
.png&w=3840&q=75)
GPT-5.4 Mini and GPT-5.4 Nano are OpenAI’s new compact variants of its GPT-5.4 frontier family: Mini targets a best-in-class performance/latency tradeoff for coding, multimodal UI tasks, and subagent workloads; Nano targets ultra-low cost and latency for classification, extraction, ranking and massively parallel subagents. Mini offers near-frontier accuracy on many developer benchmarks while running >2× faster than previous minis; Nano is significantly cheaper per token and ideal where throughput and responsiveness matter most. These models are live in the API (GPT 5.4 Mini and Nano are available in CometAPI).
What are GPT-5.4 Mini and GPT-5.4 Nano?
Short definition: GPT-5.4 Mini and GPT-5.4 Nano are compact, engineered variants of the GPT-5.4 family designed to bring the core strengths of the large GPT-5.4 (reasoning, coding, multimodal perception, tool use) into faster, lower-cost models targeted at high-volume, low-latency workloads. The models were announced by OpenAI as part of the GPT-5.4 rollout.
- GPT-5.4 Mini — A performant small model that "approaches the performance of GPT-5.4 on several evaluations" while being optimized for speed and lower cost. It is specifically highlighted for coding, reasoning, multimodal UI interpretation (screenshots), and as a subagent in agentic systems. OpenAI reports it runs more than 2× faster than previous "mini" variants.
- GPT-5.4 Nano — The smallest, cheapest GPT-5.4 variant; recommended for classification, extraction, ranking and “supporting” subagents that handle narrow, repetitive tasks at very high throughput. It trades off deeper reasoning for latency and cost savings.
Availability and Price
OpenAI provides two concrete datapoints you can use to compare cost:
- GPT-5.4 (full flagship) API input price: $2.50 / 1M tokens (and higher output pricing on flagship).
- GPT-5.4 mini API input price: $0.75 / 1M tokens and output $4.50 / 1M tokens.
- GPT-5.4 nano API input price: $0.20 / 1M and output $1.25 / 1M.
Putting that side-by-side: mini’s input token price (0.75) is 30% of the flagship’s (2.50), so roughly one-third the input cost; mini’s output price (4.50) is about 32% of a flagship output price quoted in the API price table, i.e., about one-third as well. Nano is even cheaper: its input cost is about 8% of flagship input cost, and its output cost is under 10% of flagship output cost. These proportions are exactly why OpenAI frames mini/nano as “about one-third” (mini) and “a fraction of” (nano) the cost of using the largest models for high-volume tasks. The price of the nano token rose from $0.05 to $0.20, and the price of the mini token rose from $0.25 to $0.75 (for input tokens).
In OpenAI platform
GPT-5.4 mini is available in three places: the OpenAI API, Codex (OpenAI’s developer IDE/app platform), and ChatGPT (available to Free and Go users through the “Thinking” option and as a rate-limit fallback for paid tiers). In the API it supports text and image inputs, tool use (function calling), web/file search, computer use, and skills — and it offers a very large context window (400k tokens) to serve document-heavy and multi-screenshot workflows. Pricing for the API is $0.75 per 1M input tokens and $4.50 per 1M output tokens.
GPT-5.4 nano is only available through the API. Its list prices are $0.20 per 1M input tokens and $1.25 per 1M output tokens — positioning it as the lowest-cost entry in the GPT-5.4 family. The nano model deliberately trades capability for cost and speed.
In third platform
CometAPI is an AI API multimodal aggregation platform that has now launched the GPT 5.4 Series API, including GPT 5.4 Mini and GPT 5.4 Nano, at 20% off the OpenAI price.
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Key features and What is New
Below are the headline capabilities — why engineers and product teams will care.
Encoding & Long-context support
Context window: GPT-5.4 mini supports a 400k token context window (OpenAI explicitly lists mini with a 400k context). This is large enough for multi-file codebases, extended documents, or multi-turn agent sessions where context matters. Nano’s context is smaller relative to the full GPT-5.4 but still substantial for fast short tasks.
Reasoning
Reasoning levels: OpenAI exposes configurable reasoning_effort (none → xhigh); mini and nano can run with varied effort but mini closes the gap to the full GPT-5.4 on many reasoning benchmarks at higher effort. On several intelligence benchmarks (e.g., GPQA Diamond), mini achieves an 88.0% score versus 93.0% for GPT-5.4, and nano posts 82.8%, indicating respectable reasoning for a small model. These are the results OpenAI published in their launch post.
Multimodal understanding (vision & UI)
Visual perception & UI tasks: GPT-5.4 mini shows very strong multimodal performance for UI tasks (screenshots, dense document images). On OSWorld-Verified (a computer-use benchmark), mini scores 72.1%, much closer to GPT-5.4’s 75.0% and far above prior minis — this is why mini is positioned for screenshot-driven automations and responsive multimodal assistants. Nano performs lower on visual benchmarks but still useful for simpler image tasks.
Tool invocation & computer use
Native tool/click capabilities: GPT-5.4 introduces and extends native computer-use tooling; mini inherits the ability to call tools, make function calls, interpret screenshots and orchestrate subagents. Tool-call benchmarks (Toolathlon, MCP Atlas) show mini and nano scoring respectably (Toolathlon: mini 42.9%, nano 35.5%) — this quantifies their ability to call and coordinate external tools. These metrics are from OpenAI’s announcement.
Hallucination / factuality / error rates
OpenAI reports GPT-5.4 is the “most factual model yet” and shows reductions in hallucination vs GPT-5.2; mini and nano show lower absolute factuality than the full model (e.g., HLE w/ tools: GPT-5.4 52.1%, mini 41.5%, nano 37.7%) which suggests an increased need for verification when smaller models are used in high-fact tasks. Use tool-based verification (tool calls, citation recall) when correctness matters.
Speed
OpenAI reports that GPT-5.4 mini runs more than 2× faster than the prior GPT-5 mini on typical production-style latency estimates (these are based on simulated production behavior that includes tool call durations and sampled tokens). This speedup is a central claim for the new family and is what allows mini to be used as a responsive subagent inside interactive apps such as coding assistants.
How do mini and nano perform — do they “approach” full GPT-5.4?
OpenAI published a comprehensive set of benchmark comparisons across coding, tool use, multimodal computer-use tasks, intelligence tests, and long-context evaluations. The headline numbers (xhigh reasoning effort where applicable) include:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | Notes |
|---|---|---|---|---|---|
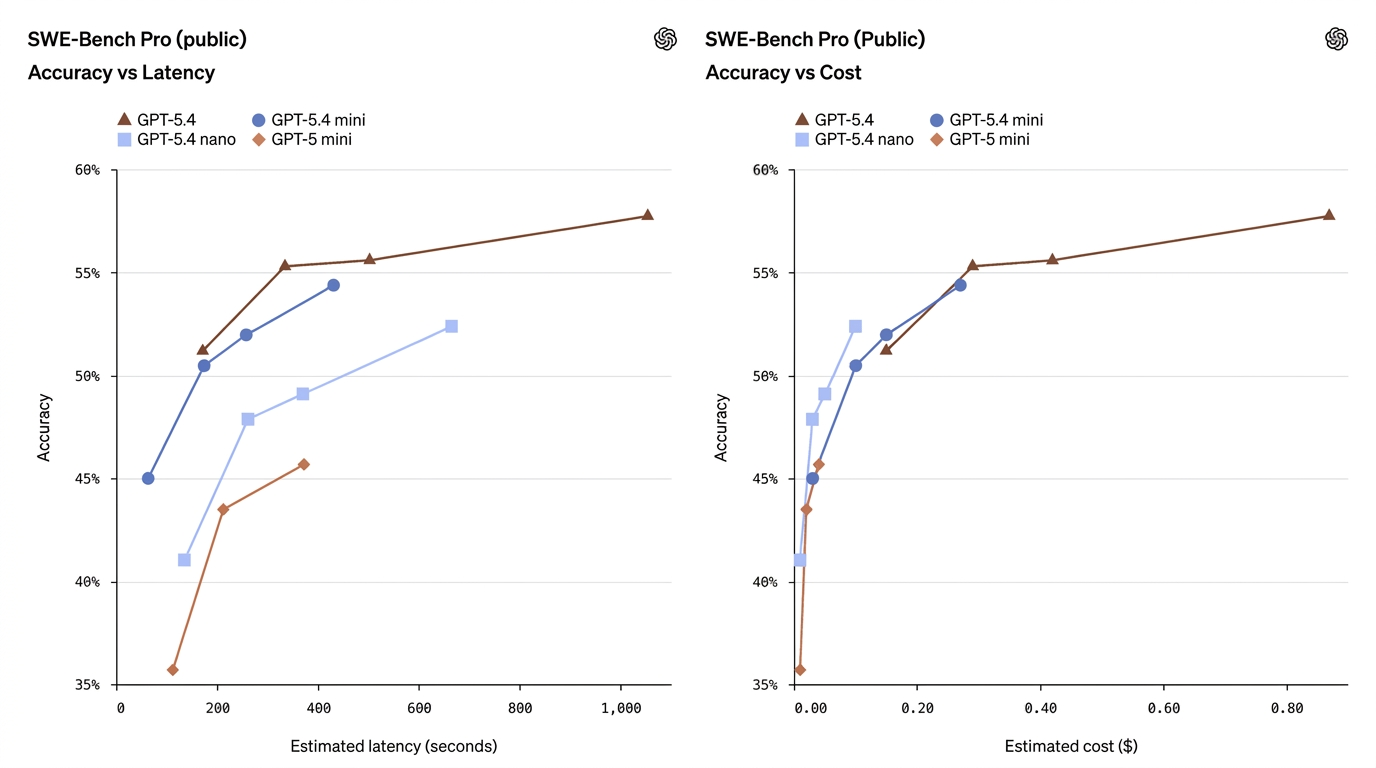
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini approaches full model coding performance |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Strong real-time coding ability for Mini |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | Measures orchestration & tool-calling |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | Intelligence & reasoning benchmark |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | UI/computer-use capability |
These numbers show mini often narrows the gap considerably — especially on coding and computer-use tasks — while nano occupies a useful middle ground between capability and cost.
What do the numbers mean in plain English?
- GPT-5.4 Mini ≈ “nearly flagship” on many production tasks. On SWE-Bench Pro (a coding pass-rate metric), mini scores 54.4% vs flagship’s 57.7% — a small relative gap for many real-world coding tasks, particularly when latency matters. On OSWorld (computer use), mini is 72.1% against flagship’s 75.0% — again, very close for UI/screenshot tasks.
- GPT-5.4 Nano trades more capability for speed/cost. Nano’s coding score (52.4% on SWE-Bench Pro) is respectable relative to older minis, but its OSWorld score drops to 39.0%, showing that for tasks requiring complex multi-step UI understanding or agentic tool sequences, nano is less suitable. Nano shines at single-turn classification, extraction, and small helper tasks.
- Tool use improves, but remains sensitive. Toolathlon and other tool-use metrics rise substantially when switching from GPT-5 mini to GPT-5.4 mini/nano, showing that OpenAI’s engineering improved tool invocation reliability in the smaller footprint models — but the full model still leads in complex tool orchestration.
How they work in production
Compression, distillation and engineering optimizations
Compact models like mini/nano typically use a combination of model distillation, quantization, and architectural pruning to preserve high-value capabilities (coding heuristics, visual percepts) while reducing inference compute. OpenAI’s wording indicates focused engineering to preserve specific skillsets (coding, multimodal UI understanding) in the smaller footprints.
Recommended patterns
- Orchestrator + subagent pattern: Use GPT-5.4 (large) as the planner/judge and dispatch work to GPT-5.4 mini / nano subagents for quick execution (search, parse, edit). This reduces total cost and lowers latency for the user. OpenAI explicitly endorses this design pattern.
- Fallback & rate-limit handling: Expose mini as a rate-limit fallback in ChatGPT or Codex so time-sensitive queries still receive a capable answer when the full model is unavailable.
- Tiered architecture for cost control: Bulk pipelines (indexing, extraction) → GPT-5.4 nano; interactive UI components → GPT-5.4 mini; final editorial judgement / complex chains → GPT-5.4 full. This multi-tier approach balances cost and capability.
Latency and parallelization
Mini and nano are optimized for parallel subagents, where many small workers run concurrently — e.g., scanning thousands of PDFs in parallel. OpenAI’s “tool yields” concept measures how parallel tool calls reduce wall-clock latency; mini/nano are engineered to make those patterns cost-effective.
How would I use mini and nano in practice
Should I replace my flagship calls with mini/nano everywhere?
Not automatically. The right pattern OpenAI explicitly recommends is delegation: use a larger model for planning, complex judgment, or final verification, and dispatch many supporting, shorter subtasks to mini or nano subagents. This pattern reduces cost and latency while retaining the larger model’s guardrails where they matter most. Use cases:
- Interactive coding assistants: flagship plans & reviews; mini handles quick code search, edits, and short unit tests.
- Screenshot-driven “computer use” agents: mini can parse dense interfaces quickly; flagship resolves ambiguous multi-step planning.
- High-volume extraction & classification pipelines: nano processes massive batched inputs (forms, logs) and returns structured results; flagship handles exceptions and complex edge cases.
Can mini or nano be used for multimodal or image tasks?
Yes — mini supports image inputs and performs well on multimodal/vision-driven benchmarks (MMMUPro/OmniDocBench), approaching the flagship on some tests. Nano’s multimodal strength is more limited: while it improves on prior nanos, it is not the best choice for deep multimodal reasoning or agentic image-based tasks.
The race for small modeling capabilities has intensified
Three months ago, small models were considered "good enough." Now, the GPT-5.4 mini is approaching flagship models on programming benchmarks and nearly matching them in computational performance.
The trend behind this is clear: the capabilities of flagship models are rapidly being transferred to smaller models. OpenAI, Google, and Anthropic are all doing the same thing: distilling the core capabilities of large models into smaller, faster, and cheaper versions.
Conclusion
The release of these two models signifies a shift in AI applications from a focus on scale to a focus on practical efficiency. Through rapid response capabilities, they provide more reliable underlying support for real-time AI interaction and the breakdown of complex task flows.
For developers, this means the cost structure of agent systems is being redefined. When costs drop to this level, many agent scenarios that were previously "theoretically feasible but economically unfeasible" become viable.
Developers can access GPT 5.4 Mini and GPT-5.4 Nano via CometAPI(CometAPI is a one-stop aggregation platform for large model APIs such as GPT APIs, Nano Banana APIs etc) now.Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?