

xAI dirilis diam-diam Grok 4.1 (17–18 November 2025) — peningkatan terfokus pada Grok 4 yang memprioritaskan kecerdasan emosional, ekspresi kreatif, dan berkurangnya halusinasi dengan tetap mempertahankan penalaran tajam dari rilis Grok sebelumnya. Fitur ini hadir dalam dua mode (Berpikir/Tidak Berpikir), diluncurkan secara diam-diam di awal November, menampilkan hasil papan peringkat teratas di LMArena, dan tersedia melalui grok.com, aplikasi Grok, dan API.
Apa itu Grok 4.1?
Grok 4.1 adalah penerus Grok 4 yang inkremental dan berfokus pada produksi: sebuah anggota keluarga yang dibangun di atas fondasi pembelajaran penguatan skala besar yang sama, tetapi telah disempurnakan dan dilatih ulang dengan optimasi pasca-pelatihan yang intensif yang ditujukan untuk gaya, kepribadian, keselarasan, dan keandalan di dunia nyata. Grok 4.1 diposisikan sebagai langkah maju yang pragmatis dan "bermanfaat": lebih cerdas dalam tes preferensi manusia buta, lebih cerdas secara emosional, lebih baik dalam menulis kreatif, dan secara terukur lebih tahan terhadap "halusinasi" yang meyakinkan namun salah, yang telah mengganggu LLM berkinerja tinggi sebelumnya.
Grok 4.1 mencapai perubahan kualitatif dalam empat dimensi berikut:
- Kreativitas: Menunjukkan gaya bahasa dan imajinasi yang lebih kuat dalam menulis, bercerita, dan konteks sosial;
- Kecerdasan Emosional: Mengenali nada dan perubahan emosi, merespons dengan logika emosional yang lebih manusiawi dan menghasilkan respons yang menenangkan dan pengertian;
- Koherensi Kepribadian: Mempertahankan nada dan kepribadian yang konsisten dalam percakapan yang panjang, tidak lagi menunjukkan perilaku yang tidak konsisten dari model sebelumnya;
- Kolaboratif: Mempertahankan koherensi dan kesadaran tujuan dalam dialog multi-giliran atau kolaborasi tugas.
xAI merangkum karakteristiknya dalam satu kalimat: “Ia lebih perseptif, lebih empati, dan lebih seperti orang yang koheren.”
Bagaimana cara kerja Grok 4.1?
Grok 4.1 paling baik dipahami sebagai tulang punggung pra-pelatihan yang sama yang digunakan di seluruh keluarga Grok 4 ditambah jalur pasca-pelatihan berlapis yang berfokus pada pemodelan penghargaan, penyelarasan gaya, dan evaluator agen.
Apa saja tahapan pelatihan dan penyelarasan?
Grok 4.1 bekerja pada alur kerja multi-tahap yang merupakan ciri khas LLM modern, diadaptasi dengan dua perubahan penting untuk 4.1:
- Pra-latihan + pertengahan-latihan: Pra-pelatihan korpus besar pada data web + pelatihan tengah yang ditargetkan untuk meningkatkan pengetahuan domain dan kemampuan multi-moda.
- Penyetelan halus yang diawasi (SFT): Demonstrasi manusia untuk perilaku yang diinginkan (balasan, strategi penolakan).
- Pemodelan penghargaan (aplikasi baru): Model penghargaan yang dilatih xAI tidak hanya pada label preferensi manusia tetapi juga digunakan model penalaran agen perbatasan sebagai pemberi nilai penghargaan — yang secara efektif memungkinkan evaluator berbasis model berkemampuan tinggi menilai keluaran kandidat dalam skala besar. Hal ini memungkinkan optimalisasi atribut yang tidak dapat diverifikasi seperti gaya, kohesi kepribadian, empati dan kesediaan membantu tanpa memerlukan anggaran pelabelan manusia yang sangat besar.
- Optimalisasi kebijakan (RLHF / RL dari penghargaan model): Optimalisasi kebijakan standar menggunakan sinyal imbalan yang dipelajari untuk menghasilkan kebijakan yang diterapkan (model yang berinteraksi dengan konsumen).
Apa yang baru dalam pendekatan pemodelan penghargaan?
Dalam RLHF tradisional, Anda mengumpulkan label preferensi manusia (A/B), melatih model imbalan untuk memprediksi label tersebut, lalu mengoptimalkan model dasar dengan RL (atau pengambilan sampel penolakan) terhadap imbalan yang dipelajari tersebut. Namun, ada dua inovasi praktis yang disoroti xAI:
- Model penghargaan agen: Alih-alih menggunakan penilaian manusia semata, xAI menggunakan model penalaran "agentik" yang mumpuni sebagai penilai untuk mengevaluasi atribut yang lebih subtil (nada, nuansa emosional, kreativitas). Penilai dapat menjalankan ribuan perbandingan berpasangan dengan cepat, memungkinkan para insinyur melakukan iterasi lebih cepat. Inilah mekanisme untuk peningkatan signifikan dalam gaya dan kecerdasan emosional.
- Penyelarasan pasca pelatihan untuk sinyal yang tidak dapat diverifikasi: untuk atribut yang tidak dapat diukur dengan metrik deterministik (misalnya, “kehangatan” atau “kepribadian yang koheren”) mereka memperkenalkan tujuan penghargaan khusus dan kurikulum penskalaan sehingga model mempelajari gaya keluaran tanpa mengorbankan keakuratan fakta inti.
Bagaimana “berpikir” vs “tidak berpikir” beroperasi secara teknis?
- Grok 4.1 Berpikir (nama kode
quasarflux) — memaparkan langkah-langkah penalaran eksplisit (token berpikir) sebelum menghasilkan jawaban akhir; dioptimalkan untuk tugas-tugas kompleks dan Elo yang lebih tinggi di LMArena. Token tambahan ini membutuhkan waktu inferensi tetapi membantu tugas-tugas penalaran multi-langkah, debugging, dan kemampuan menjelaskan. - Grok 4.1 Non-Thinking (nama kode
tensor) melewati token perantara eksplisit untuk respons akhir tunggal yang langsung. Hal ini mengurangi latensi dan biaya token, sekaligus tetap mendapatkan manfaat dari bobot kebijakan yang telah disempurnakan. Mode non-berpikir dioptimalkan agar memiliki latensi yang sangat rendah namun tetap berkemampuan tinggi.
Optimalisasi penyelarasan sentimen dan gaya
Lebih dari sekadar sinyal "kejujuran", Grok 4.1 mencakup optimasi penyelarasan yang terarah untuk sentimen, nada, dan gaya interpersonal. Artinya, alur pelatihan mencakup komponen imbalan atau kerugian yang secara eksplisit menghukum nada yang tidak sesuai (misalnya, bersikap singkat yang tidak perlu padahal empati diperlukan) dan memberikan imbalan atas respons yang sesuai dengan gaya atau profil sentimen yang diinginkan. Dalam Grok 4.1, AI pertama kali memperkenalkan tujuan optimasi "Penyelarasan Kepribadian".
Tujuannya adalah untuk membantu model mempertahankan rasa identitas yang konsisten dan stabil. Dibandingkan dengan Grok 4, 4.1 menambahkan hal-hal berikut ke dalam tujuan pelatihan:
- Hadiah positif untuk dimensi ekspresi emosi (hadiah keselarasan emosi);
- Metrik koherensi kepribadian.
Bagaimana Grok 4.1 dievaluasi — dan bagaimana kinerjanya?
Apa yang ditunjukkan oleh uji preferensi manusia yang buta?
Selama peluncuran diam-diam, Grok 4.1 lebih disukai 64.78% dibandingkan model produksi sebelumnya dalam lalu lintas langsung — sinyal preferensi manusia yang kuat yang menunjukkan hasil percakapan yang lebih baik di alam liar.
Apakah Grok 4.1 menduduki puncak papan peringkat?
xAI melaporkan bahwa Grok 4.1 Pikir mode duduk di #1 di Text Arena LMArena, dengan Elo yang dilaporkan sebesar 1483, dan mode non-penalarannya (cepat) menduduki peringkat #2 dengan 1465 Elo — penempatan papan peringkat publik yang kuat untuk akurasi dan presentasi (kontrol gaya memainkan peran).
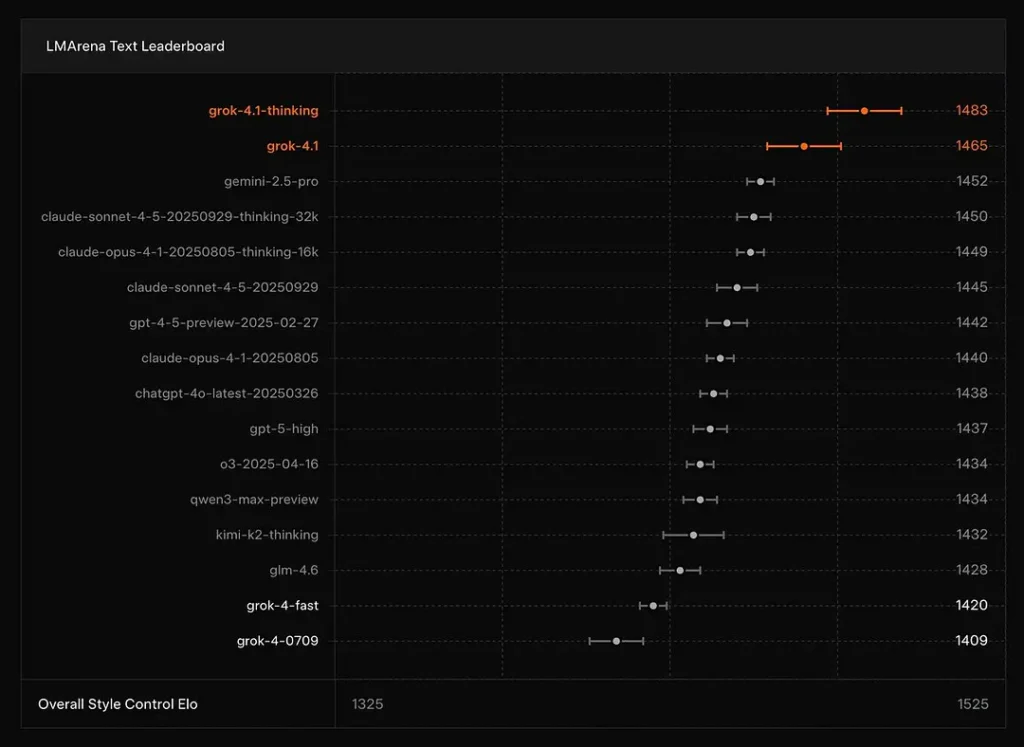
Kesimpulan: Grok 4.1 mengungguli model seri GPT-4.5 dan Claude arus utama dalam hal pemahaman teks, pembuatan dan kualitas keseluruhan, kedua setelah versi Pratinjau Lanjutan GPT-5.
Kecerdasan Emosional
xAI menjalankan EQ-Bench3, tes khusus untuk kecerdasan emosional yang mencakup 45 skenario permainan peran yang menantang, dan melaporkan bahwa Grok 4.1 menunjukkan peningkatan yang kuat dalam empati, kecepatan, dan wawasan interpersonal. Grok 4.1 mendapat skor tertinggi dalam memahami konteks kesedihan, empati, dan kenyamanan.

Menulis kreatif — apakah sebenarnya lebih imajinatif?
Grok 4.1 dievaluasi pada Menulis Kreatif v3 (32 prompt dalam 3 iterasi dengan rubrik + penilaian Elo). xAI menyatakan bahwa gaya penulisan, konsistensi suara, dan kreativitas naratif 4.1 meningkat secara substansial, menempatkannya di dekat puncak papan peringkat terbaru untuk tugas-tugas kreatif (contoh prompt disertakan dalam rilis). Laporan independen mencerminkan temuan ini: para pengulas melihat "suara yang khas" dan koherensi bentuk panjang yang jauh lebih baik. Dalam hal kualitas penulisan, Grok 4.1 berada di urutan kedua setelah model seri GPT-5 dan melampaui seluruh lini produk Claude, Gemini, dan Kimi.

Mengurangi halusinasi / kejujuran
xAI mengklaim pengurangan yang signifikan dalam tingkat halusinasi: mereka melaporkan (dalam pengumuman dan postingan sosial) Grok 4.1 adalah ~3x lebih kecil kemungkinannya untuk berhalusinasi Dibandingkan dengan model Grok sebelumnya, yang mengutip analisis lalu lintas produksi dan evaluasi bergaya FActScore (misalnya, rangkaian pertanyaan bio/biografi, semakin rendah semakin baik). Terutama dalam "mode non-penalaran" di mana alat pencarian eksternal tersedia, konsistensi fakta lebih stabil.

Mengapa Grok 4.1 “menghancurkan” model lain — apakah itu hiperbola?
“Crushes” memang terdengar seperti pemasaran, tetapi ada klaim objektif di balik klaim tersebut:
- Papan peringkat: Grok 4.1 menduduki posisi teratas di papan peringkat LMArena publik untuk pembangkitan teks (1483 Elo untuk mode Berpikir) dan performa kreatif serta EQ-bench yang kuat per rilis xAI. Ini adalah metrik kompetitif yang saling melengkapi yang digunakan di seluruh komunitas.
- Preferensi lalu lintas nyata menang: xAI melaporkan peningkatan preferensi manusia dalam perbandingan buta (~65% preferensi dibandingkan model produksi sebelumnya) dari peluncuran diam-diam pada lalu lintas langsung. Hal ini mencerminkan peningkatan pada pengguna nyata, bukan hanya tolok ukur di atas kertas.
- Kemampuan baru yang praktis: Kombinasi pemeringkat model, RL pada sinyal yang tidak dapat diverifikasi, dan filter masukan yang lebih ketat merupakan langkah rekayasa pragmatis yang secara langsung meningkatkan pengalaman pengguna dalam tugas-tugas percakapan, empati, dan kreatif di mana para pesaing secara historis berkinerja buruk.
Jadi, meskipun “menghancurkan” adalah cara yang berwarna untuk mengatakan “memimpin dalam berbagai evaluasi publik dan internal,” metrik publik yang mendasari yang diterbitkan xAI mendukung kesimpulan tersebut
Cara mengakses Grok 4.1
Akses konsumen / aplikasi
xAI secara berkala membuat Grok 4.1 dapat diakses dalam mode "Otomatis" secara gratis atau sebagai jendela promosi, tetapi tingkatan premium (SuperGrok, SuperGrok Heavy) dan akses API dengan kuota yang lebih tinggi ada dan tetap ada sebagai penawaran berbayar.
Grok 4.1 tersedia untuk semua pengguna on grok.com, X (sebelumnya Twitter), dan aplikasi Grok iOS dan Android, diluncurkan segera dalam mode Otomatis sekaligus dapat dipilih secara eksplisit sebagai “Grok 4.1” di pemilih model.
Akses API & paket pengembang
Titik akhir Grok 4.1 tersedia melalui API xAI. Hingga artikel ini diterbitkan, API GPT 4.1 resmi belum dirilis.
API Komet berjanji untuk terus mengikuti dinamika model terbaru termasuk API Grok 4.1, yang akan dirilis bersamaan dengan rilis resminya. Mohon nantikan dan terus pantau CometAPI. Sambil menunggu, Anda dapat memperhatikan model-model Grok lainnya seperti Grok-kode-cepat-1 dan Grok 4, jelajahi kapabilitas mereka di Playground dan lihat panduan API untuk instruksi detail untuk memanggil . Sebelum mengakses, pastikan Anda telah masuk ke CometAPI dan mendapatkan kunci API.
Tips praktis untuk menggunakan Grok 4.1 dalam produksi
Cara mengurangi risiko halusinasi
- Aktifkan pencarian langsung atau rantai alat terverifikasi untuk pertanyaan pencarian informasi.
- Berikan langkah verifikasi: meminta model untuk mengembalikan sumber dan bukti untuk klaim faktual; gunakan
responsemetadata untuk memeriksa kutipan (jika tersedia). - Jalankan pemeriksaan deterministik (LLM pemeriksa fakta, validator data terstruktur) sebagai langkah pasca-pemrosesan untuk keluaran berisiko tinggi.
Cara mengendalikan nada dan gaya
- Gunakan perintah sistem yang eksplisit untuk memperbaiki suara (“Anda formal dan empati.”).
- Gunakan perintah yang diawasi dan templat lokal kecil untuk suara yang konsisten di seluruh aplikasi.
- Jika tersedia, manfaatkan opsi kontrol gaya xAI dan tombol kemudi yang digerakkan oleh hadiah.
Keputusan akhir: apakah Grok 4.1 merupakan perubahan besar?
Grok 4.1 adalah tidak sebuah arsitektur yang benar-benar baru; melainkan sebuah arsitektur yang canggih dan penuh pertimbangan pasca pelatihan / penyelarasan rilis yang berfokus pada apa yang sebenarnya menjadi perhatian manusia dalam obrolan: kepribadian, kecerdasan emosional, kreativitas, dan lebih sedikit kesalahan faktualPeningkatan yang terukur pada papan peringkat, preferensi lalu lintas nyata berskala besar, dan perangkat keselamatan yang lebih baik. Untuk aplikasi yang mengandalkan percakapan berkualitas tinggi, kolaborasi kreatif, atau bantuan yang peka terhadap nada, Grok 4.1 merupakan langkah maju yang besar dan, dalam beberapa uji coba komunitas, merupakan yang terbaik saat dirilis.
CometAPI adalah platform agregasi API komersial yang memberikan pengembang akses REST terpadu bergaya OpenAI ke ratusan model AI dari berbagai vendor — LLM teks, generator gambar/video, embedding, dan lainnya — melalui satu antarmuka yang konsisten. Alih-alih menggunakan SDK terpisah atau titik akhir khusus untuk OpenAI, Anthropic, Google, Meta, atau penyedia model khusus yang lebih kecil, CometAPI memungkinkan Anda memanggil berbagai model dengan mengubah string model dan beberapa parameter.
Siap untuk mencoba?→ Daftar ke CometAPI hari ini !
Jika Anda ingin mengetahui lebih banyak tips, panduan, dan berita tentang AI, ikuti kami di VK, X dan Discord!