

Lorsque xAI a annoncé Grok Code Fast 1 Fin août 2025, la communauté de l'IA a reçu un signal clair : Grok n'est plus seulement un assistant conversationnel ; il est désormais utilisé comme arme pour les workflows des développeurs. Grok Code Fast 1 (version courte : Code rapide 1) est un modèle de raisonnement à faible latence et à faible coût spécialement conçu pour les tâches de codage et agentique Workflows de codage : des workflows où le modèle peut planifier, appeler des outils et agir comme un assistant de codage autonome au sein des IDE et des pipelines. Le modèle est déjà présent dans les intégrations partenaires (notamment sous forme d'aperçu sur GitHub Copilot) et dans plusieurs catalogues de fournisseurs cloud et tiers, comme CometAPI.
Qu'est-ce que Grok Code Fast 1 et pourquoi est-ce important ?
xAI grok-code-fast-1 En tant que modèle de codage à faible latence, délibérément ciblé, il vise à être un partenaire actif au sein des outils de développement et des workflows automatisés. Il se positionne comme un « programmeur en binôme » pratique, optimisé pour la vitesse, l'utilisation d'outils réactifs (recherche, appels de fonctions, modifications de code, tests) et le raisonnement en contexte large sur plusieurs référentiels. Il s'agit d'une variante spécialisée de la famille Grok de xAI qui privilégie deux objectifs : vitesse interactive et coûts des jetons économiques Pour les workflows de codage. Plutôt que de prétendre être le généraliste le plus complet et multimodal, il cible le cycle de vie quotidien du développeur : lire le code, proposer des modifications, appeler des outils (linters/tests) et itérer rapidement.
Pourquoi c'est important maintenant :
- Les équipes attendent de plus en plus un retour instantané dans les IDE et l'intégration continue. Attendre plusieurs secondes pour chaque itération de l'assistant perturbe le flux. Grok Code Fast 1 est conçu pour réduire ces frictions.
- Il prend en charge appel de fonction, sorties structurées et traces de raisonnement visibles, permettant une meilleure automatisation des tâches en plusieurs étapes (recherche → édition → test → validation). Il est donc parfaitement adapté aux systèmes de codage agentique et aux assistants de développement orchestrés.
Pourquoi le terme « agentique » est important ici
Les modèles agentiques sont bien plus que de la saisie semi-automatique. Ils permettent :
- décider quel outil externe appeler (exécuter des tests, récupérer la documentation du package),
- diviser une tâche en sous-étapes et les exécuter,
- renvoyez des résultats JSON structurés ou effectuez des modifications de style git par programmation.
Grok Code Fast 1 expose délibérément ses traces de raisonnement (afin que les développeurs puissent inspecter la chaîne de pensée pendant le streaming) et met l'accent sur l'appel d'outils natifs — deux fonctionnalités qui prennent en charge le codage agentique sûr et orientable.
Performances et vitesse Grok Code Fast 1
Comment Grok mesure-t-il la vitesse ?
Le terme « rapide » dans le branding du modèle fait référence à plusieurs dimensions :
- Latence d'inférence — Débit de jetons et temps de réponse lors de la génération de code ou de traces de raisonnement. Le modèle est optimisé pour une latence réduite, ce qui lui permet de s'adapter aux boucles interactives de l'IDE (saisie semi-automatique, suggestions de code, corrections rapides de bugs) plutôt qu'aux tâches par lots longues.
- Rapport coût-efficacité — la tarification des jetons et la configuration du modèle visent à réduire le coût par utilisation des tâches de codage de routine ; les marchés tiers le répertorient avec des tarifs inférieurs par rapport aux modèles plus grands et plus généraux.
- Productivité des développeurs — « vitesse » perçue dans un flux de travail : la rapidité avec laquelle un développeur peut passer d'une invite à un code exécutable, y compris la capacité du modèle à appeler des fonctions et à renvoyer des sorties structurées et testables.
Notes sur les performances dans le monde réel
| Action / Modèle | Grok Code Fast 1 (Observé) |
|---|---|
| Complétion de ligne simple | Instantané |
| Génération de fonctions (5 à 10 lignes) | <1 seconde |
| Génération de composants/fichiers complexes (plus de 50 lignes) | secondes 2-5 |
| Refactorisation d'une grande fonction | secondes 5-10 |
Comparaison
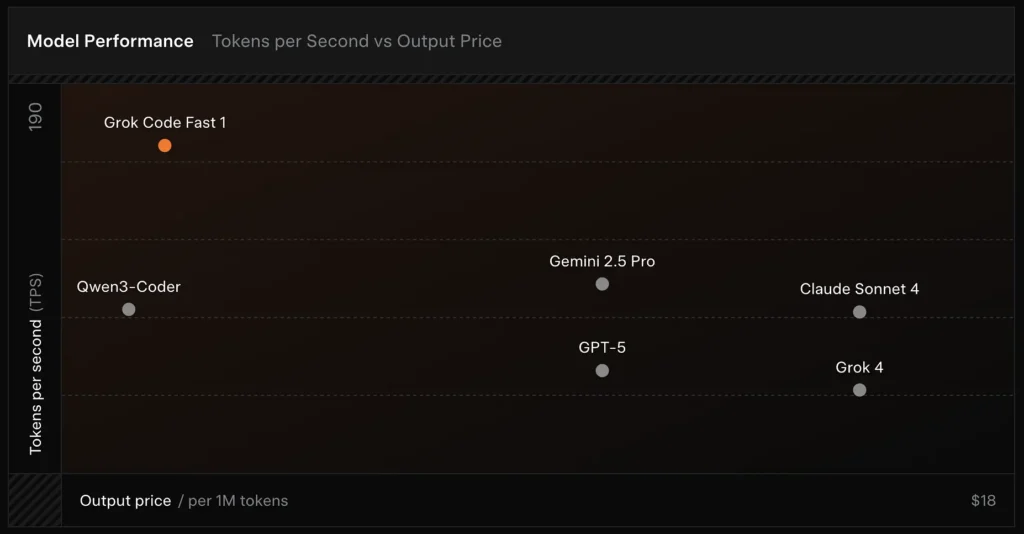
- Vitesse : atteint 190 jetons/seconde lors des tests.
- Comparaison des prix : la sortie de GPT-5 coûte environ 18 $ pour 1 million de jetons, tandis que Grok Code Fast-1 ne coûte que 1.50 $.
- Précision : 70.8 % obtenu lors du test de référence SWE-Bench-Verified.
Des choix de conception qui permettent la vitesse
- Grande fenêtre de contexte (256 000 jetons) : permet au modèle d'ingérer de grandes bases de code ou de longs historiques de conversation sans troncature, réduisant ainsi le besoin de téléchargements de contexte répétés.
- Invite compatible avec le cache : le modèle et la plate-forme sont optimisés pour mettre en cache les jetons de préfixe qui changent rarement au fil des étapes agentiques, ce qui réduit les calculs répétés et améliore la latence pour les interactions d'outils en plusieurs étapes.
- Protocole d'appel d'outils natif : Au lieu d'utiliser du XML ad hoc ou des « appels de fonctions » fragiles basés sur des chaînes, l'API de Grok prend en charge les définitions structurées de fonctions et d'outils que le modèle peut invoquer pendant son raisonnement (avec des résumés ou des « traces de réflexion » restitués). Cela minimise le travail d'analyse et permet au modèle de combiner plusieurs outils de manière fiable.
Quelles fonctionnalités Grok Code Fast 1 offre-t-il ?
Vous trouverez ci-dessous les principales fonctionnalités qui rendent Grok Code Fast 1 attrayant pour les intégrations destinées aux développeurs.
Compétence de base
- Codage agentique : prise en charge intégrée de l'appel d'outils (exécuteurs de tests, linters, recherches de packages, opérations git) et de la composition de workflows en plusieurs étapes.
- Traces de raisonnement en streaming : lorsqu'elle est utilisée en mode streaming, l'API fait apparaître un « contenu de raisonnement » intermédiaire afin que les développeurs et les systèmes puissent observer la planification du modèle et intervenir.
- Sorties structurées et appel de fonctions : renvoie des résultats JSON ou typés adaptés à la consommation programmatique (pas seulement du texte libre).
- Contexte très large (256 k jetons) : puissant pour les tâches à session unique et multi-fichiers.
- Inférence rapide : La technologie d'accélération innovante et l'optimisation du cache rapide améliorent considérablement la vitesse d'inférence. La vitesse de réponse est extrêmement rapide, effectuant souvent des dizaines d'appels d'outils au moment où un utilisateur a fini de lire une invite.
- Optimisation de la programmation agentique : Outils de développement courants : grep, opérations sur terminal et édition de fichiers. Intégration fluide aux principaux IDE tels que Cursor, GitHub Copilot et Cline.
- Couverture du langage de programmation : Excellentes compétences dans divers langages : TypeScript, Python, Java, Rust, C++ et Go. Capable de gérer une gamme complète de tâches de développement, de la création de projets à partir de zéro au dépannage de bases de code complexes et à la correction de bugs détaillés.
Ergonomie du développeur
- Surface du SDK compatible OpenAI : L'API de xAI met l'accent sur la compatibilité avec les SDK populaires et fournit des conseils de migration pour raccourcir l'intégration des développeurs.
- Prise en charge de CometAPI et BYOK : des fournisseurs tiers comme API Comet exposer Grok Code Fast 1 via REST pour les équipes qui privilégient les points de terminaison compatibles avec OpenAI. Cela facilite l'intégration dans les chaînes d'outils qui nécessitent des API de type OpenAI.
En quoi Grok Code Fast 1 est-il différent des LLM à usage général ?
Grok Code Fast 1 abandonne une partie de l'étendue de son modèle conversationnel phare au profit d'un ajustement plus précis du code, des outils de développement et des boucles d'outils rapides. Concrètement, cela signifie :
- Latence aller-retour plus rapide pour la génération de jetons et les appels d'outils.
- Des résultats plus nets et axés sur l'action (réponses structurées, métadonnées d'appel JSON/fonction).
- Modèle de coût optimisé pour les interactions de code à volume élevé (moins cher par jeton dans de nombreuses listes de passerelles)
Dans quelle mesure Grok Code Fast 1 est-il agentique ? Que signifie « codage agentique » en pratique ?
« Agentique » signifie que le modèle peut planifier et exécuter des tâches en plusieurs étapes avec des interactions avec des outils externes. Pour Grok Code Fast 1, la puissance agentique prend les formes suivantes :
- Appel de fonction:Grok peut demander des appels à des fonctions externes (par exemple, exécuter des tests, récupérer des fichiers, appeler des linters) et incorporer les résultats renvoyés pour les décisions de suivi.
- Traces de raisonnement visiblesLes sorties peuvent inclure un raisonnement par étapes que vous pouvez inspecter et utiliser pour déboguer ou piloter le comportement des agents. Cette transparence facilite l'automatisation des modifications dans une base de code.
- Boucles d'outils persistantes:Grok est conçu pour être utilisé dans des cycles courts et répétés de planification→exécution→vérification plutôt que d'attendre une seule réponse monolithique.
Cas d'utilisation qui bénéficient le plus du comportement agentique
- Réparation de code automatisée : localisez les tests défaillants, proposez des modifications, exécutez des tests, itérez.
- Analyse du référentiel : recherchez des modèles d'utilisation dans des milliers de fichiers, créez des résumés ou proposez des refactorisations avec des citations de fichiers/lignes exacts.
- Génération de PR assistée : rédigez des descriptions de PR, générez des correctifs différentiels et annotez des tests, le tout dans un flux orchestré qui peut s'exécuter en CI.
Comment les développeurs peuvent-ils accéder et utiliser l'API Grok Code Fast 1 ?
xAI expose les modèles Grok via son API publique et ses intégrations partenaires. Il existe trois modèles d'accès courants :
- API xAI directe — Créez un compte xAI, générez une clé API dans la console et appelez les points de terminaison REST. La documentation xAI présente la base REST comme suit :
https://api.x.aiet spécifiez l'authentification par jeton Bearer standard. La documentation et les guides fournissent des exemples de curl et de SDK et soulignent la compatibilité avec les requêtes de type OpenAI pour de nombreuses couches d'outils. - Partenaires IDE/services (intégrations préliminaires) — GitHub Copilot (version préliminaire publique avec option d'adhésion) et d'autres partenaires (Cursor, Cline, etc.) ont été annoncés comme collaborateurs au lancement, permettant l'intégration de Grok Code Fast 1 dans VS Code et des outils similaires, parfois via des flux « apportez votre propre clé ». Si vous utilisez Copilot pour les versions Pro ou Entreprise, recherchez l'option d'adhésion à Grok Code Fast 1.
- Passerelles tierces (CometAPI, agrégateurs d'API) — les fournisseurs normalisent les appels API entre les fournisseurs et font parfois apparaître différents niveaux de tarifs (utiles pour le prototypage ou les solutions de secours multi-fournisseurs). API Comet et d'autres registres répertorient des contextes de modèles, des exemples de prix et des exemples d'appels.
Vous trouverez ci-dessous deux exemples de code pratiques (streaming SDK natif Python et REST via API Comet) qui illustrent comment vous pourriez piloter Grok Code Fast 1 dans une application réelle.
Concevez vos outils : enregistrer les définitions de fonction/outil dans la requête afin que le modèle puisse les appeler ; pour le streaming, la capture
reasoning_contentpour surveiller le plan du modèle.
Code de cas d'utilisation : Python (SDK xAI natif, échantillonneur de streaming)
Cet exemple est adapté des modèles de documentation de xAI. Remplacer
XAI_API_KEYavec votre clé réelle et ajustez les définitions d'outils à votre environnement. Le streaming affiche les jetons et les traces de raisonnement.
# Save as grok_code_fast_example.py
import os
import asyncio
# Hypothetical xai_sdk per xAI docs
import xai_sdk
API_KEY = os.getenv("XAI_API_KEY") # store your key securely
async def main():
client = xai_sdk.Client(api_key=API_KEY)
# Example: ask the model to add a unit test and fix failing code
prompt = """
Repo structure:
/src/math_utils.py
/tests/test_math_utils.py
Task: run the tests, identify the first failing test case, and modify src/math_utils.py
to fix the bug. Show the minimal code diff and run tests again.
"""
# Start a streaming sample; we want to see reasoning traces
async for chunk in client.sampler.sample(
model="grok-code-fast-1",
prompt=prompt,
max_len=1024,
stream=True,
return_reasoning=True, # stream reasoning_content when available
):
# chunk may include tokens and reasoning traces
if hasattr(chunk, "delta"):
if getattr(chunk.delta, "reasoning_content", None):
# model is exposing its internal planning steps
print("", chunk.delta.reasoning_content, flush=True)
if getattr(chunk.delta, "token_str", None):
print(chunk.delta.token_str, end="", flush=True)
if __name__ == "__main__":
asyncio.run(main())
Remarques
- La
return_reasoning=TrueLe drapeau représente les instructions des documents pour diffuser des traces de raisonnement : capturez-les et affichez-les afin que vous puissiez auditer le plan du modèle. - Dans une configuration agentique réelle, vous enregistreriez également des outils (par exemple,
run_tests,apply_patch) et autoriser le modèle à les appeler. Le modèle peut alors décider d'invoquerrun_tests()et utiliser les sorties pour informer un patch.
Code de cas d'utilisation : REST (compatible CometAPI / OpenAI)
Si votre pile attend des points de terminaison REST de style OpenAI, API Comet expose
grok-code-fast-1comme chaîne de modèle compatible. L'exemple ci-dessous utiliseopenaimodèle client de style.
import os
import requests
CometAPI_KEY = os.getenv("CometAPI_API_KEY")
BASE = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {CometAPI_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": "grok-code-fast-1",
"messages": [
{"role": "system", "content": "You are Grok Code Fast 1, a fast coding assistant."},
{"role": "user", "content": "Write a function in Python that merges two sorted lists into one sorted list."}
],
"max_tokens": 300,
"stream": False
}
resp = requests.post(BASE, json=payload, headers=headers)
resp.raise_for_status()
print(resp.json())
Remarques
- API Comet agit comme un pont lorsque l'accès gRPC natif ou SDK est problématique dans votre environnement ; il prend en charge le même contexte 256 k et expose
grok-code-fast-1Vérifiez la disponibilité du fournisseur et les limites tarifaires.
Quels sont les modèles d’intégration pratiques et les meilleures pratiques ?
IDE-first (programmation en binôme)
Intégrez Grok Code Fast 1 comme modèle de complétion/assistant dans VS Code ou d'autres IDE. Utilisez des invites courtes demandant des modifications mineures et testables. Maintenez l'assistant dans une boucle étroite : génération du correctif → exécution des tests → réexécution de l'assistant avec un résultat de test défaillant.
Automatisation CI
Utilisez Grok Code Fast 1 pour trier les erreurs récurrentes, suggérer des correctifs ou générer automatiquement des tests unitaires pour le code nouvellement ajouté. Grâce à son prix et à son architecture à faible latence, il est adapté aux exécutions d'intégration continue fréquentes, contrairement aux modèles généralistes plus onéreux.
Orchestration des agents
Combinez le modèle avec des outils de protection robustes : exécutez toujours les correctifs proposés dans un environnement sandbox, exécutez la suite de tests complète et exigez une vérification humaine pour les modifications de sécurité ou de conception non triviales. Utilisez des traces de raisonnement visibles pour auditer les actions et les rendre reproductibles.
Conseils d'ingénierie rapides
- Fournissez au modèle les fichiers exacts ou une petite fenêtre contextuelle ciblée pour les modifications.
- Préférez les schémas de sortie structurés pour les différences ou les résumés JSON : ils sont plus faciles à valider automatiquement.
- Lors de l'exécution de flux en plusieurs étapes, enregistrez les appels d'outils et les résultats du modèle afin de pouvoir rejouer ou déboguer le comportement de l'agent.
Cas d'utilisation concret : correction automatique d'un test pytest défaillant
Vous trouverez ci-dessous un flux de travail Python illustratif (simplifié) montrant comment vous pouvez intégrer Grok Code Fast 1 dans une boucle de test-correction.
# pseudo-code: agentic test-fix loop with grok-code-fast-1
# 1) collect failing test output
failing_test_output = run_pytest_and_capture("tests/test_math.py")
# 2) ask Grok to propose a patch and tests
prompt = f"""
Pyproject: repo root
Failing test output:
{failing_test_output}
Please:
1) Explain root cause briefly.
2) Provide a patch in unified diff format that should fix the issue.
3) Suggest a minimal new/updated unit test to prove the fix.
"""
resp = call_grok_model("grok-code-fast-1", prompt, show_reasoning=True)
# 3) parse structured patch from response (validate!)
patch = extract_patch_from_response(resp)
if is_patch_safe(patch):
apply_patch(patch)
test_result = run_pytest_and_capture("tests/test_math.py")
report_back_to_grok(test_result)
else:
alert_human_review(resp)
Cette boucle montre comment le comportement agentique (proposer → valider → exécuter → itérer) peut être implémenté tandis que le développeur conserve le contrôle sur l'application des modifications.
Pour commencer
CometAPI est une plateforme d'API unifiée qui regroupe plus de 500 modèles d'IA provenant de fournisseurs leaders, tels que la série GPT d'OpenAI, Gemini de Google, Claude d'Anthropic, Midjourney, Suno, etc., au sein d'une interface unique et conviviale pour les développeurs. En offrant une authentification, un formatage des requêtes et une gestion des réponses cohérents, CometAPI simplifie considérablement l'intégration des fonctionnalités d'IA dans vos applications. Que vous développiez des chatbots, des générateurs d'images, des compositeurs de musique ou des pipelines d'analyse pilotés par les données, CometAPI vous permet d'itérer plus rapidement, de maîtriser les coûts et de rester indépendant des fournisseurs, tout en exploitant les dernières avancées de l'écosystème de l'IA.
Les développeurs peuvent accéder API Grok Code Fast 1 via CometAPI,la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Inscrivez-vous à CometAPI dès aujourd'hui !
Conclusion
Grok Code Fast 1 n'est pas présenté comme le modèle idéal pour tous les travaux. C'est plutôt un spécialiste — optimisé pour les workflows de codage dynamiques et riches en outils, où la rapidité, une large fenêtre contextuelle et un faible coût par itération sont essentiels. Cette combinaison en fait un outil pratique au quotidien pour de nombreuses équipes d'ingénierie : suffisamment rapide pour des expériences d'édition en direct, suffisamment économique pour être itéré et suffisamment transparent pour une intégration sécurisée, dans les limites appropriées.