

Uni-1 dari Luma AI lebih dari sekadar model teks-ke-gambar baru. Dalam kerangka Luma sendiri, ini adalah “model penalaran multimodal yang dapat menghasilkan piksel,” dibangun di atas “Kecerdasan Terpadu (Unified Intelligence)” sehingga dapat memahami niat, merespons arahan, dan “berpikir bersama Anda.” Laporan teknis perusahaan menyatakan model ini menggunakan transformer autoregresif bertipe decoder-only, di mana teks dan gambar direpresentasikan dalam satu sekuens terselang-seling, dan bahwa Uni-1 dapat melakukan penalaran internal terstruktur sebelum dan selama sintesis gambar. Kombinasi itulah yang membuat Uni-1 menjadi salah satu rilis model gambar paling menarik pada 2026.
Apa itu model gambar UNI-1?
Uni-1 adalah model gambar baru dari Luma AI untuk tugas yang memerlukan pemahaman dan generasi dalam satu sistem. Luma mempresentasikannya sebagai model penalaran multimodal, bukan mesin gambar klasik berbasis difusi saja, yang penting karena model ini dimaksudkan untuk melakukan lebih dari sekadar menghasilkan keluaran yang enak dilihat: model ini dirancang untuk menafsirkan instruksi, menjaga batasan referensi, dan bernalar melalui logika adegan sebagai bagian dari proses generasi. Laporan teknis perusahaan menggambarkan Uni-1 sebagai model terpadu pertama mereka untuk pemahaman-dan-generasi dalam perjalanan menuju kecerdasan multimodal umum.
Mengapa Uni-1 berbeda
Rantai proses lama memiliki batas: generasi gambar tanpa pemahaman hanya bisa sejauh itu. Uni-1 dipresentasikan sebagai langkah menuju “kecerdasan terpadu,” di mana bahasa, persepsi, imajinasi, perencanaan, dan eksekusi ditangani dalam satu arsitektur. Ini lebih dari sekadar branding. Uni-1 dapat bergerak dari kemiripan visual menuju komposisi yang berintensi, plausibilitas, dan logika adegan.
Cerita yang lebih besar adalah bahwa model gambar menjadi lebih bersifat agen. Tumpukan gambar terbaru Google kini menekankan pengeditan percakapan, grounding pencarian, fusi multi-gambar, dan konsistensi karakter; keluarga GPT Image dari OpenAI menekankan multimodalitas bawaan dan kepatuhan instruksi. Uni-1 bergabung dalam pergeseran itu, tetapi lebih menekankan gagasan bahwa model seharusnya “berpikir” tentang gambar sebelum menggambarnya. Itu membuat Uni-1 sangat menarik untuk alur kerja di mana ketepatan dan keterulangan sama pentingnya dengan gaya visual.
Bagaimana Uni-1 sebenarnya bekerja?
🔬 Proses Tokenisasi
- Teks → urutan token
- Gambar → potongan ter-tokenisasi
- Digabung menjadi sekuens tunggal yang terselang-seling
🔁 Proses Generasi
- Masukan prompt + referensi
- Model melakukan penalaran internal
- Merencanakan komposisi
- Menghasilkan token secara berurutan
Secara matematis: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Lapisan Penalaran Internal
Uni-1:
- Menguraikan instruksi
- Menyelesaikan batasan
- Merencanakan tata letak sebelum rendering
👉 Ini merupakan lompatan besar dibanding model difusi.
Generasi autoregresif decoder-only
Detail teknis terpenting adalah bahwa Uni-1 bersifat autoregresif, bukan berbasis difusi. Laporan teknis Luma menyatakan ini adalah transformer autoregresif bertipe decoder-only, dan bahwa teks serta gambar dikodekan dalam satu sekuens terselang-seling. Secara sederhana, model tidak sekadar mulai dari noise lalu secara bertahap “mendenoise” menuju gambar. Sebaliknya, model menghasilkan token selangkah demi selangkah, memungkinkan model bernalar melalui prompt, menyelesaikan batasan, dan merencanakan komposisi sebelum dan selama proses rendering.
🔬 Proses Tokenisasi
- Teks → urutan token
- Gambar → potongan ter-tokenisasi
- Digabung menjadi sekuens tunggal yang terselang-seling
Difusi vs Autoregresif
| Fitur | Model Difusi | Uni-1 (Autoregressive) |
|---|---|---|
| Generasi | Noise → Gambar | Token demi token |
| Penalaran | Terbatas | Kuat |
| Pengeditan | Lemah | Multi-putaran |
| Render teks | Buruk | Kuat |
| Kendali | Rendah | Tinggi |
Arsitektur Inti
Uni-1 adalah:
- Transformer autoregresif bertipe decoder-only
- Ruang token bersama untuk teks + gambar
Arsitektur itu penting karena memberi model kesempatan menjaga koherensi ketika prompt rumit. Luma mengatakan Uni-1 dapat menguraikan instruksi, menyelesaikan batasan yang saling bertentangan, dan merencanakan gambar sebelum proses rendering dimulai. Itu sangat berguna untuk tugas seperti pelengkapan adegan terstruktur, penempatan multi-subjek, penyempurnaan multi-putaran, dan pengeditan yang mengharuskan keluaran tetap setia pada gambar referensi sambil tetap mematuhi instruksi baru.
Hal yang tampaknya dirancang untuk dilakukan lebih baik
Belajar menghasilkan gambar meningkatkan pemahaman. Luma mengatakan pelatihan generasi gambar secara nyata meningkatkan pemahaman visual yang terperinci, terutama pada wilayah, objek, dan tata letak. Itulah sebabnya Uni-1 diposisikan bukan sebagai generator satu arah melainkan sebagai sistem terpadu di mana generasi dan pemahaman saling memperkuat. Dari sisi inferensi, ini berarti Uni-1 berupaya menutup jurang antara “melihat” dan “membuat.” Ini merupakan lompatan besar dibanding model difusi.
Proses Generasi:
- Masukan prompt + referensi
- Model melakukan penalaran internal
- Merencanakan komposisi
- Menghasilkan token secara berurutan
Secara matematis: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Fitur dan keunggulan inti apa yang ditawarkan Uni-1?
Kepatuhan instruksi dan pengarahan yang kuat
Kekuatan utama Uni-1 adalah kendali. Model ini dibangun untuk pengeditan presisi, penggunaan referensi terstruktur, dan alur kerja yang dapat diulang. Bagi kreator, itu berarti lebih sedikit tebak-tebakan prompt dan keluaran yang lebih dapat diulang.
Salah satu keunggulan praktis Uni-1 adalah dibangun untuk iterasi terkontrol. Seed memungkinkan pengguna mereproduksi hasil, sementara peran referensi membantu model mengetahui apakah sebuah gambar harus membimbing identitas karakter, mood, palet, atau komposisi. Itu membuat Uni-1 lebih mudah diarahkan dibanding model yang sepenuhnya didorong prompt, terutama bagi tim yang memproduksi iklan, storyboard, mockup produk, atau aset brand di mana konsistensi penting.
Generasi berbasis referensi yang mempertahankan identitas
Keunggulan utama lainnya adalah penanganan referensi. Luma secara eksplisit menyatakan Uni-1 menggunakan kontrol berlandaskan sumber dan dapat mempertahankan identitas, komposisi, dan batasan visual kunci dari satu atau beberapa referensi. Itu membuatnya menarik untuk alur kerja komersial seperti karakter brand, mockup produk, aset kampanye, dan proyek apa pun di mana subjek harus tetap dikenali di berbagai variasi. Ini adalah salah satu cara paling jelas Uni-1 berbeda dari sistem gambar yang lebih estetis semata.
Kefasihan budaya dan keluasan gaya
Luma juga menekankan generasi yang peka budaya. Bagian “Cultured”-nya menunjuk pada meme, manga, gaya sinematik, foto kasual, olahraga, dan citra hewan, menunjukkan bahwa model ini dimaksudkan beroperasi lintas bahasa visual alih-alih satu gaya generik. Itu penting karena model gambar modern yang baik tidak hanya perlu merender adegan realistis; ia juga perlu memahami konvensi visual budaya internet, desain editorial, ilustrasi bergaya, dan konten sosial.
Pemikiran multimodal sebagai pilihan desain
Pembedanya bukan hanya bahwa Uni-1 menghasilkan gambar, tetapi bahwa Luma membingkai generasi gambar sebagai tugas penalaran. Uni-1 dapat melakukan penalaran internal terstruktur dan bahwa belajar menghasilkan gambar meningkatkan pemahaman visual terperinci atas wilayah, objek, dan tata letak. Itu menyiratkan model yang dimaksudkan untuk memahami adegan sebelum merendernya, bukan sekadar mengaproksimasi prompt secara statistik.
Tolok Ukur Kinerja
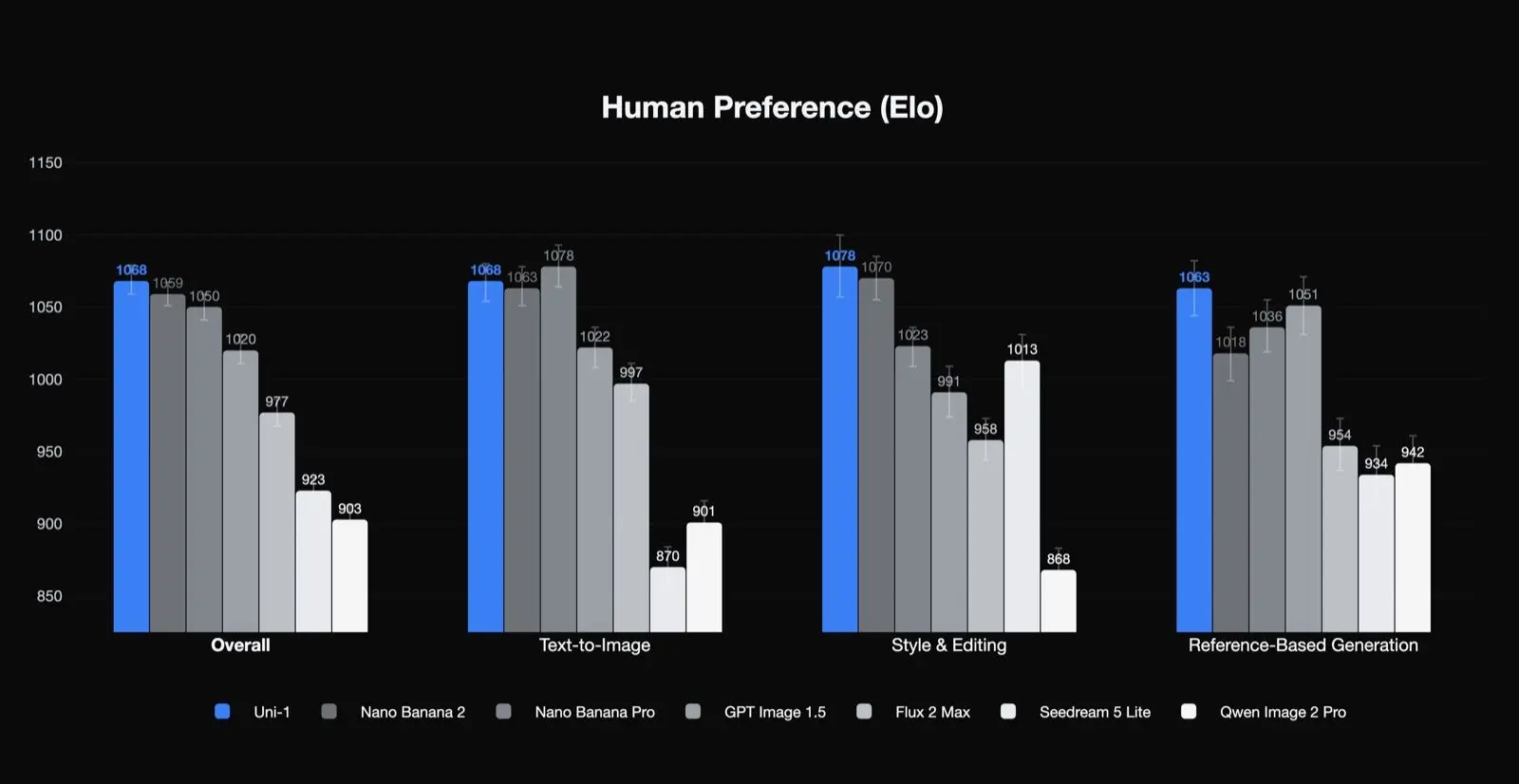
Hasil preferensi manusia versi Luma
Uni-1 menempati peringkat pertama dalam Elo preferensi manusia untuk kualitas keseluruhan, gaya dan pengeditan, serta generasi berbasis referensi, dan kedua dalam teks-ke-gambar. Itu hasil yang bermakna karena menyiratkan model ini sangat kuat pada jenis tugas yang menjadi perhatian tim produksi: pengeditan, konsistensi, dan transformasi terpandu. Ini juga menyiratkan bahwa kasus penggunaan terbaiknya mungkin bukan generasi teks-ke-gambar satu kali saja.
RISEBench: pengeditan visual berbasis penalaran
Tolok ukur yang paling mencuri perhatian adalah RISEBench, yang mengevaluasi pengeditan visual berbasis penalaran di sepanjang penalaran temporal, kausal, spasial, dan logis. Pelaporan pihak ketiga pada peluncuran Luma menyebut Uni-1 mencetak 0.51 secara keseluruhan di RISEBench, di depan Nano Banana 2 dari Google pada 0.50, Nano Banana Pro pada 0.49, dan GPT Image 1.5 dari OpenAI pada 0.46. Pada penalaran spasial, Uni-1 dilaporkan 0.58 versus Nano Banana 2 pada 0.47. Pada penalaran logis, Uni-1 dilaporkan 0.32, lebih dari dua kali GPT Image 1.5 yang 0.15. Marginnya tidak besar secara keseluruhan, tetapi besar pada kategori penalaran tersulit.

ODinW-13 dan klaim “generasi meningkatkan pemahaman”
Uni-1 juga tampil kuat pada ODinW-13, sebuah tolok ukur deteksi padat berkosakata terbuka. Pelaporan atas data teknis Luma menyebut model penuh mencetak 46.2 mAP, hampir menyamai Gemini 3 Pro milik Google di 46.3. Pelaporan yang sama menyebut varian pemahaman-saja mencetak 43.9 mAP, yang menyiratkan bahwa pelatihan generasi meningkatkan pemahaman sebesar 2.3 poin. Itu temuan yang patut dicatat karena mendukung tesis inti Luma: generasi gambar dan pemahaman gambar dapat saling memperkuat, bukan tujuan yang saling bersaing.
Harga API Uni-1
| Harga input (teks) | $0.50 |
|---|---|
| Harga input (gambar) | $1.20 |
| Harga output (teks dan penalaran) | $3.00 |
| Harga output (gambar) | $45.45 |
Di sisi konsumen, halaman harga Luma mencantumkan Plus di $30/bulan, Pro di $90/bulan, dan Ultra di $300/bulan, dengan kredit uji coba gratis disertakan di seluruh paket. Ini berarti pada dasarnya ada dua lapis harga yang perlu dipertimbangkan: keanggotaan konsumen untuk platform dan harga level API model untuk penggunaan produksi.
Untuk saat ini, API Uni-1 dari CometAPI Akan Segera Tersedia, dengan diskon yang dijanjikan saat peluncuran. Saat ini, CometAPI juga menawarkan model gambar mentah yang sangat baik, seperti Midjourney dan Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 versus Nano Banana 2 dari Google
Nano Banana 2 terlihat lebih kuat pada keluasan penanganan referensi dan integrasi ekosistem. Google menekankan grounding penelusuran gambar, iterasi percakapan, dan alur kerja kaya referensi dengan hingga 14 referensi. Uni-1, sebaliknya, lebih eksplisit dibingkai seputar penalaran, plausibilitas adegan, dan pengeditan presisi dalam arsitektur model terpadu. Secara praktis, Google tampak dioptimalkan untuk kecepatan, skala produksi arus utama, dan grounding native Google; Luma tampak dioptimalkan untuk penalaran visual terstruktur dan pengeditan gambar yang mudah diarahkan.
Dalam perbandingan publik seputar Uni-1, komprominya jelas: Nano Banana 2 tampaknya tetap sangat kuat untuk kualitas teks-ke-gambar murni dan kecepatan, sementara Uni-1 mendorong lebih jauh pada pengeditan berbasis penalaran, kendali referensi, dan fidelitas instruksi.
Uni-1 versus GPT Image dari OpenAI
Dalam pelaporan tolok ukur, Uni-1 unggul tipis atas GPT Image 1.5 pada RISEBench secara keseluruhan dan lebih tegas pada penalaran logis. Dibanding keluarga GPT Image dari OpenAI, Uni-1 diposisikan lebih sempit dan agresif seputar penalaran visual dan pengeditan terkontrol. Dokumen OpenAI menekankan pengetahuan dunia, pemahaman multimodal, dan kesadaran konteks; dokumen Luma menekankan penalaran internal terstruktur, kendali berlandaskan referensi, dan keterampilan pengeditan visual yang dibuktikan tolok ukur. Jadi meski keduanya multimodal, Uni-1 lebih jelas merupakan “model penalaran spesialis gambar,” sedangkan GPT Image terlihat seperti sistem multimodal umum yang kebetulan menghasilkan gambar dengan sangat baik.
Perbandingan harga di antara ketiganya
Dalam hal harga, perbandingan bergantung pada ukuran keluaran dan tingkat produk, jadi tidak benar-benar sebanding apel-dengan-apel. Ekuivalen 2048px yang dipublikasikan Uni-1 sekitar $0.0909 per gambar. Halaman harga model gambar terbaru Google mencantumkan $0.134 per gambar 1K/2K dan $0.24 per gambar 4K untuk pratinjau model gambar Gemini terbarunya, sementara halaman harga GPT Image dari OpenAI mencantumkan harga per gambar $0.011 pada kualitas rendah untuk 1024x1024, $0.042 pada kualitas menengah, dan $0.167 pada kualitas tinggi, dengan keluaran kualitas tinggi yang lebih besar di $0.25. Dengan kata lain, OpenAI bisa jauh lebih murah di level rendah, Google agresif di sisi kecepatan-dan-skala, dan Uni-1 berada di tengah dengan profil harga-kinerja berorientasi 2K yang kuat.
Perbedaan Falsafah
| Model | Pendekatan |
|---|---|
| Uni-1 | Kecerdasan multimodal terpadu |
| GPT Image | LLM + generasi gambar |
| Nano Banana 2 | Difusi produksi yang dioptimalkan |
Tabel Perbandingan Terperinci
| Fitur | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Arsitektur | Autoregressive | Hibrida | Difusi |
| Unifikasi multimodal | ✅ Natif | Parsial | ❌ |
| Kemampuan penalaran | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Kualitas gambar | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Perenderan teks | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Alur kerja pengeditan | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Kecepatan | Sedang | Cepat | Cepat |
| Kendali | Tinggi | Sedang | Sedang |
CometAPI menyediakan gambar mentah interaktif untuk GPT Image 1.5, Nano Banana 2, dan Uni-1 yang akan datang, serta pemrograman API. Harga diskon dan opsi bayar sesuai pemakaian menjadikannya pilihan favorit bagi para developer.
Untuk apa Uni-1 paling cocok
Uni-1 terlihat sangat kuat untuk kasus di mana Anda memerlukan keterulangan, konsistensi karakter, atau kendali multi-referensi. Itu mencakup kampanye brand, mockup produk, konsep editorial, storyboard, varian pelokalan, dan pengeditan gambar di mana komposisi harus tetap utuh tetapi gaya atau lingkungan perlu diubah. Contoh Luma sendiri sangat menekankan kasus penggunaan ini, dan pemisahan “Create vs Modify” model pada dasarnya adalah jawaban langsung atas titik nyeri produksi umum.
Jika pekerjaan Anda sebagian besar “membuat sesuatu yang cantik dari satu prompt,” pembeda mungkin terasa kurang dramatis. Tetapi jika alur kerja Anda adalah “buat lima versi terkait, pertahankan karakter yang sama, jaga framing, ubah pencahayaan, dan buatnya dapat direproduksi minggu depan,” desain Uni-1 mulai masuk akal. Itu merupakan inferensi, tetapi mengalir alami dari fitur kendali yang ditekankan Luma.
Praktik terbaik untuk mendapatkan hasil lebih baik dengan Uni-1
Mulailah dengan menggunakan mode yang tepat. Panduan Luma sederhana: Create saat Anda menginginkan adegan baru, Modify saat Anda ingin mempertahankan yang sudah ada. Mencampur niat tersebut membuat keluaran kurang stabil.
Gunakan label referensi seperti profesional. Luma merekomendasikan frasa seperti “Gunakan IMAGE1 sebagai referensi STYLE” atau “Gunakan IMAGE2 sebagai LIGHTING.” Model bekerja lebih baik saat setiap referensi punya tugas, alih-alih “inspirasi” yang samar.
Kunci seed setelah Anda menemukan sesuatu yang bagus. Luma secara eksplisit merekomendasikan eksplorasi tanpa seed terlebih dahulu, lalu menyimpan seed setelah Anda mendapatkan hasil kuat. Setelah itu, ubah satu variabel pada satu waktu. Itu cara termudah menjadikan generasi sebagai sistem produksi terkontrol.
Jadilah spesifik dan konkret. Luma memperingatkan untuk menghindari kata-kata samar seperti “indah” atau “menakjubkan,” dan menganjurkan estetika bernama seperti “poster film giallo Italia 1970-an” atau isyarat gaya kamera yang tepat. Dalam praktiknya, prompt spesifik biasanya mengalahkan prompt puitis karena model bisa berlabuh pada struktur nyata.
Gunakan rantai Create → Modify. Luma secara eksplisit menyebut ini sebagai salah satu alur kerja terkuatnya: eksplorasi di Create, lalu perbaiki di Modify. Itulah sweet spot untuk pekerjaan produksi serius, karena mengurangi backtracking dan mempertahankan bagian bagus dari komposisi sambil memperketat detail.
Kesimpulan akhir
Uni-1 adalah pernyataan paling jelas Luma sejauh ini bahwa generasi gambar bergerak dari “prompt masuk, gambar keluar” menuju kreasi visual yang dipandu penalaran. Kekuatan publiknya adalah kendali, penanganan referensi, keterulangan, dan arsitektur model yang menjaga bahasa dan piksel dalam satu sistem.
Bagi kreator dan tim yang peduli pada keluaran visual berkualitas tinggi, karakter yang konsisten, pengeditan presisi, dan kejelasan harga resolusi tinggi, Uni-1 sangat layak untuk diamati. Jika peluncuran API berjalan mulus, ini bisa menjadi salah satu alternatif paling menarik untuk Nano Banana 2 dari Google dan GPT Image 1.5 dari OpenAI pada 2026.
Berencana mulai membuat gambar mentah? CometAPI, platform agregasi satu-atap untuk API model multimodal, menyambut Anda!