
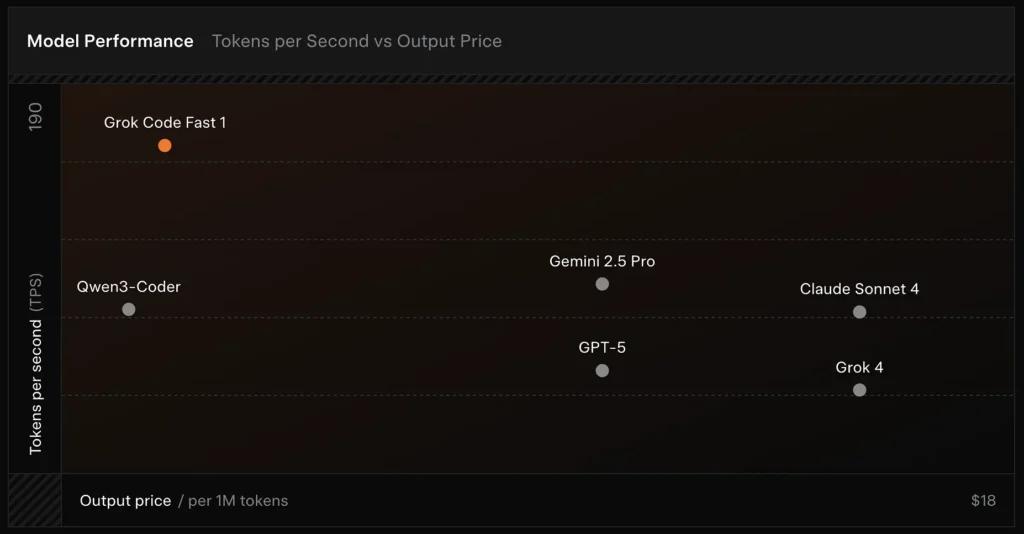
grok-code-fast-1 est le modèle de codage agentique axé sur la vitesse et rentable de xAI, conçu pour alimenter les intégrations aux IDE et les agents de codage automatisés. Il met l’accent sur la faible latence, les comportements agentiques (appels d’outils, traces de raisonnement étape par étape), et un profil de coût compact pour les workflows quotidiens des développeurs.
Principales caractéristiques (en bref)
- Haut débit / faible latence : axé sur une sortie de jetons très rapide et des complétions rapides pour une utilisation dans les IDE.
- Appels de fonctions agentiques et orchestration d’outils : prend en charge les appels de fonctions et l’orchestration d’outils externes (exécuter des tests, des linters, récupérer des fichiers) pour permettre des agents de codage multi-étapes.
- Grande fenêtre de contexte : conçu pour gérer de grands codebases et des contextes multi-fichiers (les fournisseurs listent des fenêtres de contexte 256k dans les adaptateurs du marketplace).
- Raisonnement / traces visibles : les réponses peuvent inclure des traces de raisonnement étape par étape destinées à rendre les décisions de l’agent inspectables et débogables.
Détails techniques
Architecture et entraînement : xAI indique que grok-code-fast-1 a été construit de zéro avec une nouvelle architecture et un corpus de pré-entraînement riche en contenus de programmation ; le modèle a ensuite reçu une curation post-entraînement sur des ensembles de données de pull requests/code de haute qualité et du monde réel. Ce pipeline d’ingénierie vise à rendre le modèle pratique dans les workflows agentiques (IDE + usage d’outils).
Service et contexte : grok-code-fast-1 et les modes d’utilisation typiques supposent des sorties en streaming, des appels de fonctions et une injection de contexte riche (uploads/collections de fichiers). Plusieurs marketplaces cloud et adaptateurs de plateforme le listent déjà avec une prise en charge de grands contextes ( 256k contexts dans certains adaptateurs).
Fonctionnalités d’utilisation : traces de raisonnement visibles (le modèle expose sa planification/son usage d’outils), conseils d’ingénierie de prompts et intégrations d’exemple, ainsi que des intégrations précoces avec des partenaires de lancement (par ex., GitHub Copilot, Cursor).
Performances aux benchmarks (ce sur quoi il obtient des scores)
SWE-Bench-Verified : xAI rapporte un 70.8% sur son banc d’essai interne sur le sous-ensemble SWE-Bench-Verified — un benchmark couramment utilisé pour les comparaisons de modèles d’ingénierie logicielle. Une évaluation pratique récente a rapporté une note moyenne humaine ≈ 7.6 sur une suite de codage mixte — concurrent avec certains modèles haut de gamme (par ex., Gemini 2.5 Pro) mais derrière des modèles multimodaux/« best-reasoner » plus grands comme Claude Opus 4 et Grok 4 de xAI sur des tâches de raisonnement à haute difficulté. Les benchmarks montrent aussi une variance selon la tâche : excellent pour les corrections de bogues courantes et la génération de code concise, plus faible sur certains problèmes de niche ou spécifiques à une bibliothèque (exemple Tailwind CSS).
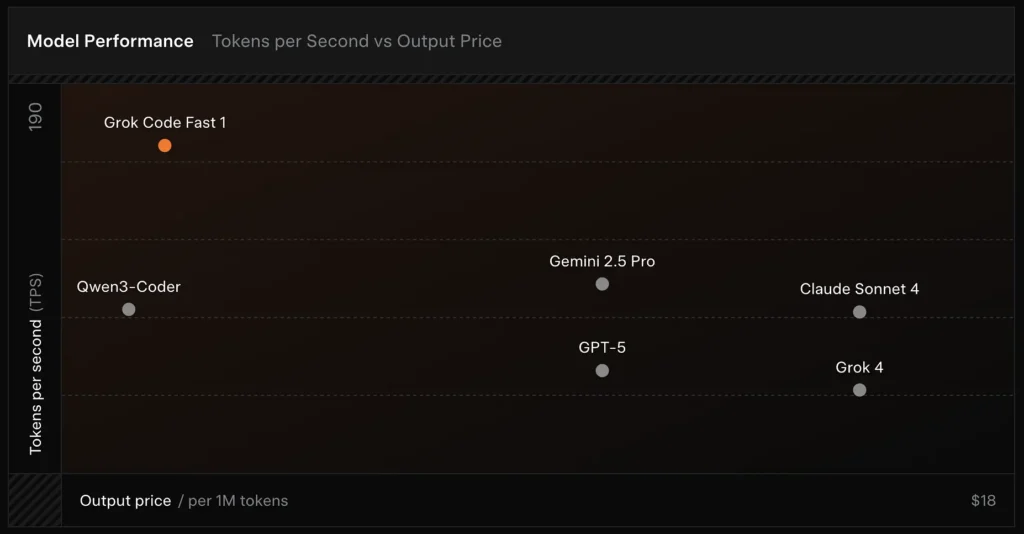
Comparaison :
- vs Grok 4 : Grok-code-fast-1 échange une partie de la justesse absolue et du raisonnement plus profond contre un coût bien inférieur et un débit plus rapide ; Grok 4 reste l’option de plus haute capacité.
- vs Claude Opus / GPT-class : Ces modèles dominent souvent sur des tâches complexes, créatives ou de raisonnement difficile ; Grok-code-fast-1 est très compétitif sur les tâches développeur routinières à fort volume, où la latence et le coût comptent.
Limitations et risques
Limitations pratiques observées jusqu’à présent :
- Lacunes de domaine : baisse de performance sur des bibliothèques de niche ou des problèmes formulés de façon inhabituelle (des exemples incluent des cas limites de Tailwind CSS).
- Compromis coût des jetons de raisonnement : parce que le modèle peut émettre des jetons de raisonnement internes, un raisonnement très agentique/verbeux peut augmenter la longueur de la sortie d’inférence (et le coût).
- Précision / cas limites : bien qu’il soit performant sur les tâches routinières, Grok-code-fast-1 peut halluciner ou produire du code incorrect pour des algorithmes nouveaux ou des énoncés de problème adversariaux ; il peut être inférieur aux meilleurs modèles axés sur le raisonnement sur des benchmarks algorithmiques exigeants.
Cas d’usage typiques
- Assistance IDE et prototypage rapide : complétions rapides, écritures de code incrémentales et débogage interactif.
- Agents automatisés / workflows de code : des agents qui orchestrent des tests, exécutent des commandes et éditent des fichiers (par ex., assistants CI, robots relecteurs).
- Tâches d’ingénierie au quotidien : génération d’ossatures de code, refactorisations, suggestions de tri de bogues, et échafaudage de projets multi-fichiers où une faible latence améliore matériellement le flux du développeur.
Comment appeler l’API grok-code-fast-1 depuis CometAPI
grok-code-fast-1 Tarification de l’API dans CometAPI, 20% de réduction par rapport au prix officiel :
- Jetons d’entrée : $0.16/ M tokens
- Jetons de sortie : $2.0/ M tokens
Étapes requises
- Connectez-vous à cometapi.com. Si vous n’êtes pas encore notre utilisateur, veuillez d’abord vous inscrire.
- Obtenez la clé d’API d’accès de l’interface. Cliquez sur “Add Token” dans la section API token du centre personnel, récupérez la clé de jeton : sk-xxxxx et soumettez-la.
Méthode d’utilisation
- Sélectionnez le point de terminaison “
grok-code-fast-1” pour envoyer la requête API et définissez le corps de requête. La méthode de requête et le corps de requête sont obtenus à partir de la documentation API de notre site Web. Notre site fournit également un test Apifox pour votre commodité. - Remplacez <YOUR_API_KEY> par votre clé CometAPI réelle depuis votre compte.
- Insérez votre question ou votre demande dans le champ content — c’est ce à quoi le modèle répondra.
- . Traitez la réponse de l’API pour obtenir la réponse générée.
CometAPI fournit une API REST entièrement compatible — pour une migration sans friction. Principaux détails dans la documentation de l’API :
- URL de base : https://api.cometapi.com/v1/chat/completions
- Noms de modèles : “
grok-code-fast-1“ - Authentification : jeton Bearer via l’en-tête
Authorization: Bearer YOUR_CometAPI_API_KEY - Type de contenu :
application/json.
Intégration de l’API et exemples
Extrait Python pour un appel ChatCompletion via CometAPI :
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Voir aussi Grok 4