

Pada 3 Maret 2026, Google memperkenalkan Gemini 3.1 Flash-Lite, anggota terbaru dari keluarga Gemini 3 yang dirancang khusus sebagai mesin ber-throughput tinggi, berlatensi rendah, dan hemat biaya untuk beban kerja pengembang dan perusahaan. Google memosisikan Flash-Lite sebagai model “tercepat dan paling hemat biaya” dalam lini Gemini 3: varian ringan yang bertujuan menghadirkan interaksi streaming, pemrosesan latar belakang skala besar, dan tugas produksi berfrekuensi tinggi (misalnya, penerjemahan, ekstraksi, pembuatan UI, dan klasifikasi volume besar) dengan harga jauh lebih rendah dibandingkan varian Pro.
Di bawah ini kami menguraikan apa itu Flash-Lite.
Apa itu Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite adalah anggota keluarga Google Gemini 3 yang secara sengaja menukar sebagian kedalaman penalaran tingkat tertinggi demi kecepatan dan efisiensi biaya. Ia secara native multimodal dalam garis keturunan Gemini (mampu menerima teks, gambar, dan modalitas lain sebagai input), tetapi disetel dan di-deploy secara khusus untuk menghadirkan throughput token per detik maksimal serta penagihan per-token yang secara substansial lebih rendah untuk beban kerja yang membutuhkan inferensi cepat dan berulang alih-alih kedalaman kognitif maksimal. Model ini digambarkan berasal dari arsitektur 3.1 Pro tetapi dioptimalkan untuk throughput, latensi, dan biaya.
Kompromi desain utama
Sebutan "Lite" menandakan penekanan rekayasa model ini:
- Throughput ketimbang penalaran berat: Flash-Lite sengaja mengurangi komputasi per token untuk menghadirkan Time-to-First-Token (TTFT) yang lebih cepat dan kecepatan keluaran yang berkelanjutan. Hal ini menjadikannya ideal untuk pipeline di mana setiap permintaan harus dilayani dengan cepat dan dalam skala besar (misalnya, filter keamanan, asisten real-time, generasi volume tinggi).
- Efisiensi biaya untuk volume tinggi: Dengan menurunkan komputasi per token, model dapat ditawarkan dengan harga yang lebih rendah per satu juta token, yang mengurangi biaya marjinal dalam aplikasi skala besar (misalnya, jutaan hingga miliaran token per bulan). Harga pratinjau Google menunjukkan selisih signifikan dibandingkan tier Pro.
- Kualitas yang disetel untuk tugas pragmatis: Menurut ringkasan skor awal, Flash-Lite mempertahankan hasil yang kuat pada klasifikasi standar, multibahasa, dan banyak tugas multimodal, namun tidak diposisikan untuk mengalahkan Pro pada tolok ukur penalaran multi-langkah atau pembuatan kode yang paling kompleks di mana kedalaman sangat penting.
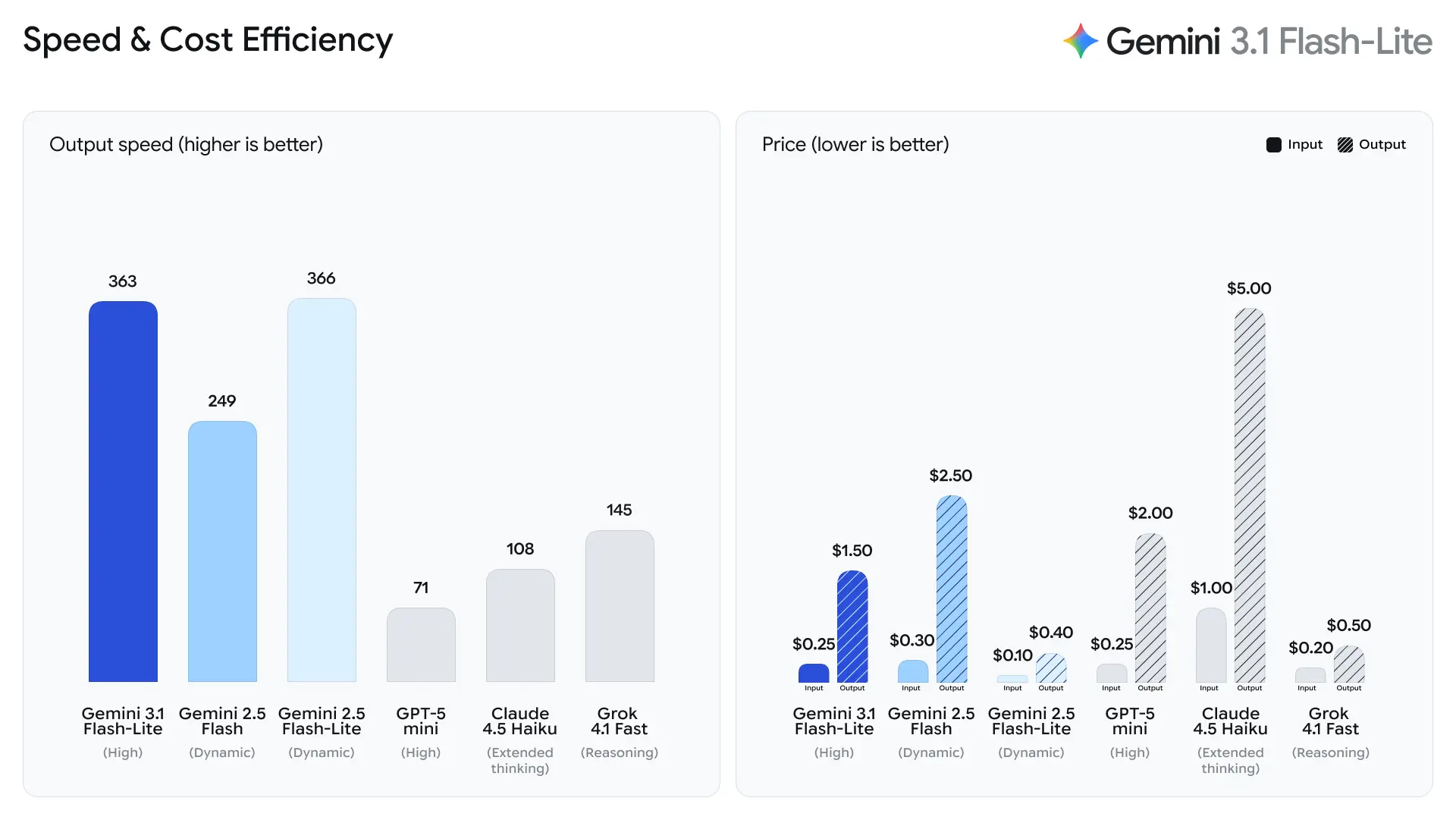
Beban kerja ini membutuhkan output yang andal dan throughput tinggi, namun tidak selalu membutuhkan kemampuan penalaran multi-langkah yang kompleks dari model flagship.
Fitur Utama Gemini 3.1 Flash-Lite
1. Latensi rendah dan waktu token pertama yang cepat
Google menekankan waktu menuju token jawaban pertama sebagai metrik utama untuk Flash-Lite. Perusahaan melaporkan ~2,5× lebih cepat waktu menuju token pertama dibandingkan Gemini 2.5 Flash dan hingga 45% lebih cepat generasi output — peningkatan yang secara langsung berdampak pada responsivitas yang dirasakan pengguna akhir dan biaya throughput untuk sistem back-end. Peningkatan ini menjadikan Flash-Lite sangat cocok untuk fitur interaktif (misalnya, chatbot yang disematkan dalam aplikasi) dan pipeline QPS tinggi di mana mikrodetik berpengaruh.
Peningkatan ini secara signifikan meningkatkan aplikasi real-time seperti:
- AI percakapan
- asisten pencarian bertenaga AI
- chatbot interaktif
- layanan penerjemahan langsung
Latensi yang lebih rendah meningkatkan pengalaman pengguna dengan mengurangi waktu tunggu dan memungkinkan interaksi yang lebih mulus.
2. Harga Token Hemat Biaya
Biaya inferensi AI sering dihitung per token, menjadikan harga sebagai faktor kritis untuk penerapan skala besar.
Gemini 3.1 Flash-Lite memperkenalkan struktur harga yang sangat kompetitif:
| Jenis Token | Harga |
|---|---|
| Token input | $0.25 per 1M tokens |
| Token output | $1.50 per 1M tokens |
Ini mewakili penurunan dibandingkan model Flash sebelumnya, menjadikan model ini menarik bagi organisasi yang menjalankan beban kerja besar.
Sebagai perbandingan:
| Model | Harga input | Harga output |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Strategi harga ini memungkinkan pengembang menjalankan AI dalam skala besar tanpa secara dramatis meningkatkan biaya operasional.
Jika Anda mencari harga yang lebih baik lagi, maka Gemini Flash-Lite menawarkan diskon 20% di CometAPI.
3. “Thinking levels” (kedalaman inferensi yang dapat dikendalikan)
Gemini 3.1 Flash-Lite menyertakan kemampuan “thinking levels” — pengaturan yang dapat dikonfigurasi pengembang yang menginstruksikan model untuk lebih memilih pemrosesan yang lebih cepat dan dangkal untuk tugas trivial dan penalaran yang lebih dalam untuk tugas yang lebih sulit. Ini penting dalam praktik karena memungkinkan kompromi biaya/latensi secara dinamis per permintaan tanpa mengganti model.
Pengembang dapat mengonfigurasi kedalaman penalaran model agar sesuai dengan kompleksitas tugas. Thinking levels: Mendukung empat level: Minimal, Low, Medium, dan High.
Pendekatan dinamis ini memungkinkan aplikasi mengoptimalkan penggunaan sumber daya sambil mempertahankan kualitas pada aspek yang penting. Strategi praktisnya kira-kira sebagai berikut:
- Minimal/Low: Cocok untuk tugas yang sangat konkuren namun secara logika sederhana seperti penerjemahan, klasifikasi, dan analisis sentimen, dengan memprioritaskan kecepatan maksimum dan biaya minimum.
- Medium: Cocok untuk sebagian besar tugas produksi, menyeimbangkan kualitas dan efisiensi.
- High: Cocok untuk tugas yang membutuhkan penalaran mendalam, seperti membuat antarmuka pengguna, membuat simulasi, dan menjalankan instruksi kompleks.
4. Kapabilitas multimodal dengan jejak ringan
Walaupun Flash-Lite dioptimalkan untuk kecepatan dan biaya, ia mempertahankan fondasi multimodal lini Gemini 3: dapat menerima input gambar untuk klasifikasi atau penalaran multimodal ringan saat kasus penggunaan membutuhkannya — tetapi pengembang harus mengharapkan desain ekonomis ini lebih memilih operasi multimodal yang lebih pendek dan terbatas dibandingkan alur kerja yang sangat berat oleh gambar. Seperti model Gemini lainnya, Gemini 3.1 Flash-Lite mendukung input multimodal, memungkinkan pengembang memproses berbagai jenis data.
Input yang didukung meliputi:
- Teks
- Gambar
- Video
- Audio
Kemampuan model untuk menganalisis berbagai jenis informasi memungkinkan kasus penggunaan baru, seperti:
- pemrosesan dokumen otomatis
- ekstraksi data visual
- peringkasan multimedia
Model Gemini sebelumnya juga menunjukkan kemampuan penalaran multimodal yang kuat pada tolok ukur visual dan pengetahuan.
Tolok ukur performa — angka nyata dan artinya
Pengumuman dan dokumentasi produk Google menyajikan beberapa data tolok ukur yang dimaksudkan untuk membantu pembeli memahami posisi Flash-Lite dalam ekosistem.
Metrik kecepatan untuk pengembang
- 2,5× lebih cepat Waktu menuju Token Jawaban Pertama vs Gemini 2.5 Flash (perbandingan internal yang dinyatakan Google).
- 45% lebih cepat generasi output vs Gemini 2.5 Flash.
Ini adalah metrik rekayasa performa alih-alih metrik kualitas yang dinilai manusia; metrik ini mencerminkan peningkatan dalam mikroarsitektur runtime, batching, dan optimasi tumpukan inferensi yang mengurangi latensi untuk respons pendek. Waktu token pertama yang lebih cepat mengurangi jeda yang dirasakan dalam aplikasi interaktif dan meningkatkan throughput per server secara keseluruhan, yang dapat menurunkan total biaya komputasi untuk QPS yang sama.
Token per detik (t/s) dan throughput
Menurut data uji Artificial Analysis, 3.1 Flash-Lite mencapai kecepatan output 388,8 token per detik (median untuk model dalam kisaran harga yang sama hanya 96,7 token/detik). Kecepatan ini berada di tingkat teratas di antara model di kelasnya.
Namun, Artificial Analysis juga menyoroti masalah: latensi token pertama (TTFT) 3.1 Flash-Lite adalah 5,18 detik, yang relatif tinggi untuk model inferensi dalam kisaran harga yang sama (median adalah 1,82 detik). Selain itu, model menghasilkan 53 juta token selama proses evaluasi, yang relatif tinggi dibandingkan rata-rata 20 juta. Ini berarti bahwa jika skenario Anda sangat sensitif terhadap latensi token pertama atau memiliki persyaratan ketat untuk keringkasan output, Anda mungkin perlu mengoptimalkan tingkat thinking dan prompt.
Skor tolok ukur untuk penalaran dan faktualitas
Google menyertakan perbandingan lintas-model yang menunjukkan Gemini 3.1 Flash-Lite tampil kuat melawan para pesaing dan varian Gemini sebelumnya pada tugas penalaran/faktualitas agregat:
- Arena.ai Elo score: Gemini 3.1 Flash-Lite dilaporkan mencapai Elo 1432 pada papan peringkat evaluasi Arena — peringkat gabungan head-to-head yang menunjukkan performa relatif kompetitif dalam skenario pertandingan langsung.
- GPQA Diamond: 86,9% (tolok ukur ketangguhan tanya jawab).
- MMMU Pro: 76,8% (metrik multimodal/multi-tugas yang digunakan secara internal/eksternal oleh beberapa lab).
- LiveCodeBench (Kemampuan Coding): 72,0%
- CharXiv Reasoning (Penalaran Grafis): 73,2%
- Video-MMMU (Pemahaman Video): 84,8%
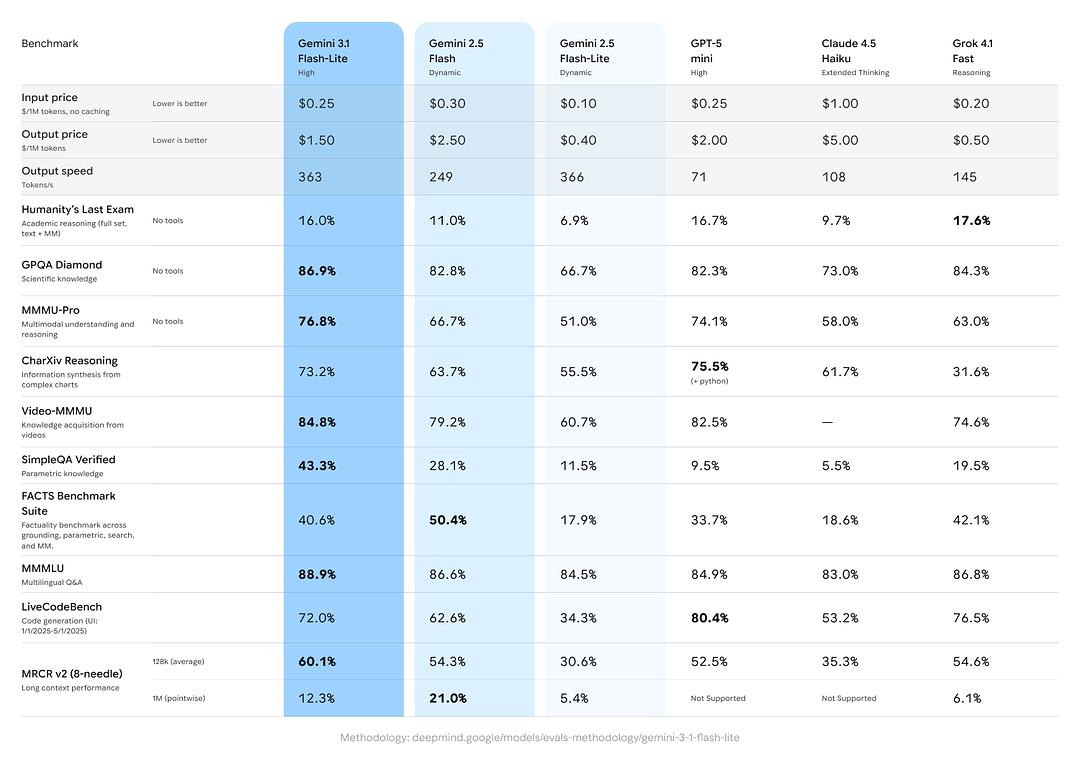
Gemini 3.1 Flash-Lite melampaui Gemini 2.5 Flash yang lebih lama pada beberapa metrik ini sambil menghadirkan kecepatan/biaya yang jauh lebih baik.
Kasus penggunaan yang cocok untuk Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite dirancang berdasarkan serangkaian beban kerja praktis yang jelas di mana throughput tinggi dan biaya per token yang lebih rendah sangat menentukan:
Agen percakapan berfrekuensi tinggi & UI streaming
Chatbot real-time, transkripsi + terjemahan langsung, dan UI kolaboratif yang menampilkan jawaban parsial saat model menghasilkan akan mendapatkan manfaat dari output token streaming Flash-Lite dan waktu menuju token pertama yang rendah.
Pemrosesan data massal (RAG, pipeline transformasi)
Ingesti dokumen masif: ekstraksi entitas, penandaan metadata, klasifikasi, dan penerjemahan yang dilakukan pada jutaan dokumen — Gemini 3.1 Flash-Lite menurunkan biaya inferensi sambil menyediakan akurasi yang dapat diterima untuk output templated atau berbasis aturan.
Komputasi gaya edge atau latar belakang
Beban kerja yang secara terus-menerus memproses telemetri masuk atau data tidak terstruktur (misalnya, pipeline klasifikasi moderasi konten, pembuatan laporan otomatis) cocok karena Gemini 3.1 Flash-Lite meminimalkan biaya per unit.
Perangkat pengembang dan pelengkapan kode batch
Untuk fitur seperti scaffolding multi-file, linting kode skala besar, dan pembuatan template dalam skala, keunggulan kecepatan Gemini 3.1 Flash-Lite mengurangi latensi dan biaya untuk perangkat pengalaman pengembang di mana kedalaman penalaran maksimal tidak diperlukan.
Membandingkan Gemini 3.1 Flash-Lite dengan model Gemini lain dan kompetitor
Di dalam keluarga Gemini
- Gemini 3.1 Pro: kemampuan tertinggi pada penalaran kompleks dan perencanaan multi-langkah; secara signifikan lebih mahal dan lebih lambat per token tetapi lebih baik untuk tugas yang dalam dan bernuansa.
- Gemini 3.1 Flash (non-Lite): menargetkan titik tengah antara throughput mentah dan kapabilitas — Flash-Lite mengoptimalkan lebih jauh ke tumpukan komputasi untuk throughput.
Dibandingkan dengan model “cepat” pesaing
Gemini 3.1 Flash-Lite mengungguli atau menyamai beberapa model cepat/mini pada banyak metrik throughput dan kualitas — namun analis independen mengingatkan bahwa perbandingan head-to-head sensitif terhadap metodologi evaluasi dan pemilihan dataset. Harapkan Gemini 3.1 Flash-Lite sangat kompetitif dalam throughput dan biaya sambil tetap berada di sekitar tengah-tengah pada metrik penalaran tertinggi.
Kesimpulan — posisi Flash-Lite dalam tumpukan AI
Gemini 3.1 Flash-Lite adalah penawaran yang direkayasa secara sengaja: anggota keluarga Gemini 3 yang efisien dan berfokus pada throughput yang memungkinkan tim menukar sebagian komputasi per contoh untuk peningkatan dramatis dalam latensi dan biaya. Untuk bisnis dan pengembang yang membangun pipeline volume tinggi — penerjemahan, pemrosesan batch, UI streaming, dan tugas agenik dengan kompleksitas sedang — Flash-Lite mewakili mesin baseline yang masuk akal. Untuk organisasi yang membutuhkan fidelitas penalaran setinggi mungkin, model Pro tetap menjadi pilihan yang tepat.
Jika beban kerja Anda didominasi oleh banyak inferensi pendek dan berulang atau Anda membutuhkan output streaming cepat dalam skala besar, Flash-Lite layak untuk dipilotkan. Jika beban kerja Anda bergantung pada penalaran multi-hop yang dalam, rencanakan pendekatan hibrida: rute trafik throughput ke Flash-Lite dan eskalasi kueri bernilai tinggi serta kompleks ke model Pro.
Pengembang dapat mengakses Gemini 3.1 Flash Lite melalui CometAPI sekarang. Untuk memulai, jelajahi kapabilitas model di Playground dan lihat API guide untuk instruksi terperinci. Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga yang jauh lebih rendah daripada harga resmi untuk membantu Anda berintegrasi.
Siap Mulai?→ Daftar untuk Gemini 3.1 Flash-Lite hari ini !
Jika Anda ingin mengetahui lebih banyak tips, panduan, dan berita tentang AI ikuti kami di VK, X dan Discord!