

Den 3. mars 2026 lanserte Google Gemini 3.1 Flash-Lite, det nyeste medlemmet i Gemini 3-familien, designet spesifikt som en høy-gjennomstrømming, lav-latens, kostnadseffektiv motor for utvikler- og bedriftsarbeidslaster. Google posisjonerer Flash-Lite som den “raskeste og mest kostnadseffektive” modellen i Gemini 3-serien: en lettvektsvariant som sikter på å levere strømmende interaksjoner, storskala bakgrunnsprosessering og høyfrekvente produksjonsoppgaver (for eksempel oversettelse, utpakking, UI-generering og klassifisering i stort volum) til en langt lavere pris enn Pro-motstykkene.
Nedenfor forklarer vi hva Flash-Lite er.
Hva er Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite er et medlem av Googles Gemini 3-familie som bevisst bytter bort noe av den mest avanserte resonneringsdybden mot fart og kostnadseffektivitet. Den er naturlig multimodal i Gemini-linjen (kan ta imot tekst, bilder og andre modaliteter som input), men er tunet og distribuert spesifikt for å levere maksimal tokens-per-sekund-gjennomstrømming og vesentlig lavere prising per token for arbeidslaster som krever rask, gjentatt inferens snarere enn maksimal kognitiv dybde. Modellen beskrives som avledet fra 3.1 Pro-arkitekturen, men optimalisert for gjennomstrømming, latens og kostnad.
Viktige designavveininger
“Lite”-betegnelsen signaliserer modellens ingeniørmessige vektlegging:
- Gjennomstrømming fremfor tung resonnering: Flash-Lite reduserer bevisst beregning per token for å levere raskere tid til første token (TTFT) og kontinuerlig utdatahastighet. Det gjør den ideell for rørledninger der hver forespørsel må betjenes raskt og i skala (f.eks. sikkerhetsfiltre, sanntidsassistenter, høyt volum av generering).
- Kostnadseffektivitet for høye volumer: Ved å senke beregning per token kan modellen tilbys til lavere pris per million tokens, noe som reduserer marginalkostnaden i storskala applikasjoner (f.eks. millioner til milliarder av tokens per måned). Googles forhåndsvisningspriser viser et betydelig gap mot Pro-nivået.
- Kvalitet innstilt for pragmatiske oppgaver: Ifølge tidlige oppsummeringer opprettholder Flash-Lite sterke resultater på standard klassifisering, flerspråklige og mange multimodale oppgaver, men den er ikke posisjonert for å slå Pro på de mest komplekse flertrinns resonnerings- eller kodegenereringsbenchmarks der dybde betyr mest.
Disse arbeidslastene krever pålitelig output og høy gjennomstrømming, men de krever ikke alltid de komplekse flertrinns resonneringsmulighetene til flaggskipsmodeller.
Nøkkelfunksjoner i Gemini 3.1 Flash-Lite
1. Lav latenstid og rask tid til første token
Google fremhever tid-til-første-svartoken som en primær metrikk for Flash-Lite. Selskapet rapporterer ~2.5× raskere tid til første token sammenlignet med Gemini 2.5 Flash og opptil 45% raskere utdatagenerering — forbedringer som direkte påvirker opplevd respons for sluttbrukere og gjennomstrømmingskostnader for back-end-systemer. Disse gevinstene gjør Flash-Lite godt egnet til interaktive funksjoner (f.eks. chatboter innebygd i apper) og høy-QPS-rørledninger der mikrosekunder betyr noe.
Denne forbedringen styrker sanntidsapplikasjoner betydelig, som:
- konversasjons-AI
- AI-drevne søkeassistenter
- interaktive chatboter
- sanntids oversettelsestjenester
Lavere latens forbedrer brukeropplevelsen ved å redusere ventetid og muliggjøre mer flytende interaksjoner.
2. Kostnadseffektiv prising per token
Kostnader for AI-inferens beregnes ofte per token, noe som gjør prising til en kritisk faktor for distribusjoner i stor skala.
Gemini 3.1 Flash-Lite introduserer en svært konkurransedyktig prisstruktur:
| Tokentype | Pris |
|---|---|
| Inndata-tokens | $0.25 per 1M tokens |
| Utdata-tokens | $1.50 per 1M tokens |
Dette representerer en reduksjon sammenlignet med tidligere Flash-modeller, noe som gjør modellen attraktiv for organisasjoner som kjører store arbeidslaster.
Til sammenligning:
| Modell | Inndatapris | Utdatapris |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Denne prisstrategien lar utviklere kjøre AI i skala uten å øke driftskostnadene dramatisk.
Hvis du ser etter en enda bedre pris, tilbyr da Gemini Flash-Lite 20% rabatt på CometAPI.
3. “Tenkenivåer” (kontrollerbar inferensdybde)
Gemini 3.1 Flash-Lite inkluderer funksjonen “tenkenivåer” — en utviklerkonfigurerbar bryter som instruerer modellen til å foretrekke raskere, grunnere prosessering for trivielle oppgaver og dypere resonnering for vanskeligere oppgaver. Dette er viktig i praksis fordi det gjør det mulig å gjøre dynamiske kostnads-/latensavveininger per forespørsel uten å bytte modeller.
Utviklere kan konfigurere modellens resonneringsdybde til å matche oppgavens kompleksitet. Tenkenivåer: Støtter fire nivåer: Minimal, Lav, Middels og Høy.
Denne dynamiske tilnærmingen lar applikasjoner optimalisere ressursbruk samtidig som kvaliteten opprettholdes der det betyr noe. Den praktiske strategien er omtrent som følger:
- Minimal/Lav: Egnet for høy samtidig belastning, men logisk enkle oppgaver som oversettelse, klassifisering og sentimentanalyse, med maksimal hastighet og minimale kostnader som prioritet.
- Middels: Egnet for de fleste produksjonsoppgaver, med en balanse mellom kvalitet og effektivitet.
- Høy: Egnet for oppgaver som krever dyp resonnering, som generering av brukergrensesnitt, oppretting av simuleringer og utførelse av komplekse instruksjoner.
4. Multimodal kapasitet med lettvektsfotavtrykk
Selv om Flash-Lite er optimalisert for hastighet og kostnad, beholder den Gemini 3-linjens multimodale fundament: den kan ta imot bildeforsyninger for klassifisering eller lett multimodal resonnering når bruken krever det — men utviklere bør forvente at den økonomiske designen favoriserer kortere, avgrensede multimodale operasjoner fremfor svært store, bilde-tunge arbeidsflyter. Som andre Gemini-modeller støtter Gemini 3.1 Flash-Lite multimodale input, slik at utviklere kan prosessere forskjellige typer data.
Støttede input inkluderer:
- Tekst
- Bilder
- Video
- Lyd
- PDF-er
Modellens evne til å analysere flere typer informasjon muliggjør nye bruksområder, som:
- automatisert dokumentbehandling
- visuell datauttrekking
- multimediabasert oppsummering
Tidligere Gemini-modeller demonstrerte også sterke multimodale resonneringsevner på tvers av visuelle og kunnskapsmessige benchmarks.
Ytelsesbenchmarker — reelle tall og hva de betyr
Googles annonsering og produktdokumentasjon presenterer flere benchmark-tall ment å hjelpe kjøpere å forstå hvor Flash-Lite plasserer seg i økosystemet.
Utviklerorienterte hastighetsmål
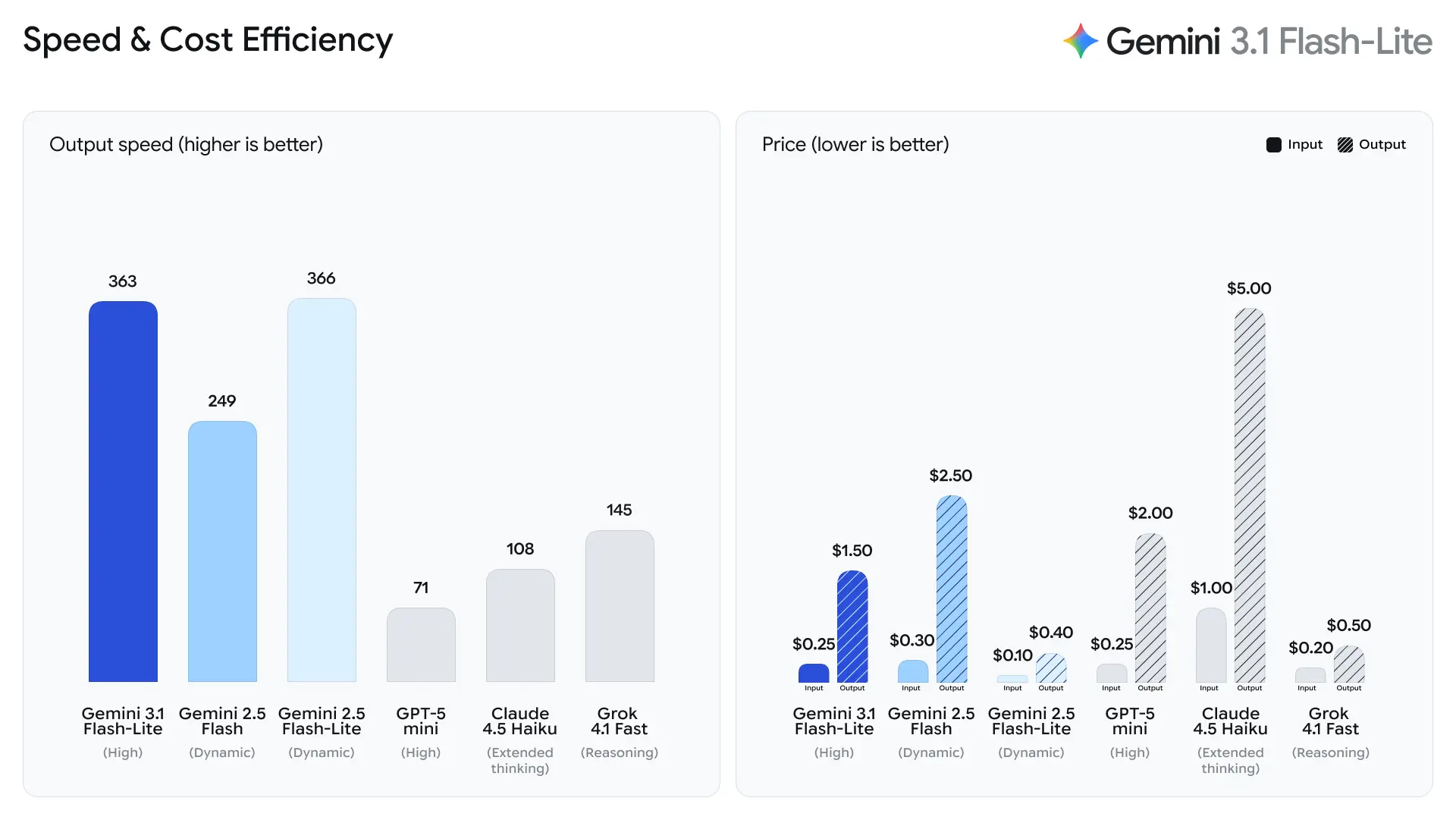
- 2.5× raskere tid til første svartoken sammenlignet med Gemini 2.5 Flash (Googles oppgitte interne sammenligning).
- 45% raskere utdatagenerering sammenlignet med Gemini 2.5 Flash.
Dette er ytelsestekniske måltall snarere enn menneskelig vurdert kvalitetsmåling; de gjenspeiler forbedringer i kjøretidsmikroarkitektur, batching og optimaliseringer i inferensstakken som reduserer latens for korte svar. Raskere tid til første token reduserer opplevd forsinkelse i interaktive applikasjoner og øker total gjennomstrømming per server, noe som kan senke totale beregningskostnader for samme QPS.
Tokens per sekund (t/s) og gjennomstrømming
Ifølge testdata fra Artificial Analysis oppnådde 3.1 Flash-Lite en utdatahastighet på 388.8 tokens per sekund (medianen for modeller i samme prisklasse er bare 96.7 tokens/sekund). Denne hastigheten er i toppsjiktet blant modeller i sin klasse.
Artificial Analysis påpekte imidlertid også et problem: 3.1 Flash-Lite sin latens til første token (TTFT) er 5.18 sekunder, noe som er relativt høyt for inferensmodeller i samme prisklasse (medianen er 1.82 sekunder). I tillegg genererte modellen 53 millioner tokens under evalueringsprosessen, noe som er relativt høyt sammenlignet med gjennomsnittet på 20 millioner. Dette betyr at hvis scenariet ditt er svært følsomt for latens til første token eller har strenge krav til output-konsishet, kan det være nødvendig å optimalisere tenkenivået og promptene.
Benchmark-poeng for resonnering og faktuell nøyaktighet
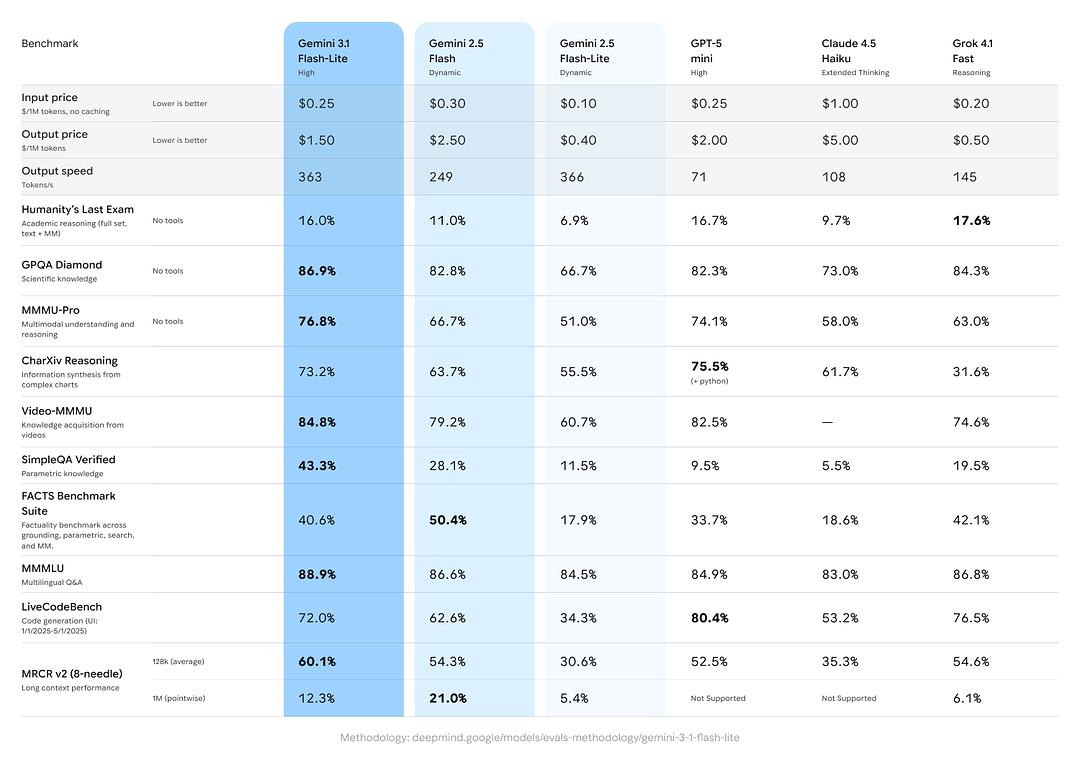
Google inkluderte kryssmodell-sammenligninger som viser at Gemini 3.1 Flash-Lite presterer sterkt mot jevnaldrende og tidligere Gemini-varianter på aggregerte resonnerings-/faktuelle oppgaver:
- Arena.ai Elo-score: Gemini 3.1 Flash-Lite skal ha oppnådd en Elo på 1432 på Arena-evalueringsledertavlen — en sammensatt head-to-head-rangering som viser konkurransedyktig relativ ytelse i direkte sammenligningsscenarier.
- GPQA Diamond: 86.9% (en indikator på robusthet i spørsmål–svar).
- MMMU Pro: 76.8% (en multimodal/multitask-metrikk brukt internt/eksternt av noen laboratorier).
- LiveCodeBench (kodeferdigheter): 72.0%
- CharXiv Reasoning (grafisk resonnering): 73.2%
- Video-MMMU (videoforståelse): 84.8%
Gemini 3.1 Flash-Lite overgår eldre Gemini 2.5 Flash på flere av disse målene samtidig som den leverer langt bedre hastighet/kostnad.
Bruksområder som passer for Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite er designet rundt et tydelig sett av praktiske arbeidslaster der høy gjennomstrømming og lavere kostnad per token er avgjørende:
Høyfrekvente konversasjonsagenter og strømmende grensesnitt
Sanntidschatboter, direkte transkripsjon + oversettelsesstrømmer og samarbeidsorienterte grensesnitt som viser delvise svar mens modellen genererer, drar nytte av Flash-Lites strømmende token-output og lave tid til første token.
Massebehandling av data (RAG, transformasjons-pipelines)
Massiv dokumentinntak: enhetsekstraksjon, metadata-tagging, klassifisering og oversettelsesoppgaver utført over millioner av dokumenter — Gemini 3.1 Flash-Lite senker inferenskostnaden samtidig som den gir akseptabel nøyaktighet for mal- eller regelstyrte output.
Edge-stil eller bakgrunnsberegning
Arbeidslaster som kontinuerlig prosesserer innkommende telemetri eller ustrukturert data (f.eks. innholdsmoderering med klassifiseringsrørledninger, automatisert rapportgenerering) passer godt, fordi Gemini 3.1 Flash-Lite minimerer kostnad per enhet.
Utviklerverktøy og batch-kodefullføring
For funksjoner som flerfil-stillas, storskala kodelinting og malgenerering i stor skala, reduserer Gemini 3.1 Flash-Lites hastighetsfordeler latens og kostnader for utviklerverktøy der absolutt maksimal resonneringsdybde ikke er nødvendig.
Sammenligning av Gemini 3.1 Flash-Lite med andre Gemini-modeller og konkurrenter
Innenfor Gemini-familien
- Gemini 3.1 Pro: høyest kapasitet på kompleks resonnering og flertrinnsplanlegging; betydelig dyrere og tregere per token, men bedre for dype, nyanserte oppgaver.
- Gemini 3.1 Flash (ikke-Lite): sikter på et mellompunkt mellom rå gjennomstrømming og kapasitet — Flash-Lite optimaliserer enda lenger ned i beregningsstakken for gjennomstrømming.
Sammenlignet med konkurrerende «raske» modeller
Gemini 3.1 Flash-Lite overgår eller matcher flere raske/mini-modeller på mange gjennomstrømmings- og kvalitetsmål — likevel advarer uavhengige analytikere om at direkte head-to-head-sammenligninger er følsomme for evalueringsmetodikk og valg av datasett. Forvent at Gemini 3.1 Flash-Lite er svært konkurransedyktig på gjennomstrømming og kostnad, samtidig som den ligger nær midten av feltet på de høyeste resonneringsmålene.
Konklusjon — hvor Flash-Lite passer i AI-stakken
Gemini 3.1 Flash-Lite er et bevisst konstruert tilbud: et effektivt, gjennomstrømmingsfokusert medlem av Gemini 3-familien som lar team bytte bort noe beregning per eksempel for dramatiske forbedringer i latens og kostnad. For virksomheter og utviklere som bygger arbeidslaster i stort volum — oversettelser, batch-prosessering, strømmende grensesnitt og moderat komplekse agentiske oppgaver — representerer Flash-Lite en fornuftig grunnmotor. For organisasjoner som krever absolutt høyeste resonneringsfidelitet, forblir Pro-modellene det riktige valget.
Hvis arbeidslasten din domineres av mange korte, repeterbare inferenser eller du trenger rask strømmende output i stor skala, er Flash-Lite verdt å prøve ut. Hvis arbeidslasten din avhenger av dyp flerhopp-resonnering, planlegg en hybrid tilnærming: rute trafikk med høy gjennomstrømming til Flash-Lite og eskaler høyt verdsatte, komplekse forespørsler til Pro-modeller.
Utviklere kan få tilgang til Gemini 3.1 Flash Lite via CometAPI nå. For å komme i gang, utforsk modellens muligheter i Playground og se API-veiledningen for detaljerte instruksjoner. Før du får tilgang, må du sørge for at du har logget inn på CometAPI og hentet API-nøkkelen. CometAPI tilbyr en pris som er langt lavere enn den offisielle prisen for å hjelpe deg å integrere.
Klar til å starte?→ Registrer deg for Gemini 3.1 Flash Lite i dag!
Hvis du vil ha flere tips, guider og nyheter om AI, følg oss på VK, X og Discord!