

GLM-5-Turbo adalah LLM foundation baru dari Zhipu AI yang secara khusus dilatih dan disetel untuk alur kerja bergaya agen (perusahaan menyebut ekosistem targetnya sebagai skenario OpenClaw / “lobster”). Model ini menawarkan konteks yang sangat panjang (hingga ~200K token), streaming dan output terstruktur, tingkat error pemanggilan alat yang lebih rendah (dilaporkan ~0.67% dalam pengujian pihak ketiga), serta harga per token yang secara signifikan lebih rendah. Model ini bertujuan menukar sedikit throughput puncak untuk satu giliran dengan stabilitas yang jauh lebih baik, keandalan alat, penanganan tugas terjadwal/persisten, dan eksekusi rantai panjang—berguna untuk agen otonom, sistem orkestrasi, dan pipeline multi-alat.
Apa itu GLM-5-Turbo?
GLM-5-Turbo diperkenalkan oleh Zhipu sebagai model foundation yang dirancang khusus untuk orkestrasi agen dan alur kerja otomatis yang kompleks alih-alih sebagai model chat umum atau multimodal. Pilihan desainnya menekankan:
- Pelatihan yang secara native ramah agen (penggunaan alat, mengikuti perintah, tugas terjadwal/persisten).
- Jendela konteks yang sangat besar dan kapasitas output tinggi untuk mendukung sesi panjang, memori, dan perencanaan chain-of-thought.
- Inferensi yang stabil dan throughput tinggi untuk alur bisnis yang panjang dan tugas terjadwal.
Berbeda dengan LLM tradisional yang dioptimalkan untuk chat atau pembuatan teks, GLM-5-Turbo adalah:
- Agent-first (bukan chat-first)
- Dibangun untuk lingkungan OpenClaw (“lobster”)
- Dirancang untuk alur kerja otonom multi-langkah
🦞 Apa arti “Lobster Agent”?
Konsep “lobster” merujuk pada OpenClaw, ekosistem agen AI milik Zhipu tempat model:
- Menggunakan alat secara dinamis
- Menjalankan rantai tugas yang panjang
- Mempertahankan memori persisten
- Beroperasi di terminal, aplikasi, dan API
GLM-5-Turbo sangat dioptimalkan untuk paradigma ini, menyelesaikan masalah utama agen seperti:
- Keandalan pemanggilan alat
- Dekomposisi tugas
- Perencanaan jangka panjang
- Stabilitas eksekusi
Fitur utama dan mengapa itu penting
Konteks panjang + kapasitas output besar (200K / 128K)
Jendela konteks 200K token dan kemampuan output 128K memungkinkan GLM-5-Turbo untuk:
- Menyimpan memori yang diperluas dari konteks sebelumnya (percakapan, output alat, hasil perantara).
- Menghasilkan artefak yang sangat panjang (rencana multi-tahap, laporan panjang, codebase) tanpa perlu penyambungan konteks berulang.
- Menjalankan agen multi-giliran yang harus mempertahankan seluruh riwayat eksekusi untuk pengambilan keputusan yang akurat.
Ini adalah pilihan teknis yang disengaja untuk agen — alih-alih membagi tugas menjadi prompt pendek, agen dapat mempertahankan state yang koheren di ribuan giliran percakapan atau langkah.
Primitive agen yang tertanam dalam pelatihan
Alih-alih menyesuaikan model serbaguna untuk tugas agen, GLM-5-Turbo dilatih dengan objektif bergaya agen (misalnya, perilaku pemanggilan alat, parsing perintah/argumen). Efek yang diklaim adalah lebih sedikit halusinasi saat pemanggilan alat, rencana multi-langkah yang lebih stabil, dan latensi yang lebih baik dalam eksekusi panjang — semuanya bernilai ketika otomasi harus merangkai banyak API atau alat eksternal secara andal.
Throughput dan stabilitas eksekusi
Varian GLM-5-Turbo meningkatkan stabilitas eksekusi dan throughput untuk alur bisnis yang panjang dibandingkan model besar yang bersifat umum — bahasa pemasarannya menekankan "eksekusi throughput tinggi" dan "stabilitas respons terdepan" di antara model serupa. Ini penting untuk deployment agen enterprise, ketika satu langkah yang gagal dapat merusak seluruh pipeline. Benchmark independen pihak ketiga masih terus bermunculan.
Data benchmark GLM-5-Turbo
Catatan: Zhipu telah menerbitkan evaluasi internal, dan benchmark pihak ketiga/akademik untuk GLM-5 juga tersedia. GLM-5-Turbo baru saja dirilis; hasil benchmark independen dari komunitas akan memerlukan waktu untuk muncul. Di bawah ini kami mencantumkan angka dan konteks yang paling dapat dipertanggungjawabkan dan telah dipublikasikan.
GLM-5 (referensi) — metrik representatif yang dipublikasikan
GLM-5 milik Zhipu (pendahulu flagship dari Turbo) melaporkan leaderboard yang kuat pada banyak tugas engineering/alur kerja — misalnya:
- SWE-bench Verified: 77.8 (dilaporkan dalam dokumentasi GLM-5 sebagai skor open-model terdepan).
- Terminal Bench 2.0: 56.2 (dilaporkan sebagai performa open-model terbaik pada distribusi tersebut).
Angka-angka tersebut menetapkan GLM-5 sebagai baseline tinggi dalam tugas software engineering dan eksekusi; GLM-5-Turbo diposisikan untuk menukar sebagian penekanan pada ukuran mentah/parameter demi keandalan agen dan throughput yang lebih baik. GLM-5-Turbo menunjukkan ~0.67% error pemanggilan alat dalam perbandingan mereka, jauh lebih rendah daripada run provider pembanding GLM-5 yang berkisar antara ~2.33% hingga 6.41%.
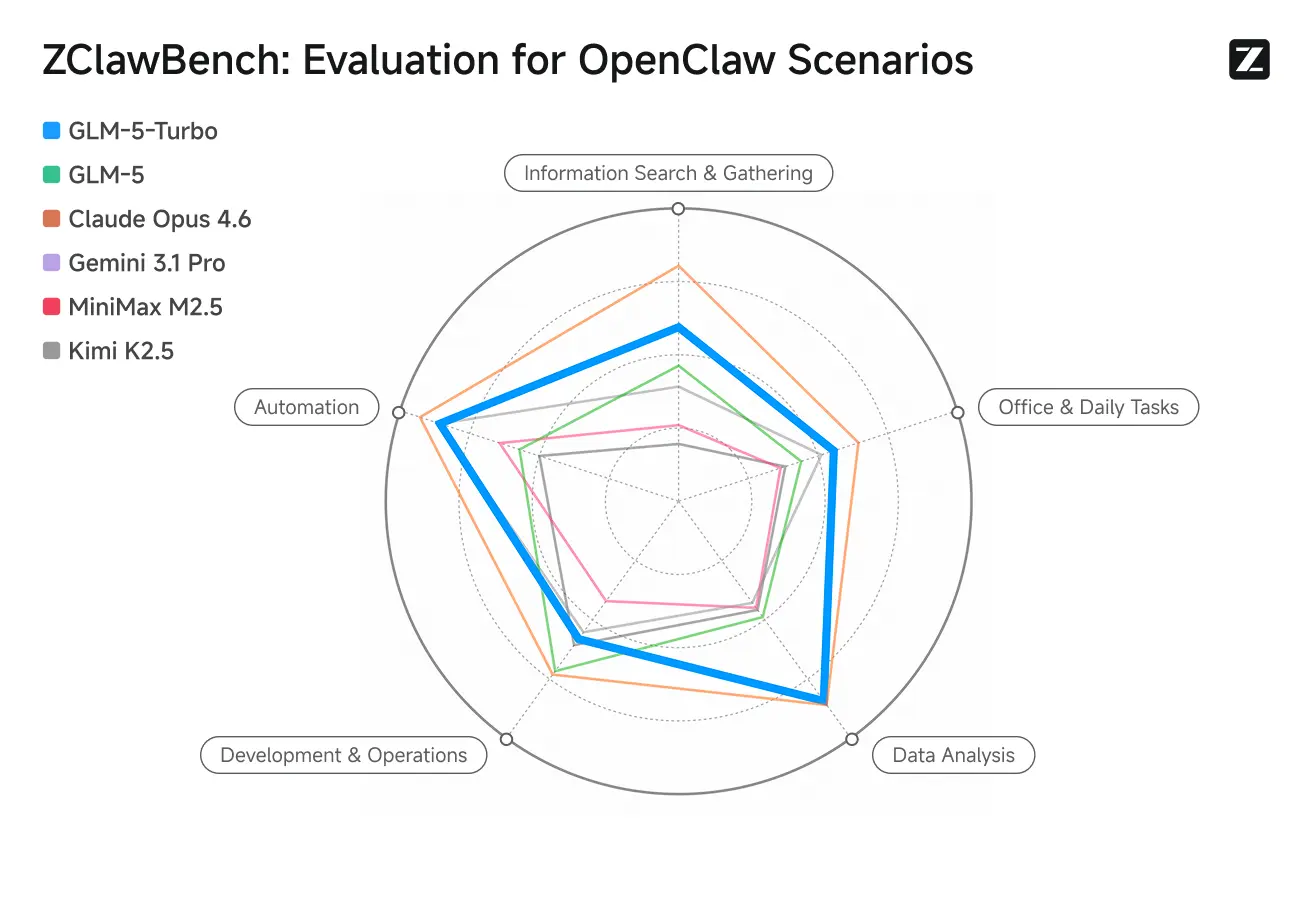
ZClawBench: Uji Benchmark untuk Skenario Proxy OpenClaw
Zhipu juga merilis benchmark ZClawBench untuk mengevaluasi agen cerdas. Dalam blind test yang mencakup berbagai bidang seperti pengembangan kode, analisis data, dan pembuatan konten, model baru dengan nama kode Pony-Alpha-2 memenangkan preferensi 90% responden.
Harga & ketersediaan (siapa yang menjualnya dan berapa harganya)
Zhipu menerapkan kenaikan harga API ~20% untuk penawaran GLM-5-Turbo saat peluncuran dan sekaligus memperkenalkan tier langganan “Lobster Package” yang ditujukan untuk menstabilkan harga token bagi deployment agen.
Tier langganan yang dilaporkan (contoh paket)
Dua paket Lobster ilustratif (harga adalah konversi yang dilaporkan dan perkiraan):
- Paket Entry Lobster: ~39 CNY / bulan (~US$5.66) untuk 35,000,000 token.
- Paket Mid Lobster: ~99 CNY / bulan (~US$14.36) untuk 100,000,000 token.
Dengan menggunakan angka-angka yang dipublikasikan tersebut, biaya per 1 juta token kira-kira adalah:
- Paket Entry: ~US$0.162 per 1M token.
- Paket Mid: ~US$0.144 per 1M token.
Angka per-1M tersebut adalah konversi sederhana dari biaya langganan dan batas token yang dipublikasikan serta menggambarkan ekonomi untuk beban kerja agen bervolume tinggi. (Perhitungan berdasarkan mata uang dan jumlah token yang diberitakan pers.)
Harga API
Listing marketplace representatif (CometAPI): $0.96 per 1M token input dan $3.20 per 1M token output untuk GLM-5-Turbo.
Halaman harga developer milik Zhipu sendiri (Z.ai) mencantumkan tarif langsung yang sedikit lebih tinggi untuk GLM-5-Turbo: $1.20 per 1M token input dan $4.00 per 1M token output (tarif input cache lebih rendah).
GLM-5-Turbo vs GLM-5 — perbandingan berdampingan
Pada tingkat tinggi:
- GLM-5 = flagship model foundation serbaguna (reasoning, coding, benchmark yang kuat)
- GLM-5-Turbo = varian yang dioptimalkan untuk agen dari GLM-5 (berfokus pada alur kerja panjang, penggunaan alat, stabilitas)
GLM-5-Turbo bukan arsitektur model yang sepenuhnya baru, melainkan versi GLM-5 yang terspesialisasi dan dioptimalkan untuk produksi yang dirancang untuk sistem agen seperti OpenClaw.
Posisi inti
| Model | Posisi |
|---|---|
| GLM-5 | LLM flagship serbaguna (reasoning, coding, benchmark) |
| GLM-5-Turbo | Model agent-first (otomasi, orkestrasi, penggunaan alat) |
👉 Secara sederhana:
- Gunakan GLM-5 → saat Anda menginginkan kecerdasan maksimum
- Gunakan GLM-5-Turbo → saat Anda menginginkan otomasi / agen yang stabil
Perbandingan kemampuan agen (PALING PENTING)
GLM-5 (kemampuan agen), sudah mendukung:
- Penggunaan alat
- Reasoning multi-langkah
- Agen coding
Namun keterbatasannya:
- Dapat kehilangan konteks dalam rantai panjang
- Pemanggilan alat dapat menurun kualitasnya seiring waktu
- Membutuhkan lebih banyak logika orkestrasi
GLM-5-Turbo secara eksplisit dioptimalkan untuk agen:
Peningkatan utama:
- Keandalan pemanggilan alat ↑
- Dekomposisi tugas (perencanaan) ↑
- Konsistensi rantai panjang ↑
- Dukungan eksekusi persisten ↑
Contoh peningkatan:
- Eksekusi stabil di 10+ langkah tanpa kehilangan konteks
👉 Ini sangat penting untuk:
- Sistem bergaya AutoGPT
- Alur kerja multi-agen
- Otomasi SaaS
Kecepatan & efisiensi
| Aspek | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Kecepatan inferensi | Sedang | Lebih cepat |
| Throughput | Standar | Lebih tinggi |
| Latensi tugas panjang | Dapat menurun | Dioptimalkan |
GLM-5-Turbo dirancang untuk memperbaiki masalah nyata di industri:
Model besar melambat atau rusak selama alur kerja yang panjang
Perbandingan harga
| Model | Input ($/1M token) | Output ($/1M token) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo lebih mahal (~20% lebih tinggi)
Mengapa lebih mahal?
Karena model ini memberikan:
- Keandalan orkestrasi yang lebih baik
- Stabilitas produksi yang lebih tinggi
- Optimasi khusus agen
👉 Di enterprise:
- Anda membayar lebih mahal per token
- Tetapi mengurangi biaya kegagalan + retry
| Atribut | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Tujuan utama | Model foundation flagship umum (kapabilitas luas, coding/benchmark kuat) | Model foundation yang dioptimalkan untuk agen/“OpenClaw” / lobster |
| Jendela konteks | (dilaporkan tinggi; GLM-5 berfokus pada ~200K (GLM-5 juga mendukung konteks panjang) | 200,000 token (didokumentasikan secara eksplisit). |
| Token output maksimum | (besar, tergantung model) | 128,000 token (didokumentasikan). |
| Skor benchmark menonjol | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (angka yang dilaporkan untuk GLM-5). | Evaluasi internal mengklaim peningkatan stabilitas rantai panjang dan throughput untuk alur kerja agen; benchmark publik independen masih menunggu. |
| Modalitas | Teks (utama), keluarga GLM memiliki varian vision di model saudara | Hanya teks (sesuai dokumen) — dioptimalkan untuk agen berbasis alat. |
| Use case yang direkomendasikan | Luas: chat, kode, reasoning, konten | Orkestrasi agen, pemanggilan alat, otomasi jangka panjang |
| Harga | Harga GLM-5 yang ada (bervariasi menurut paket) | Peluncuran baru — dilaporkan ada kenaikan harga API ~20%; tier langganan Lobster baru diperkenalkan |
Cara menggunakan GLM-5-Turbo
CometAPI — akses satu API ke banyak model (kompatibel OpenAI)
CometAPI mencantumkan GLM-5-Turbo sebagai tersedia dan menyediakan base URL serta SDK yang kompatibel dengan OpenAI. Gunakan string model yang mereka publikasikan (situs mereka mencantumkan GLM-5-Turbo dengan harga serupa). Contoh yang diadaptasi dari dokumentasi CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
Nilai utama CometAPI adalah kenyamanan sebagai agregator (satu integrasi untuk banyak model). Pastikan slug model yang tepat di dashboard CometAPI sebelum melakukan pemanggilan.
Praktik terbaik saat membangun agen Lobster / OpenClaw dengan GLM-5-Turbo
- Rancang untuk keandalan, bukan latensi mentah: Keunggulan Turbo adalah kegagalan pemanggilan alat yang lebih rendah dalam rantai panjang. Strukturkan eksekusi agen agar lebih memilih penyelesaian yang kuat (retry, pemanggilan alat idempoten) daripada keuntungan kecil pada token pertama.
- Gunakan streaming & pemanggilan alat inkremental: Manfaatkan output streaming/bertahap untuk mengurangi pekerjaan ulang dan memungkinkan pemanggilan alat lebih awal bila sesuai. GLM-5-Turbo mendukung streaming.
- Output terstruktur untuk parser: Pilih JSON atau hasil yang terformat rapi untuk parsing alat downstream yang deterministik. Turbo mendukung output terstruktur.
- Rencanakan penjadwalan / persistensi: Jika agen Anda harus memeriksa secara berkala atau menjalankan tugas latar belakang, gunakan semantik waktu dan fitur cache Turbo yang lebih baik untuk menghindari perencanaan ulang di setiap siklus.
- Instrumentasi pemanggilan alat & fallback: Catat pemanggilan alat dan rancang fallback yang anggun (misalnya, coba lagi dengan temperature sedikit berbeda atau panggil alat cadangan) karena alur kerja agentic rapuh jika satu API eksternal gagal. Turbo mengurangi tingkat error tetapi tidak menghilangkan kegagalan eksternal
Developer kini dapat mengakses API GLM-5 dan GLM-5 turbo melalui CometAPI sekarang. Untuk memulai, lihat panduan API untuk instruksi terperinci. Sebelum mengakses, pastikan Anda sudah login ke CometAPI dan mendapatkan API key. CometAPI menawarkan harga yang jauh lebih rendah daripada harga resmi untuk membantu integrasi Anda.
Siap mulai?→ Daftar untuk GLM-5 dan GLM-5 turbo hari ini !