

DeepSeek a publié Recherche profonde V3.2 et une variante à calcul haute performance DeepSeek-V3.2-SpécialCe modèle intègre un nouveau moteur d'attention parcimonieuse (DSA), un comportement amélioré des agents et des outils, ainsi qu'un mode de raisonnement interne qui met en évidence le processus de pensée. Les deux modèles sont disponibles via l'API de DeepSeek (points de terminaison compatibles avec OpenAI) et les artefacts et rapports techniques sont publiés.
Qu'est-ce que DeepSeek V3.2 ?
DeepSeek V3.2 est le successeur en production de la famille DeepSeek V3, une vaste famille de modèles génératifs à contexte long, conçue spécifiquement pour raisonnement d'abord Flux de travail et utilisation des agents. La version 3.2 consolide les améliorations expérimentales précédentes (V3.2-Exp) dans une gamme de modèles standard accessible via l'application, l'interface web et l'API de DeepSeek. Elle prend en charge à la fois des réponses conversationnelles rapides et un mode dédié. thinking Mode (chaîne de pensée) adapté aux tâches de raisonnement en plusieurs étapes telles que les mathématiques, le débogage et la planification.
Pourquoi la version 3.2 est importante (contexte rapide)
DeepSeek V3.2 se distingue par trois raisons pratiques :
- Contexte long : Jusqu'à 128 000 fenêtres de contexte de jetons, ce qui le rend adapté aux documents longs, aux contrats juridiques ou à la recherche multi-documents.
- Conception axée sur le raisonnement : Le modèle intègre la chaîne de pensée (« réflexion ») dans les flux de travail et dans l’utilisation des outils — un changement vers des applications agentiques qui nécessitent des étapes de raisonnement intermédiaires.
- Coût et efficacité : L'introduction de DSA (attention parcimonieuse) réduit le temps de calcul pour les longues séquences, permettant une inférence beaucoup moins coûteuse pour les grands contextes.
Qu'est-ce que DeepSeek-V3.2-Speciale et en quoi diffère-t-il de la version de base v3.2 ?
Qu'est-ce qui rend la variante « Spéciale » si spéciale ?
DeepSeek V3.2-Speciale est un calcul haute performance, raisonnement haute performance Speciale est une variante de la famille v3.2. Comparée à la variante équilibrée v3.2, elle est optimisée (et post-entraînée) spécifiquement pour le raisonnement multi-étapes, les mathématiques et les tâches d'agentivité. Elle utilise un apprentissage par renforcement supplémentaire basé sur le retour d'information humain (RLHF) et une chaîne de pensée interne étendue lors de l'entraînement. L'accès temporaire à ce point d'accès et à l'API Speciale a été annoncé comme étant limité dans le temps (expiration prévue le 15 décembre 2025 pour le chemin d'accès Speciale).
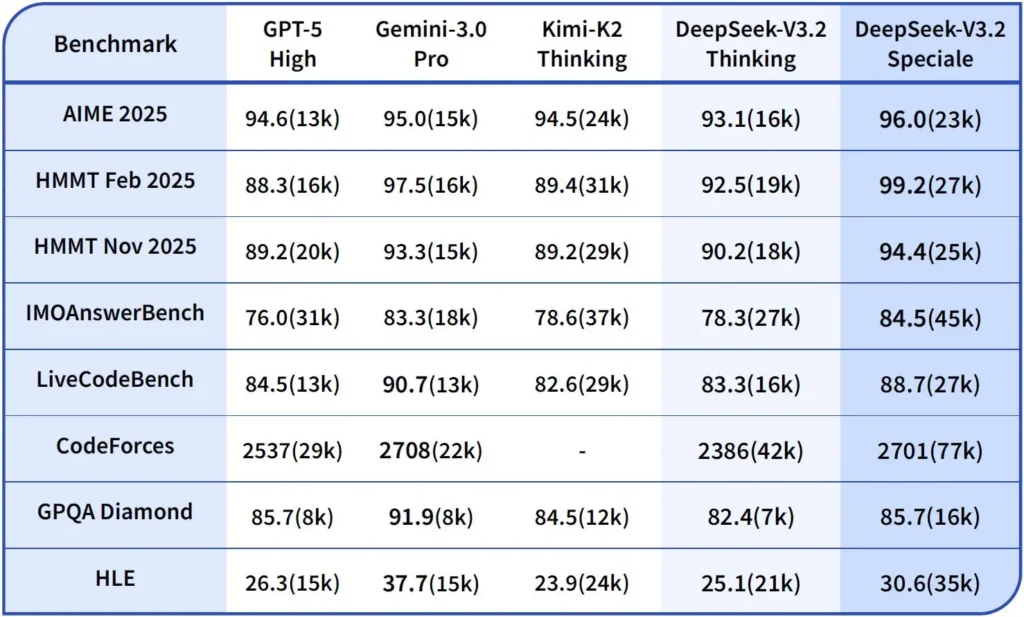
Performances et benchmarks
DeepSeek-V3.2-Speciale est la variante de V3.2 optimisée pour le calcul haute performance et le raisonnement. Cette version spéciale intègre le modèle mathématique précédent, DeepSeek-Math-V2. Elle est conçue pour les charges de travail exigeantes. raisonnement le plus approfondi possible, résolution de problèmes en plusieurs étapes, raisonnement compétitif (par exemple, de type olympiade mathématique) et orchestration complexe des actions des agents.
Il peut démontrer des théorèmes mathématiques et vérifier des raisonnements logiques de manière autonome ; il a obtenu des résultats remarquables dans de nombreuses compétitions internationales.
- Médaille d'or aux Olympiades internationales de mathématiques (OIM)
- Médaille d'or des Olympiades mathématiques chinoises (CMO)
- ICPC (Concours international de programmation informatique) 2e place (Concours humain)
- IOI (Olympiades internationales d'informatique) 10e place (Concours humain)
Qu'est-ce que le mode de raisonnement dans DeepSeek v3.2 ?
DeepSeek expose un explicite mode de pensée/raisonnement ce qui amène le modèle à produire un Chaîne de pensée (CoT) en tant que partie distincte de la sortie avant Voici la réponse finale. L'API expose ce CoT afin que les applications clientes puissent l'inspecter, l'afficher ou l'extraire.
Mécanismes — ce que l'API fournit
reasoning_contentchamp: lorsque le mode réflexion est activé, la structure de réponse comprend unreasoning_contentchamp (le CoT) au même niveau que le finalcontentCela permet aux clients d'accéder par programmation aux étapes internes.- Appels d'outils pendant la réflexionLa version 3.2 prétend prendre en charge les appels d'outils dans les La trajectoire de réflexion : le modèle peut entrelacer les étapes de raisonnement et les invocations d’outils, ce qui améliore les performances des tâches complexes.
Comment l'API DeepSeek v3.2 implémente le raisonnement
La version 3.2 introduit un mécanisme d'API de chaîne de raisonnement standardisé afin de maintenir une logique de raisonnement cohérente tout au long des conversations à plusieurs tours :
- Chaque requête de raisonnement contient un
reasoning_contentchamp au sein du modèle ; - Si l'utilisateur souhaite que le modèle continue à raisonner, ce champ doit être renvoyé au tour suivant ;
- Lorsqu'une nouvelle question se pose, l'ancienne
reasoning_contentdoit être dégagée pour éviter toute contamination logique ; - Le modèle peut exécuter la boucle « raisonnement → appel d'outil → nouveau raisonnement » plusieurs fois en mode raisonnement.
Comment accéder à l'API DeepSeek v3.2 et l'utiliser ?
Court: CometAPI est une passerelle de type OpenAI qui expose de nombreux modèles (y compris les familles DeepSeek) via https://api.cometapi.com/v1 vous pouvez donc changer de modèle en modifiant le model chaîne de caractères dans les requêtes. Inscrivez-vous sur CometAPI et obtenez d'abord votre clé API.
Pourquoi utiliser CometAPI plutôt que DeepSeek direct ?
- CometAPI centralise la facturation, les limites de débit et la sélection du modèle (pratique si vous prévoyez de changer de fournisseur sans modifier le code).
- Points de terminaison DeepSeek directs (par exemple,
https://api.deepseek.com/v1Il existe encore des points de terminaison spécifiques au fournisseur, qui peuvent parfois exposer des fonctionnalités propres à ce dernier. Privilégiez CometAPI pour plus de simplicité ou le point de terminaison direct du fournisseur pour accéder aux contrôles natifs. Vérifiez quelles fonctionnalités (par exemple, Speciale, points de terminaison expérimentaux) sont disponibles via CometAPI avant de les utiliser.
Étape A — Créez un compte CometAPI et obtenez une clé API
- Accédez à CometAPI (inscription / console) et générez une clé API (le tableau de bord l'affiche généralement).
sk-...Gardez le secret. API Comet
Étape B — Confirmer le nom exact du modèle disponible
- Consultez la liste des modèles pour confirmer la chaîne de caractères exacte exposée par CometAPI (les noms de modèles peuvent inclure des suffixes de variante). Utilisez le point de terminaison des modèles avant de coder en dur les noms :
curl -s -H "Authorization: Bearer $COMET_KEY" \
https://api.cometapi.com/v1/models | jq .
Recherchez l'entrée DeepSeek (par exemple deepseek-v3.2 or deepseek-v3.2-exp) et notez l'identifiant exact. CometAPI expose un /v1/models inscription.
Étape C — Effectuer un appel de chat basique (curl)
remplacer <COMET_KEY> et deepseek-v3.2 avec l'identifiant du modèle que vous avez confirmé :
curl https://api.cometapi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <COMET_KEY>" \
-d '{
"model": "deepseek-v3.2",
"messages": [
{"role":"system","content":"You are a helpful assistant."},
{"role":"user","content":"Summarize DeepSeek v3.2 in two sentences."}
],
"max_tokens":300
}'
Il s'agit du même modèle d'appel de type OpenAI : CometAPI transmet la requête au fournisseur sélectionné.
Compatibilité et précautions
- Permet d'activer le mode Think dans l'environnement Claude Code ;
- Dans la ligne de commande (CLI), il suffit de saisir le nom du modèle deepseek-reasoner ;
- Cependant, il se peut qu'il ne soit pas compatible avec des outils non standard tels que Cline et RooCode pour le moment ;
- Il est recommandé d'utiliser le mode non-pensée pour les tâches ordinaires et le mode pensée pour les raisonnements logiques complexes.
Modèles d'adoption pratiques : quelques exemples d'architectures
1 — Agent d'assistance pour les flux de travail des développeurs
- Mode: Mode spécial (mode réflexion) activé pour la génération de code complexe et la création de tests ; mode de chat rapide pour l'assistant intégré.
- Sécurité: Utilisez des contrôles de pipeline CI et l'exécution de tests en bac à sable pour le code généré.
- hébergement: API ou auto-hébergé sur vLLM + cluster multi-GPU pour les contextes de grande envergure.
2 — Analyse documentaire pour les équipes juridiques et financières
- Mode: V3.2 avec des optimisations DSA pour les contextes longs afin de traiter les contrats longs et de produire des résumés structurés et des listes d'actions.
- Sécurité: Validation par un avocat humain des décisions prises en aval ; suppression des données personnelles identifiables avant l’envoi aux terminaux hébergés.
3 — Orchestrateur de pipeline de données autonome
- Mode: Mode de réflexion pour planifier les tâches ETL en plusieurs étapes, appeler des outils pour interroger les bases de données et exécuter des tests de validation.
- Sécurité: Mettre en œuvre une confirmation des actions et des contrôles vérifiables avant toute opération irréversible (par exemple, une écriture destructive dans la base de données).
Chacun des modèles ci-dessus est réalisable avec les modèles de la famille V3.2 actuels, mais vous devez associer le modèle à des outils de vérification et à une gouvernance prudente.
Comment optimiser les coûts et les performances avec la version 3.2 ?
Utilisez délibérément les deux modes
- Mode rapide pour les micro-interactions : utilisez le mode outil sans réflexion pour les extractions courtes, les conversions de format ou les appels API directs où la latence est importante.
- Mode de réflexion pour la planification et la vérification : acheminez les tâches complexes, les agents à actions multiples ou les décisions critiques vers le mode de réflexion. Capturez les étapes intermédiaires et effectuez une vérification (automatisée ou humaine) avant d’exécuter les actions critiques.
Quel modèle dois-je choisir ?
- deepseek-v3.2 — modèle de production équilibré pour les tâches d'agents générales.
- deepseek-v3.2-Speciale — variante spécialisée de raisonnement lourd ; peut être initialement disponible uniquement via l'API et utilisée lorsque vous avez besoin des meilleures performances possibles en matière de raisonnement/d'évaluation des performances (et que vous acceptez un coût potentiellement plus élevé).
Conseils et astuces pratiques pour maîtriser les coûts
- Ingénierie des invites : veillez à la concision des instructions système et évitez l’envoi de contexte redondant. Instructions système explicites : utilisez des invites système indiquant le mode de fonctionnement souhaité, par exemple : « Vous êtes en mode RÉFLEXION ; veuillez indiquer votre plan avant d’utiliser les outils. » Pour le mode outil, ajoutez des contraintes telles que : « Lors de l’interaction avec l’API de la calculatrice, veuillez ne générer que du JSON contenant les champs suivants. »
- Segmentation et augmentation de la récupération : utiliser un outil de récupération externe pour n’envoyer que les segments les plus pertinents pour chaque question de l’utilisateur.
- Température et échantillonnage : température plus basse pour les interactions avec les outils afin d’accroître le déterminisme ; température plus élevée pour les tâches exploratoires ou d’idéation.
Évaluer et mesurer
- Considérez les résultats comme non fiables jusqu'à vérification : même les résultats de raisonnement peuvent être erronés. Ajoutez des contrôles déterministes (tests unitaires, vérifications de type) avant d'entreprendre des actions irréversibles.
- Effectuez des tests A/B sur un échantillon de charge de travail (latence, utilisation des jetons, exactitude) avant de valider une variante. La version 3.2 a enregistré des gains importants sur les tests de raisonnement, mais le comportement réel de l'application dépend de la conception des invites et de la distribution des entrées.
FAQ
Q : Quelle est la méthode recommandée pour obtenir le CoT à partir du modèle ?
A: Utilisez l'option deepseek-reasoner modèle ou ensemble thinking/thinking.type = enabled dans votre demande. La réponse comprend reasoning_content (CoT) et le final content.
Q : Le modèle peut-il faire appel à des outils externes lorsqu'il est en mode de réflexion ?
R : Oui — La version 3.2 a introduit la possibilité d'utiliser les outils en modes de réflexion et de non-réflexion ; le modèle peut émettre des appels d'outils structurés lors du raisonnement interne. strict Utilisez le mode et des schémas JSON clairs pour éviter les appels malformés.
Q : L'utilisation du mode de réflexion augmente-t-elle les coûts ?
R : Oui — le mode de réflexion génère des jetons CoT intermédiaires, ce qui augmente la consommation de jetons et donc le coût. Concevez votre système de manière à n'activer le mode de réflexion que lorsque cela est nécessaire.
Q : Quel point de terminaison et quelle URL de base dois-je utiliser ?
A : CometAPI fournit des points de terminaison compatibles avec OpenAI. L'URL de base par défaut est https://api.cometapi.com et le point de terminaison de chat principal est /v1/chat/completions (ou /chat/completions (en fonction de l'URL de base que vous choisissez).
Q : Un outillage spécial est-il nécessaire pour utiliser l'appel d'outils ?
R : Non, l'API prend en charge les déclarations de fonctions structurées en JSON. Vous devez fournir le tools Ce paramètre permet de schématiser et de gérer le cycle de vie des fonctions JSON dans votre application : réception d’un appel de fonction JSON, exécution de la fonction, puis renvoi des résultats au modèle pour la poursuite ou la fermeture. Le mode « Thinking » ajoute l’exigence de renvoyer un résultat. reasoning_content ainsi que les résultats de l'outil.
Conclusion
DeepSeek V3.2 et DeepSeek-V3.2-Speciale représentent une nette évolution vers ouvert, centré sur le raisonnement Les LLM explicitent le raisonnement logique et prennent en charge les flux de travail des outils d'agents. Ils offrent de nouvelles primitives puissantes (structures de données et algorithmes, modes de pensée, formation à l'utilisation des outils) qui peuvent simplifier la création d'agents fiables, à condition de prendre en compte le coût des jetons, une gestion rigoureuse de l'état et des contrôles opérationnels.
Les développeurs peuvent accéder API Deepseek v3.2 etc. via CometAPI, la dernière version du modèle est constamment mis à jour avec le site officiel. Pour commencer, explorez les capacités du modèle dans la section cour de récréation et consultez le Guide de l'API Pour des instructions détaillées, veuillez vous connecter à CometAPI et obtenir la clé API avant d'y accéder. API Comet proposer un prix bien inférieur au prix officiel pour vous aider à vous intégrer.
Prêt à partir ?→ Essai gratuit de Deepseek v3.2 !
Si vous souhaitez connaître plus de conseils, de guides et d'actualités sur l'IA, suivez-nous sur VK, X et Discord!