

GLM-5-Turbo is a new foundation LLM from Zhipu AI specifically trained and tuned for agent-style workflows (the company calls the target ecosystem OpenClaw / “lobster” scenarios). It offers a very long context (up to ~200K tokens), streaming and structured outputs, lower tool-call error rates (reported ~0.67% in third-party tests), and materially lower per-token pricing . The model aims to trade a small amount of peak single-turn throughput for much better stability, tool reliability, scheduled/persistent task handling and long-chain execution—useful for autonomous agents, orchestration systems, and multi-tool pipelines.
What is GLM-5-Turbo?
GLM-5-Turbo is presented by Zhipu as a foundation model purpose-built for agent orchestration and complex automated workflows rather than as a general chat or multimodal model. The design choices emphasize:
- Native agent-friendly training (tool use, command following, timed/persistent tasks).
- Very large context windows and output capacity to support long sessions, memory, and chain-of-thought planning.
- Stable, high-throughput inference for long business flows and scheduled tasks.
Unlike traditional LLMs optimized for chat or text generation, GLM-5-Turbo is:
- Agent-first (not chat-first)
- Built for OpenClaw (“lobster”) environments
- Designed for multi-step autonomous workflows
🦞 What does “Lobster Agent” mean?
The “lobster” concept refers to OpenClaw, Zhipu’s AI agent ecosystem where models:
- Use tools dynamically
- Execute long chains of tasks
- Maintain persistent memory
- Operate across terminals, apps, and APIs
GLM-5-Turbo is deeply optimized for this paradigm, solving key agent problems like:
- Tool-call reliability
- Task decomposition
- Long-horizon planning
- Execution stability
Key features and why they matter
Long context + huge output capacity (200K / 128K)
A 200K token context window and 128K output capability allow GLM-5-Turbo to:
- Keep extended memory of prior context (conversations, tool outputs, intermediate results).
- Produce very long generated artifacts (multi-stage plans, long reports, codebases) without repeated context stitching.
- Host multi-turn agents that must retain the full execution history for accurate decision-making.
This is a deliberate technical choice for agents — instead of splitting tasks into short prompts, agents can maintain coherent state across thousands of conversational turns or steps.
Agent primitives baked into training
Rather than retrofitting a general-purpose model to agent tasks, GLM-5-Turbo was trained with agent-style objectives (e.g., tool invocation behavior, command/argument parsing). The claimed effect is fewer hallucinations during tool calls, more stable multi-step plans, and improved latency under long runs — all valuable where automation must chain many external APIs or tools reliably.
Throughput and execution stability
GLM-5-Turbo variant improves execution stability and throughput for long business flows compared to generalized large models — the marketing language emphasizes "high throughput execution" and "leading response stability" among similar models. These are meaningful for enterprise agent deployments where a failed step can break an entire pipeline. Independent third-party benchmarks are still emerging.
Benchmark data of GLM-5-Turbo
Note: Zhipu has published internal evaluations, and third-party/academic benchmarks for GLM-5 are available. GLM-5-Turbo is newly released; independent community benchmark runs will take time to appear. Below we list the most defensible, published figures and context.
GLM-5 (reference) — representative published metrics
Zhipu’s GLM-5 (the flagship predecessor to Turbo) reports strong leaderboards in many engineering/workflow tasks — for example:
- SWE-bench Verified: 77.8 (reported in GLM-5 documentation as a leading open-model score).
- Terminal Bench 2.0: 56.2 (reported as top open-model performance on the given distribution).
Those numbers establish GLM-5 as a high baseline in software engineering and execution tasks; GLM-5-Turbo is positioned to trade some raw size/parameter emphasis for better agent reliability and throughput. GLM-5-Turbo showed ~0.67% tool-call error in their comparison runs, materially lower than comparator GLM-5 provider runs that ranged from ~2.33% to 6.41%.
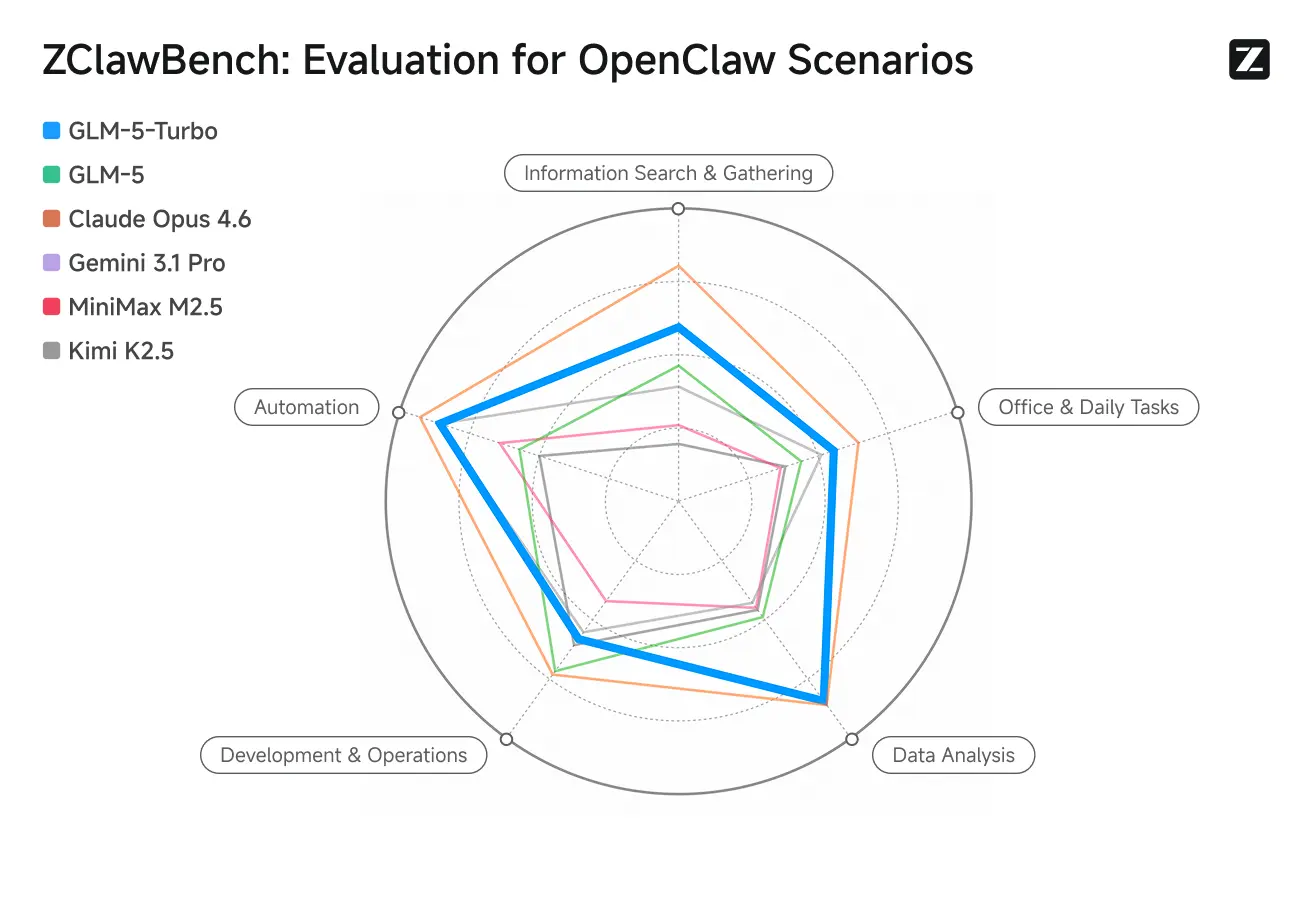
ZClawBench: Benchmark Test for OpenClaw Proxy Scenarios
Zhipu also released the ZClawBench benchmark for evaluating intelligent agents. In blind tests covering diverse fields such as code development, data analysis, and content creation, the new model codenamed Pony-Alpha-2 won the favor of 90% of respondents.
Pricing & availability (who sells it and how much)
Zhipu implemented a ~20% API price increase for the GLM-5-Turbo offering at release and simultaneously introduced “Lobster Package” subscription tiers intended to smooth token pricing for agent deployments.
Reported subscription tiers (example packages)
Two illustrative Lobster packages (prices are reported conversions and approximate):
- Entry Lobster plan: ~39 CNY / month (~US$5.66) for 35,000,000 tokens.
- Mid Lobster plan: ~99 CNY / month (~US$14.36) for 100,000,000 tokens.
Using those published numbers, the cost per 1 million tokens is approximately:
- Entry plan: ~US$0.162 per 1M tokens.
- Mid plan: ~US$0.144 per 1M tokens.
Those per-1M figures are simple conversions of the published subscription cost and token cap and illustrate the economics for high-volume agent workloads. (Calculations based on the press-reported currency and token quantities.)
API Price
Representative marketplace (CometAPI) listing: $0.96 per 1M input tokens and $3.20 per 1M output tokens for GLM-5-Turbo.
Zhipu’s own (Z.ai) developer pricing page lists a slightly higher direct rate for GLM-5-Turbo: $1.20 per 1M input tokens and $4.00 per 1M output tokens (cached input rates are lower).
GLM-5-Turbo vs GLM-5 — side-by-side comparison
At a high level:
- GLM-5 = flagship general-purpose foundation model (strong reasoning, coding, benchmarks)
- GLM-5-Turbo = agent-optimized variant of GLM-5 (focused on long workflows, tool use, stability)
GLM-5-Turbo is not a completely new model architecture, but a specialized, production-optimized version of GLM-5 designed for agent systems like OpenClaw.
Core positioning
| Model | Positioning |
|---|---|
| GLM-5 | General-purpose flagship LLM (reasoning, coding, benchmarks) |
| GLM-5-Turbo | Agent-first model (automation, orchestration, tool usage) |
👉 In simple terms:
- Use GLM-5 → when you want maximum intelligence
- Use GLM-5-Turbo → when you want stable automation / agents
Agent capability comparison (MOST IMPORTANT)
GLM-5 (agent capability), already supports:
- Tool use
- Multi-step reasoning
- Coding agents
But limitations:
- Can lose context in long chains
- Tool calls may degrade over time
- Requires more orchestration logic
GLM-5-Turbo is explicitly optimized for agents:
Key improvements:
- Tool calling reliability ↑
- Task decomposition (planning) ↑
- Long-chain consistency ↑
- Persistent execution support ↑
Example improvement:
- Stable execution across 10+ steps without losing context
👉 This is critical for:
- AutoGPT-style systems
- Multi-agent workflows
- SaaS automation
Speed & efficiency
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inference speed | Moderate | Faster |
| Throughput | Standard | Higher |
| Long-task latency | Can degrade | Optimized |
GLM-5-Turbo is designed to fix a real industry problem:
Large models slow down or break during long workflows
Pricing comparison
| Model | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo is more expensive (~20% higher)
Why more expensive?
Because it provides:
- Better orchestration reliability
- Higher production stability
- Agent-specific optimizations
👉 In enterprise:
- You pay more per token
- But reduce failure cost + retries
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primary goal | General flagship foundation model (broad capabilities, strong coding/benchmarks) | Agent/“OpenClaw” / lobster-optimized foundation model |
| Context window | (reported high; GLM-5 focuses ~200K (GLM-5 also supports long context) | 200,000 tokens (explicitly documented). |
| Maximum output tokens | (large, model dependent) | 128,000 tokens (documented). |
| Notable benchmark scores | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (GLM-5 reported numbers). | Internal evaluations claim improved long-chain stability and throughput for agent workflows; independent public benchmarks pending. |
| Modalities | Text (primary), GLM family has vision variants in sibling models | Text only (per docs) — optimized for tool-based agents. |
| Recommended use cases | Broad: chat, code, reasoning, content | Agent orchestration, tool invocation, long-horizon automation |
| Pricing | Existing GLM-5 pricing (varied by plan) | New launch — reported ~20% API price increase; new Lobster subscription tiers introduced |
How to use GLM-5-Turbo
CometAPI — single API access to many models (OpenAI-compatible)
CometAPI lists GLM-5-Turbo as available and provides an OpenAI-compatible base URL and SDK. Use the model string they publish (their site lists GLM-5-Turbo at similar pricing). Examples adapted from CometAPI docs:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
CometAPI’s value is aggregator convenience (single integration for many models). Confirm the exact model slug in the CometAPI dashboard before calling.
Best practices when building Lobster / OpenClaw agents with GLM-5-Turbo
- Design for reliability, not raw latency: Turbo’s advantage is lower tool-call failure in long chains. Structure agent runs to prefer robust completions (retries, idempotent tool calls) over tiny first-token gains.
- Use streaming & incremental tool calls: Embrace streaming/chunked outputs to reduce rework and allow early tool invocation where appropriate. GLM-5-Turbo supports streaming.
- Structured outputs for parsers: Prefer JSON or well-formatted results for deterministic downstream tool parsing. Turbo supports structured outputs.
- Plan for scheduling / persistence: If your agent must periodically check or run background tasks, use Turbo’s better time semantics and caching features to avoid re-planning every cycle.
- Instrument tool calls & fallbacks: Log tool calls and design graceful fallbacks (e.g., re-try with slight temperature or call a backup tool) since agentic workflows are brittle if a single external API fails. Turbo reduces error rates but does not eliminate external failures
Developers can access GLM-5 and GLM-5 turbo APIvia CometAPI now.To begin, consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Sign up fo GLM-5 and GLM-5 turbo today !