

Uni-1 de Luma AI est plus qu'un nouveau modèle texte‑vers‑image. Dans la propre présentation de Luma, il s'agit d'un « modèle de raisonnement multimodal capable de générer des pixels », construit sur une « Intelligence unifiée » afin de comprendre l'intention, répondre aux directives et « réfléchir avec vous ». Le rapport technique de l'entreprise indique que le modèle utilise un transformer auto‑régressif à décodeur seul dans lequel textes et images sont représentés dans une seule séquence entrelacée, et que Uni‑1 peut effectuer un raisonnement interne structuré avant et pendant la synthèse d'image. Cette combinaison fait de Uni‑1 l'une des sorties de modèles d'image les plus intéressantes de 2026.
Qu'est-ce que le modèle d'image UNI‑1 ?
Uni‑1 est le nouveau modèle d'image de Luma AI pour les tâches qui nécessitent à la fois compréhension et génération au sein d’un même système. Luma le présente comme un modèle de raisonnement multimodal plutôt qu’un simple moteur d’image basé uniquement sur la diffusion, ce qui importe parce que le modèle est conçu pour faire plus que produire des résultats visuellement plaisants : il est conçu pour interpréter des instructions, préserver des contraintes de référence et raisonner sur la logique de la scène dans le cadre de la génération. Le rapport technique de l’entreprise décrit Uni‑1 comme son premier modèle unifié compréhension‑et‑génération sur la voie de l’intelligence multimodale générale.
Pourquoi Uni‑1 est différent
L’ancienne chaîne a un plafond : la génération d’images sans compréhension ne peut aller que jusqu’à un certain point. Uni‑1 est présenté comme un pas vers « l’intelligence unifiée », où le langage, la perception, l’imagination, la planification et l’exécution sont gérés dans une seule architecture. Ce n’est pas qu’une affaire de marque. Uni‑1 peut passer de la ressemblance visuelle à la composition intentionnelle, à la plausibilité et à la logique de scène.
L’histoire plus large est que les modèles d’image deviennent plus agentifs. La nouvelle pile d’images de Google met désormais l’accent sur l’édition conversationnelle, l’ancrage par la recherche, la fusion multi‑images et la cohérence des personnages ; la famille GPT Image d’OpenAI insiste sur la multimodalité native et le suivi d’instructions. Uni‑1 rejoint ce mouvement, mais pousse plus loin l’idée que le modèle devrait « réfléchir » à l’image avant de la dessiner. Cela rend Uni‑1 particulièrement intéressant pour des workflows où la précision et la répétabilité comptent autant que l’esthétique.
Comment Uni‑1 fonctionne‑t‑il concrètement ?
🔬 Processus de tokenisation
- Texte → séquence de tokens
- Image → patchs tokenisés
- Combinés en une séquence entrelacée unique
🔁 Processus de génération
- Prompt d’entrée + références
- Le modèle effectue un raisonnement interne
- Planifie la composition
- Génère les tokens séquentiellement
Mathématiquement : P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Couche de raisonnement interne
Uni‑1 :
- Décompose les instructions
- Résout les contraintes
- Planifie la mise en page avant le rendu
👉 C’est un progrès majeur vs les modèles de diffusion.
Génération auto‑régressive à décodeur seul
Le détail technique le plus important est qu’Uni‑1 est auto‑régressif plutôt que basé sur la diffusion. Le rapport technique de Luma indique qu’il s’agit d’un transformer auto‑régressif à décodeur seul, et que le texte et les images sont encodés dans une seule séquence entrelacée. En termes simples, le modèle ne part pas simplement du bruit pour « dé‑bruiter » progressivement vers une image. À la place, il génère des tokens pas à pas, ce qui lui permet de raisonner sur le prompt, de résoudre les contraintes et de planifier la composition avant et pendant le rendu.
🔬 Processus de tokenisation
- Texte → séquence de tokens
- Image → patchs tokenisés
- Combinés en une séquence entrelacée unique
Diffusion vs auto‑régressif
| Caractéristique | Modèles de diffusion | Uni‑1 (auto‑régressif) |
|---|---|---|
| Génération | Bruit → Image | Jeton par jeton |
| Raisonnement | Limité | Solide |
| Édition | Faible | Multi‑tours |
| Rendu du texte | Faible | Solide |
| Contrôle | Faible | Élevé |
Architecture de base
Uni‑1 est :
- Un transformer auto‑régressif à décodeur seul
- Un espace de tokens partagé pour texte + images
Cette architecture est importante car elle donne au modèle une chance de maintenir la cohérence lorsque le prompt est compliqué. Luma indique qu’Uni‑1 peut décomposer les instructions, résoudre des contraintes conflictuelles et planifier l’image avant le début du rendu. C’est particulièrement utile pour des tâches comme l’achèvement structuré de scènes, le placement multi‑sujets, le raffinement multi‑tours et les éditions qui exigent que la sortie reste fidèle à une image de référence tout en obéissant à de nouvelles instructions.
Ce que le modèle semble mieux savoir faire
Apprendre à générer des images améliore la compréhension. Luma affirme que l’entraînement à la génération d’images améliore de manière significative la compréhension visuelle fine, notamment sur les régions, objets et mises en page. C’est pourquoi Uni‑1 n’est pas un générateur à sens unique, mais un système unifié dont la génération et la compréhension se renforcent mutuellement. Côté inférence, cela signifie qu’Uni‑1 cherche à combler l’écart entre « voir » et « faire ». C’est un progrès majeur vs les modèles de diffusion.
Processus de génération:
- Prompt d’entrée + références
- Le modèle effectue un raisonnement interne
- Planifie la composition
- Génère les tokens séquentiellement
Mathématiquement : P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Quelles fonctionnalités et quels avantages clés Uni‑1 offre‑t‑il ?
Fort suivi des instructions et dirigibilité
Le point fort d’Uni‑1 est le contrôle. Le modèle est conçu pour l’édition de précision, l’usage structuré des références et des workflows reproductibles. Pour les créateurs, cela signifie moins de paris sur les prompts et des résultats plus répétables.
L’un des avantages pratiques d’Uni‑1 est qu’il est conçu pour l’itération contrôlée. Les seeds permettent aux utilisateurs de reproduire les résultats, tandis que les rôles de référence aident le modèle à savoir si une image doit guider l’identité du personnage, l’ambiance, la palette ou la composition. Cela rend Uni‑1 plus facile à diriger qu’un modèle uniquement piloté par prompt, en particulier pour les équipes produisant des publicités, des storyboards, des maquettes produit ou des assets de marque où la cohérence est essentielle.
Génération basée sur des références qui préserve l’identité
Un avantage majeur est la gestion des références. Luma indique explicitement qu’Uni‑1 utilise des contrôles ancrés aux sources et peut préserver l’identité, la composition et les contraintes visuelles clés à partir d’une ou plusieurs références. Cela le rend attrayant pour des workflows commerciaux tels que des personnages de marque, des maquettes produit, des assets de campagne et tout projet où un sujet doit rester reconnaissable à travers des variantes. C’est l’une des différences les plus nettes avec des systèmes d’images plus purement esthétiques.
Aisance culturelle et diversité des styles
Luma met également l’accent sur une génération sensible aux cultures. Sa section « Cultured » renvoie à des mèmes, du manga, des looks cinématographiques, des photos casual, des sports et des images animalières, montrant que le modèle est conçu pour opérer à travers des langages visuels plutôt qu’un style générique. C’est important, car un bon modèle d’image moderne ne doit pas seulement rendre une scène réaliste ; il doit aussi comprendre les conventions visuelles de la culture internet, du design éditorial, de l’illustration stylisée et du contenu social.
La pensée multimodale comme choix de conception
Le vrai différenciateur n’est pas seulement qu’Uni‑1 génère des images, mais que Luma présente la génération d’images comme une tâche de raisonnement. Uni‑1 peut effectuer un raisonnement interne structuré et l’apprentissage de la génération d’images améliore la compréhension visuelle fine sur les régions, objets et mises en page. Cela suggère un modèle fait pour comprendre la scène avant de la rendre, plutôt que de simplement approximer le prompt statistiquement.
Benchmarks de performance
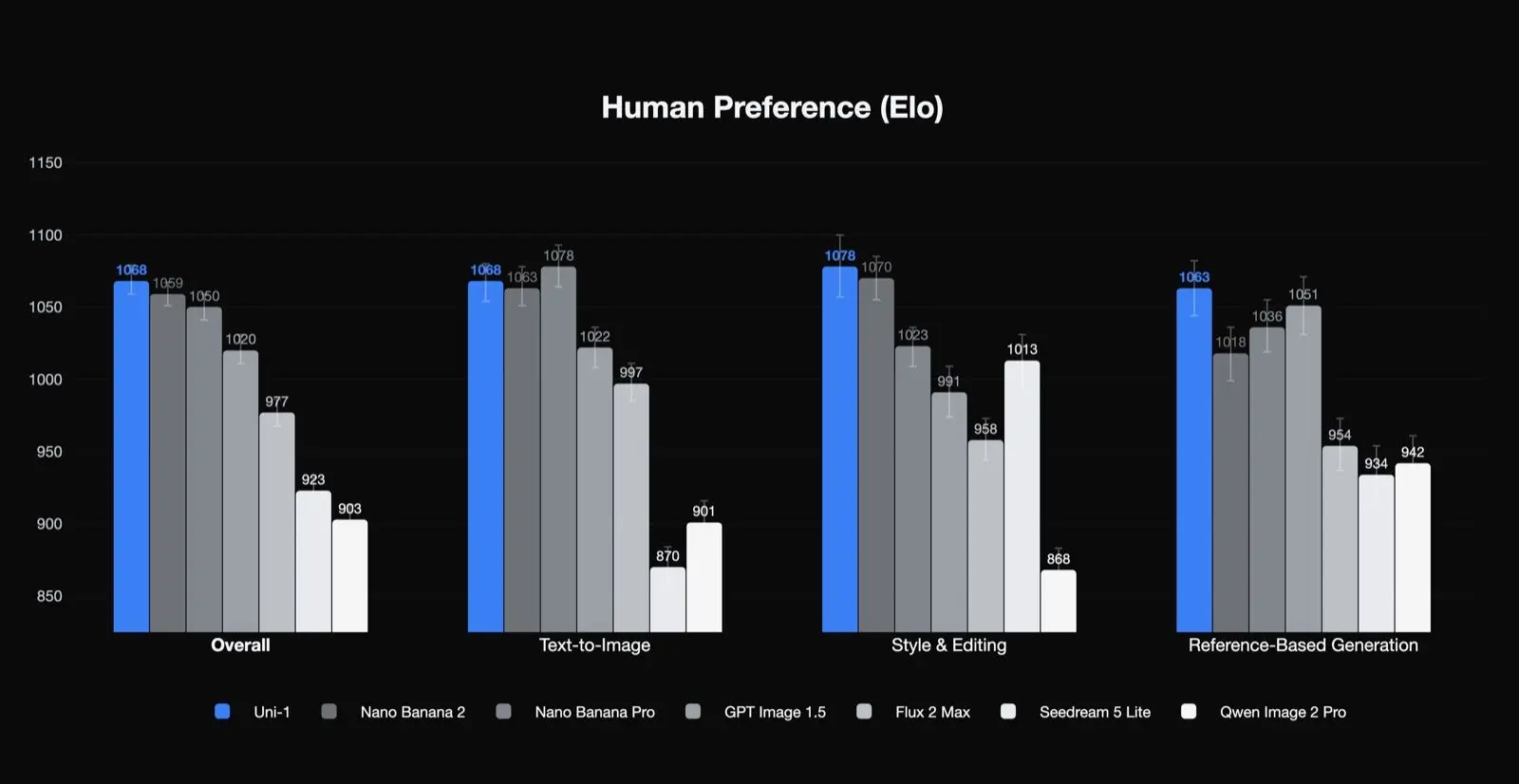
Résultats de préférence humaine selon Luma
Uni‑1 est premier en Elo de préférence humaine pour la qualité globale, le style et l’édition, ainsi que la génération basée sur des références, et second en texte‑vers‑image. C’est un résultat significatif car il suggère que le modèle est particulièrement fort dans les types de tâches qui intéressent les équipes de production : édition, cohérence et transformation guidée. Cela suggère également que ses meilleurs cas d’usage ne se limitent peut‑être pas à de la génération texte‑vers‑image en un seul essai.
RISEBench : édition visuelle informée par le raisonnement
Le benchmark le plus marquant est RISEBench, qui évalue l’édition visuelle informée par le raisonnement temporel, causal, spatial et logique. Des reportages tiers sur le lancement de Luma indiquent qu’Uni‑1 obtient 0,51 au global sur RISEBench, devant Nano Banana 2 de Google à 0,50, Nano Banana Pro à 0,49 et GPT Image 1.5 d’OpenAI à 0,46. En raisonnement spatial, Uni‑1 est annoncé à 0,58 contre 0,47 pour Nano Banana 2. En raisonnement logique, Uni‑1 est annoncé à 0,32, plus du double des 0,15 de GPT Image 1.5. Les marges ne sont pas énormes globalement, mais elles le sont dans les catégories de raisonnement les plus difficiles.

ODinW‑13 et l’affirmation « la génération améliore la compréhension »
Uni‑1 obtient également de bons résultats sur ODinW‑13, un benchmark de détection dense à vocabulaire ouvert. Des informations issues des données techniques de Luma indiquent que le modèle complet atteint 46,2 mAP, presque au niveau de Gemini 3 Pro de Google à 46,3. Les mêmes sources indiquent qu’une variante « compréhension seule » atteint 43,9 mAP, ce qui implique que l’entraînement à la génération améliore la compréhension de 2,3 points. C’est un constat notable car il étaye la thèse centrale de Luma : la génération d’images et la compréhension d’images peuvent se renforcer mutuellement plutôt que d’être des objectifs concurrents.
Tarif de l’API Uni‑1
| Prix d'entrée (texte) | $0.50 |
|---|---|
| Prix d'entrée (images) | $1.20 |
| Prix de sortie (texte et raisonnement) | $3.00 |
| Prix de sortie (images) | $45.45 |
Côté grand public, la page de tarification de Luma liste Plus à $30/mois, Pro à $90/mois et Ultra à $300/mois, avec des crédits d’essai gratuits inclus dans tous les plans. Il y a donc essentiellement deux couches de tarification à considérer : l’abonnement consommateur à la plateforme et la tarification API au niveau du modèle pour un usage en production.
Pour l’instant, l’API Uni‑1 de CometAPI est « Bientôt disponible », avec une remise annoncée au lancement. Actuellement, CometAPI propose également d’excellents modèles d’images bruts, tels que Midjourney et Nano Banana 2.
Uni‑1 vs GPT Image 1.5 vs Nano Banana 2
Uni‑1 face au Nano Banana 2 de Google
Nano Banana 2 semble plus fort sur l’étendue de la gestion des références et l’intégration à l’écosystème. Google met l’accent sur l’ancrage à la recherche d’images, l’itération conversationnelle et des workflows riches en références avec jusqu’à 14 références. Uni‑1, en revanche, est plus explicitement présenté autour du raisonnement, de la plausibilité de scène et de l’édition de précision dans une architecture unifiée. En termes pratiques, Google semble optimisé pour la vitesse, l’échelle de production grand public et l’ancrage natif Google ; Luma semble optimisé pour le raisonnement visuel structuré et l’édition d’image dirigible.
Dans les comparaisons publiques autour d’Uni‑1, le compromis est clair : Nano Banana 2 reste très fort pour la qualité et la vitesse du pur texte‑vers‑image, tandis qu’Uni‑1 pousse davantage sur l’édition orientée raisonnement, le contrôle par références et la fidélité aux instructions.
Uni‑1 face au GPT Image d’OpenAI
Dans les rapports de benchmark, Uni‑1 devance GPT Image 1.5 sur RISEBench global et plus nettement sur le raisonnement logique. Comparé à la famille GPT Image d’OpenAI, Uni‑1 est positionné plus étroitement et plus agressivement autour du raisonnement visuel et de l’édition contrôlée. La documentation d’OpenAI met en avant la connaissance du monde, la compréhension multimodale et la conscience contextuelle ; celle de Luma met en avant le raisonnement interne structuré, le contrôle ancré sur des références et des compétences d’édition visuelle évaluées par benchmark. Ainsi, bien que les deux soient multimodaux, Uni‑1 est plus clairement un « modèle de raisonnement spécialiste de l’image », tandis que GPT Image apparaît comme un système multimodal général qui génère très bien des images.
Comparaison des prix entre les trois
Côté prix, la comparaison dépend de la taille de sortie et du niveau de produit, donc ce n’est pas parfaitement comparable. L’équivalent 2048px publié pour Uni‑1 est d’environ $0.0909 par image. La dernière page de tarification des modèles d’images de Google indique $0.134 par image 1K/2K et $0.24 par image 4K pour son dernier aperçu Gemini image, tandis que la page de tarification de GPT Image d’OpenAI indique un prix par image de $0.011 en basse qualité pour 1024x1024, $0.042 en qualité moyenne et $0.167 en haute qualité, avec de plus grandes sorties haute qualité à $0.25. En d’autres termes, OpenAI peut être bien moins cher à l’entrée de gamme, Google est agressif sur la vitesse et l’échelle, et Uni‑1 se situe au milieu avec un solide profil prix‑performance orienté 2K.
Différences philosophiques
| Modèle | Approche |
|---|---|
| Uni‑1 | Intelligence multimodale unifiée |
| GPT Image | LLM + génération d’images |
| Nano Banana 2 | Diffusion optimisée pour la production |
Tableau de comparaison détaillé
| Fonctionnalité | Uni‑1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Architecture | Auto‑régressif | Hybride | Diffusion |
| Unification multimodale | ✅ Natif | Partielle | ❌ |
| Capacité de raisonnement | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Qualité d’image | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Rendu du texte | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Flux d’édition | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Vitesse | Moyenne | Rapide | Rapide |
| Contrôle | Élevé | Moyen | Moyen |
CometAPI propose des images brutes interactives pour GPT Image 1.5, Nano Banana 2, et le futur Uni‑1, ainsi que la programmation API. Des tarifs remisés et des options à l’usage en font un choix privilégié pour les développeurs.
À quoi Uni‑1 convient le mieux
Uni‑1 semble particulièrement fort pour les cas où vous avez besoin de répétabilité, de cohérence des personnages ou de contrôle multi‑références. Cela inclut des campagnes de marque, des maquettes produit, des concepts éditoriaux, des storyboards, des variantes localisées et des éditions d’image où la composition doit rester intacte mais où le style ou l’environnement doit changer. Les propres exemples de Luma insistent fortement sur ces cas d’usage, et la séparation « Create vs Modify » du modèle est fondamentalement une réponse directe aux points de douleur courants en production.
Si votre travail consiste surtout à « faire quelque chose de joli à partir d’un seul prompt », le différenciateur peut sembler moins spectaculaire. Mais si votre workflow est « faire cinq versions liées, garder le même personnage, préserver le cadrage, changer l’éclairage et rendre le tout reproductible la semaine prochaine », la conception d’Uni‑1 prend tout son sens. C’est une inférence, mais elle découle naturellement des fonctions de contrôle mises en avant par Luma.
Bonnes pratiques pour obtenir de meilleurs résultats avec Uni‑1
Commencez par utiliser le mode approprié. Les directives de Luma sont simples : Create lorsque vous voulez une nouvelle scène, Modify lorsque vous voulez préserver une scène existante. Mélanger ces intentions rend les sorties plus instables.
Utilisez les libellés de référence comme un professionnel. Luma recommande des phrases telles que « Use IMAGE1 as a STYLE reference » ou « Use IMAGE2 as LIGHTING. » Le modèle fonctionne mieux lorsque chaque référence a un rôle, plutôt qu’une « inspiration » vague.
Verrouillez le seed après avoir trouvé quelque chose de bon. Luma recommande explicitement d’explorer sans seed d’abord, puis d’enregistrer le seed une fois que vous avez un bon résultat. Ensuite, changez une variable à la fois. C’est le moyen le plus simple de transformer la génération en un système de production contrôlé.
Soyez spécifique et concret. Luma déconseille les mots vagues comme « magnifique » ou « incroyable », et encourage à la place des esthétiques nommées telles que « affiche de film giallo italien des années 1970 » ou des indications exactes de style caméra. En pratique, les prompts spécifiques l’emportent généralement sur les prompts poétiques parce que le modèle peut s’ancrer sur une structure réelle.
Utilisez la chaîne Create → Modify. Luma souligne explicitement que c’est l’un de ses workflows les plus puissants : explorez en Create, puis affinez en Modify. C’est le sweet spot pour un travail de production sérieux, car cela réduit les retours en arrière et préserve les bonnes parties d’une composition tout en resserrant les détails.
Verdict final
Uni‑1 est l’affirmation la plus claire de Luma que la génération d’images évolue de « prompt in, picture out » vers une création visuelle guidée par le raisonnement. Ses forces publiques sont le contrôle, la gestion des références, la reproductibilité et une architecture de modèle qui garde le langage et les pixels dans le même système.
Pour les créateurs et équipes qui se soucient de visuels à fort taux de clics, de personnages cohérents, d’éditions précises et d’une tarification haute résolution claire, Uni‑1 est un modèle à surveiller de près. Si le déploiement API se passe bien, il pourrait devenir l’une des alternatives les plus intéressantes à Nano Banana 2 de Google et GPT Image 1.5 d’OpenAI en 2026.
Vous envisagez de commencer à créer des images brutes ? CometAPI, une plateforme d’agrégation unique pour les API de modèles multimodaux, vous accueille !