

Qwen2.5-VL-32B L'API a attiré l'attention pour son performance exceptionnelle dans diverses tâches complexes, combinant à la fois données d'image et de texte pour une compréhension enrichie du monde. Développé par Alibaba, ce modèle de 32 milliards de paramètres est une mise à niveau du modèle précédent Qwen2.5-VL série, repoussant les limites de Raisonnement piloté par l'IA et compréhension visuelle.

Présentation du Qwen2.5-VL-32B
Qwen2.5-VL-32B est un modèle multimodal open source de pointe conçu pour gérer une gamme de tâches impliquant à la fois du texte et des images. Avec son 32 milliards de paramètres, il offre une architecture puissante pour reconnaissance d'image, raisonnement mathématique, génération de dialogues, et bien plus encore. Son amélioration capacités d'apprentissage, basé sur l’apprentissage par renforcement, lui permettent de générer des réponses qui correspondent mieux aux préférences humaines.
Principales caractéristiques et fonctions
Qwen2.5-VL-32B démontre des capacités remarquables dans de nombreux domaines :
Compréhension et description de l'image:Ce modèle excelle dans l'analyse d'image, identifiant avec précision les objets et les scènes. Il peut générer des descriptions détaillées en langage naturel et même fournir des informations détaillées dans les attributs des objets et leurs relations.
Raisonnement mathématique et logique:Le modèle est équipé pour résoudre des problèmes mathématiques complexes, allant de de la géométrie à l'algèbre—en employant Raisonnement en plusieurs étapes avec une logique claire et des résultats structurés.
Génération de texte et dialogue:Grâce à son modèle linguistique avancé, Qwen2.5-VL-32B génère des réponses cohérentes et contextuellement pertinentes à partir de textes ou d'images saisis. Il prend également en charge dialogue à plusieurs tours, permettant des interactions plus naturelles et continues.
Réponse visuelle aux questions:Le modèle peut répondre à des questions liées au contenu de l'image, telles que reconnaissance d'objets et description de la scène, offrant des capacités sophistiquées de logique visuelle et d'inférence.
Fondements techniques du Qwen2.5-VL-32B
Pour comprendre la puissance du Qwen2.5-VL-32B, il est essentiel d'explorer ses principes techniques. Voici les aspects clés qui contribuent à ses performances :
- Pré-formation multimodale:Le modèle a été pré-entraîné à l'aide de ensembles de données à grande échelle composé des deux données de texte et d'imageCela lui permet d’apprendre diverses caractéristiques visuelles et linguistiques, facilitant ainsi une compréhension intermodale transparente.
- Architecture de transformateur:Construit sur le robuste Architecture de transformateur, le modèle exploite à la fois les codeur et décodeur structures pour traiter les entrées d'images et de textes, générant des sorties très précises. mécanisme d'auto-attention lui permet de se concentrer sur les composants critiques des données d'entrée, améliorant ainsi leur précision.
- Optimisation de l'apprentissage par renforcementQwen2.5-VL-32B bénéficie de l'apprentissage par renforcement, où il est affiné en fonction des retours humains. Ce processus garantit des réponses plus précises. aligné sur les préférences humaines tout en optimisant plusieurs objectifs tels que précision, logiqueet la fluidité.
- Alignement visuo-langage: À travers apprentissage contrasté et des stratégies d'alignement, le modèle garantit que les deux caractéristiques visuelles et informations textuelles sont correctement intégrés dans le espace linguistique, ce qui le rend très efficace pour tâches multimodales.
Points saillants du rendement
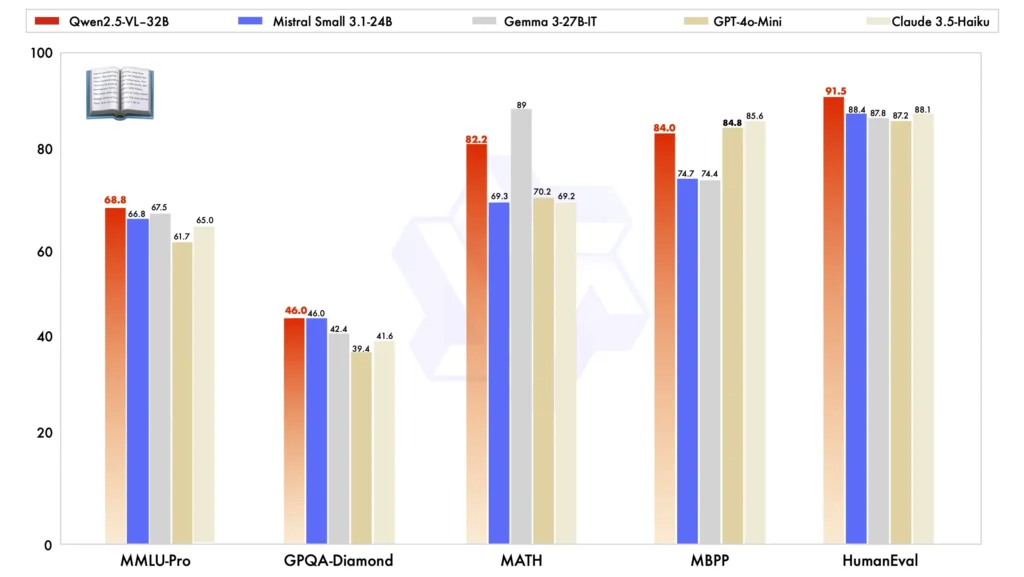
Comparé à d'autres modèles à grande échelle, le Qwen2.5-VL-32B se distingue dans plusieurs critères clés, mettant en valeur ses une performance supérieure à la fois multimodal et tâches en texte brut:
Comparaison de modèles:Contre d'autres modèles comme Mistral-Petit-3.1-24B et Gemma-3-27B-ITLe Qwen2.5-VL-32B présente des capacités considérablement améliorées. Il est même remarquable qu'il surpasse le plus grand Qwen2-VL-72B dans diverses tâches.
Performance de tâches multimodales: En complexe tâches multimodales tel que MMMU, MMMU-Proet MathVistaLe Qwen2.5-VL-32B excelle, offrant des résultats précis qui le distinguent des autres modèles de taille similaire.
Benchmark MM-MT:Par rapport à son prédécesseur, Qwen2-VL-72B-Instruct, la nouvelle version montre une amélioration significative, notamment dans sa raisonnement logique et raisonnement multimodal capacités.
Performances en texte brut:Dans les tâches basées sur du texte brut, Qwen2.5-VL-32B s'est imposé comme le meilleur interprète dans sa catégorie, offrant génération de texte améliorée, raisonnement, et la précision globale.
Ressources du projet
Pour les développeurs et les passionnés d’IA qui souhaitent explorer davantage Qwen2.5-VL-32B, plusieurs ressources clés sont disponibles :
- Site officiel: Projet Qwen2.5-VL-32B
- Modèle HuggingFace: HuggingFace Qwen2.5-VL-32B-Instruct
Applications du monde réel
La polyvalence du Qwen2.5-VL-32B le rend adapté à une large gamme de Applications pratiques dans divers secteurs :
Service client intelligent:Le modèle peut être utilisé pour gérer automatiquement les demandes des clients, en tirant parti de sa capacité à comprendre et à générer réponses basées sur du texte et des images.
Assistance pédagogique: En résolvant problèmes mathématiques, interprétant contenu des images, et en expliquant les concepts, cela peut considérablement améliorer le processus d'apprentissage des étudiants.
Image Annotation:Dans les systèmes de gestion de contenu, Qwen2.5-VL-32B peut automatiser la génération de légendes d'images et descriptions, ce qui en fait un outil précieux pour les médias et les industries créatives.
Conduite autonome:En analysant les panneaux de signalisation et les conditions de circulation grâce à ses capacités de traitement visuel, le modèle peut fournir des informations en temps réel pour améliorer sureté de conduite.
Création de contenu:Dans les médias et la publicité, le modèle peut générer texte basé sur des stimuli visuels, aidant les créateurs de contenu à produire des récits convaincants pour les vidéos et les publicités.
Perspectives d'avenir et défis
Bien que Qwen2.5-VL-32B représente un bond en avant dans l’IA multimodale, il reste encore des défis et des opportunités à relever. Réglage fin le modèle pour des tâches plus spécifiques, en l'intégrant à des applications en temps réel et en améliorant son évolutivité La gestion d’ensembles de données multimodaux plus complexes est un domaine qui nécessite des recherches et des développements continus.
De plus, à mesure que de plus en plus de modèles d’IA sont publiés avec des capacités similaires, préoccupations d'ordre éthique contenu généré par l'IA environnant, biaiset confidentialité des données continuent de susciter l'intérêt. Il est essentiel de veiller à ce que le Qwen2.5-VL-32B et les modèles similaires soient formés et utilisés de manière responsable pour assurer leur succès à long terme.
Sujets connexes :Comparaison des 8 meilleurs modèles d'IA les plus populaires de 2025
Conclusion
Qwen2.5-VL-32B est un outil puissant dans l'arsenal des modèles d'IA conçus pour s'attaquer tâches multimodales avec une précision et une sophistication impressionnantes. En intégrant des technologies avancées apprentissage par renforcement, architecture du transformateuret alignement du langage visuel, ce n'est pas seulement surpasse les modèles précédents mais ouvre également des possibilités intéressantes pour des industries allant de l'éducation à conduite autonomeEn tant que technologie open source, elle offre un potentiel énorme aux développeurs et aux utilisateurs d’IA pour expérimenter, optimiser et mettre en œuvre des applications du monde réel.
Comment appeler l'API Qwen2.5-VL-32B depuis CometAPI
1.Se connecter à cometapi.comSi vous n'êtes pas encore notre utilisateur, veuillez d'abord vous inscrire
2.Obtenir la clé API d'identification d'accès de l'interface. Cliquez sur « Ajouter un jeton » au niveau du jeton API dans l'espace personnel, récupérez la clé du jeton : sk-xxxxx et soumettez.
-
Obtenez l'URL de ce site : https://api.cometapi.com/
-
Sélectionnez le point de terminaison Qwen2.5-VL-32B pour envoyer la requête API et définissez le corps de la requête. La méthode et le corps de la requête sont obtenus à partir de notre documentation API de site WebNotre site Web propose également le test Apifox pour votre commodité.
-
Traitez la réponse de l'API pour obtenir la réponse générée. Après l'envoi de la requête API, vous recevrez un objet JSON contenant la complétion générée.