiques pour l'utilisation de Grok 4.1 en production
Comment réduire le risque d'hallucinations
- Activer la recherche en direct ou une chaîne d'outils vérifiée pour les requêtes de recherche d'informations.
- Fournir les étapes de vérification: demander au modèle de fournir des sources et des preuves pour les affirmations factuelles ; utiliser le
responsemétadonnées pour examiner les citations (si disponibles). - Effectuer des vérifications déterministes (LLM de vérification des faits, validateurs de données structurées) comme étape de post-traitement pour les résultats à enjeux élevés.
Comment contrôler le ton et le style
- Utilisez des invites système explicites pour corriger la voix (« Vous êtes formel et empathique. »).
- Utilisez des invites supervisées et de petits modèles locaux pour une voix cohérente dans toutes les applications.
- Lorsque disponible, tirez parti de l'option de contrôle du style et des boutons de direction à récompense de xAI.
Verdict final : Grok 4.1 représente-t-il un changement radical ?
Grok 4.1 est pas une architecture entièrement nouvelle ; il s'agit plutôt d'une architecture sophistiquée et réfléchie. post-formation / alignement Une version qui se concentre sur ce qui importe réellement aux humains dans les discussions en ligne : personnalité, intelligence émotionnelle, créativité et moins d'erreurs factuellesDes gains significatifs dans les classements, une meilleure prise en compte du trafic réel et des outils de sécurité améliorés : Grok 4.1 représente une avancée majeure pour les applications qui reposent sur des conversations de haute qualité, une collaboration créative ou une assistance basée sur la tonalité. Lors de sa sortie, il s'est imposé comme le logiciel le plus performant dans plusieurs tests comparatifs de la communauté.
CometAPI est une plateforme commerciale d'agrégation d'API qui offre aux développeurs un accès REST unifié, de type OpenAI, à des centaines de modèles d'IA provenant de différents fournisseurs : modèles de langage textuels, générateurs d'images/vidéo, plongements lexicaux, etc., via une interface unique et cohérente. Au lieu de configurer des SDK distincts ou des points de terminaison personnalisés pour OpenAI, Anthropic, Google, Meta ou d'autres fournisseurs de modèles spécialisés, CometAPI permet d'appeler différents modèles en modifiant simplement leur chaîne de caractères et quelques paramètres.
Prêt à essayer ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!