

Qwen2.5-VL-32B API telah menarik perhatian karena kinerja luar biasa dalam berbagai tugas kompleks, menggabungkan keduanya data gambar dan teks untuk memperkaya pemahaman tentang dunia. Dikembangkan oleh AlibabaModel parameter 32 miliar ini merupakan peningkatan dari model sebelumnya Qwen2.5-VL seri, mendorong batas-batas Penalaran yang digerakkan oleh AI dan pemahaman visual.

Tinjauan Umum Qwen2.5-VL-32B
Qwen2.5-VL-32B adalah model multimoda sumber terbuka yang mutakhir dirancang untuk menangani berbagai tugas yang melibatkan teks dan gambar. Dengan 32 miliar parameter, ia menawarkan a arsitektur yang kuat untuk pengenalan gambar, penalaran matematis, generasi dialog, dan masih banyak lagi. Ini ditingkatkan kemampuan belajar, berdasarkan pembelajaran penguatan, memungkinkannya menghasilkan jawaban yang lebih sesuai dengan preferensi manusia.
Fitur dan Fungsi Utama
Qwen2.5-VL-32B menunjukkan kemampuan luar biasa di berbagai domain:
Pemahaman dan Deskripsi GambarModel ini unggul dalam analisis gambar, mengidentifikasi objek dan pemandangan secara akurat. Ini dapat menghasilkan deskripsi bahasa alami yang terperinci dan bahkan memberikan wawasan terperinci ke dalam atribut objek dan hubungannya.
Penalaran Matematika dan Logika:Model ini dilengkapi untuk memecahkan masalah matematika yang kompleks—mulai dari geometri ke aljabar—dengan menggunakan penalaran multi langkah dengan logika yang jelas dan keluaran yang terstruktur.
Pembuatan Teks dan Dialog: Dengan model bahasanya yang canggih, Qwen2.5-VL-32B menghasilkan respons yang koheren dan relevan secara kontekstual berdasarkan teks atau gambar masukan. Ia juga mendukung dialog multi-putaran, memungkinkan interaksi yang lebih alami dan berkelanjutan.
Jawaban Pertanyaan Visual:Model ini dapat menjawab pertanyaan yang berhubungan dengan konten gambar, seperti pengenalan objek dan deskripsi adegan, menyediakan logika visual dan kemampuan inferensi yang canggih.
Fondasi Teknis Qwen2.5-VL-32B
Untuk memahami kekuatan di balik Qwen2.5-VL-32B, penting untuk mempelajari prinsip-prinsip teknisnya. Berikut ini adalah aspek-aspek utama yang berkontribusi terhadap kinerjanya:
- Pra-Pelatihan Multimoda:Model telah dilatih sebelumnya menggunakan kumpulan data skala besar terdiri dari keduanya data teks dan gambarHal ini memungkinkannya mempelajari beragam fitur visual dan linguistik, sehingga memudahkan pemahaman lintas-moda yang lancar.
- Arsitektur Transformator:Dibangun di atas yang kuat Arsitektur transformator, model ini memanfaatkan kedua faktor tersebut encoder dan decoder struktur untuk memproses masukan gambar dan teks, menghasilkan output yang sangat akurat. mekanisme perhatian diri memungkinkannya untuk fokus pada komponen kritis dalam data masukan, sehingga meningkatkan presisinya.
- Optimasi Pembelajaran Penguatan: Qwen2.5-VL-32B mendapat manfaat dari pembelajaran penguatan, yang disesuaikan berdasarkan umpan balik manusia. Proses ini memastikan respons model lebih selaras dengan preferensi manusia sambil mengoptimalkan beberapa tujuan seperti ketepatan, logika, dan kelancaran.
- Penyelarasan Visual-Bahasa: Melalui pembelajaran kontras dan strategi penyelarasan, model ini memastikan bahwa keduanya fitur visual dan informasi tekstual terintegrasi dengan baik dalam ruang bahasa, membuatnya sangat efektif untuk tugas multimoda.
Highlights kinerja
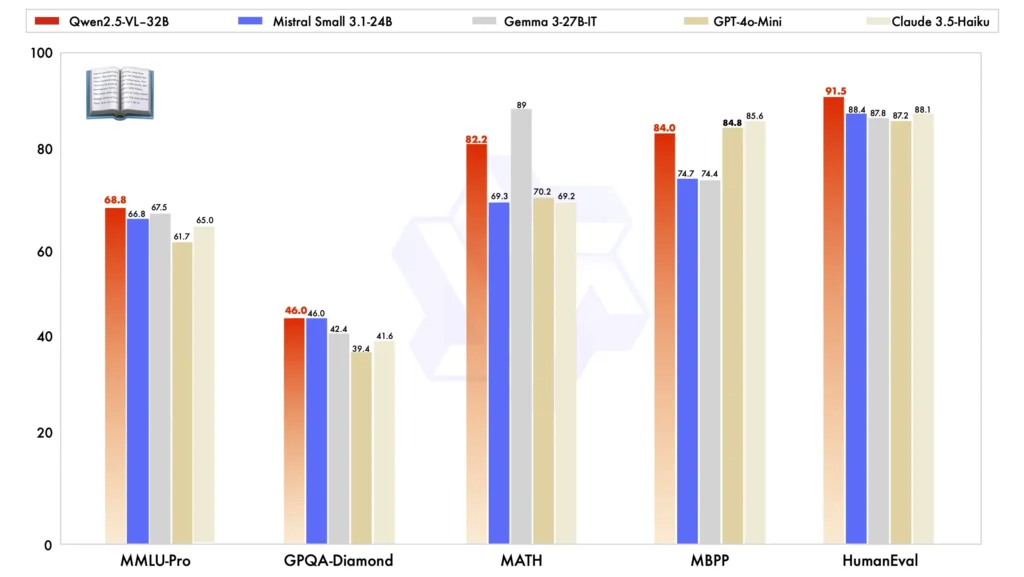
Jika dibandingkan dengan model skala besar lainnya, Qwen2.5-VL-32B menonjol dalam beberapa tolok ukur utama, memamerkan kinerja yang unggul di keduanya multimoda dan tugas teks biasa:
Perbandingan Model:Melawan model lain seperti Mistral-Kecil-3.1-24B dan Gemma-3-27B-ITQwen2.5-VL-32B menunjukkan peningkatan kemampuan yang signifikan. Khususnya, bahkan mengungguli Qwen2-VL-72B yang lebih besar dalam berbagai tugas.
Kinerja Tugas Multimodal: Dalam kompleks tugas multimoda seperti MMMU, MMMU-Pro, dan MatematikaVista, Qwen2.5-VL-32B unggul, memberikan hasil tepat yang membedakannya dari model lain berukuran serupa.
Benchmark MM-MT-Benchmark:Dibandingkan dengan pendahulunya, Qwen2-VL-72B-Instruct, versi baru ini menunjukkan peningkatan yang signifikan, terutama pada alasan logis dan penalaran multimodal kemampuan.
Kinerja Teks Biasa:Dalam tugas berbasis teks biasa, Qwen2.5-VL-32B telah muncul sebagai berkinerja terbaik di kelasnya, menawarkan peningkatan pembuatan teks, pemikiran, dan akurasi keseluruhan.
Sumber Daya Proyek
Bagi pengembang dan penggemar AI yang ingin menjelajahi Qwen2.5-VL-32B lebih jauh, beberapa sumber daya utama tersedia:
- Situs Resmi: Proyek Qwen2.5-VL-32B
- Model Wajah Pelukan: HuggingFace Qwen2.5-VL-32B-Instruksi
Aplikasi Dunia Nyata
Fleksibilitas Qwen2.5-VL-32B membuatnya cocok untuk berbagai macam aplikasi praktis di berbagai industri:
Layanan Pelanggan yang Cerdas:Model ini dapat digunakan untuk menangani pertanyaan pelanggan secara otomatis, memanfaatkan kemampuannya untuk memahami dan menghasilkan tanggapan berbasis teks dan berbasis gambar.
Bantuan Pendidikan:Dengan memecahkan masalah matematika, menafsirkan konten gambar, dan menjelaskan konsep, hal itu dapat meningkatkan proses pembelajaran bagi siswa secara signifikan.
Anotasi Gambar:Dalam sistem manajemen konten, Qwen2.5-VL-32B dapat mengotomatiskan pembuatan keterangan gambar dan deskripsi, menjadikannya alat yang sangat berharga bagi industri media dan kreatif.
Mengemudi otonom:Dengan menganalisis rambu-rambu jalan dan kondisi lalu lintas melalui kemampuan pemrosesan visualnya, model ini dapat memberikan wawasan waktu nyata untuk meningkatkan keamanan berkendara.
Konten Penciptaan:Dalam media dan periklanan, model ini dapat menghasilkan teks berdasarkan rangsangan visual, membantu pembuat konten dalam menghasilkan narasi yang menarik untuk video dan iklan.
Prospek dan Tantangan ke Depan
Meskipun Qwen2.5-VL-32B merupakan lompatan maju dalam AI multimoda, masih ada tantangan dan peluang di depan. Mencari setelan model untuk tugas yang lebih spesifik, mengintegrasikannya dengan aplikasi waktu nyata, dan meningkatkannya Skalabilitas untuk menangani kumpulan data multimoda yang lebih kompleks adalah area yang memerlukan penelitian dan pengembangan berkelanjutan.
Selain itu, karena semakin banyak model AI yang dirilis dengan kemampuan serupa, etika keprihatinan seputar konten yang dihasilkan AI, prasangka, dan privasi data terus menarik perhatian. Memastikan bahwa Qwen2.5-VL-32B dan model serupa dilatih dan digunakan secara bertanggung jawab akan menjadi hal yang penting bagi keberhasilan jangka panjang mereka.
Topik terkait:Perbandingan 8 Model AI Paling Populer Tahun 2025
Kesimpulan
Qwen2.5-VL-32B adalah alat yang ampuh dalam gudang model AI yang dirancang untuk mengatasi tugas multimoda dengan akurasi dan kecanggihan yang mengesankan. Dengan mengintegrasikan teknologi canggih penguatan pembelajaran, arsitektur transformator, dan keselarasan visual-bahasa, itu tidak hanya melampaui model sebelumnya tetapi juga membuka kemungkinan menarik bagi industri mulai dari pendidikan untuk mengemudi mandiriSebagai teknologi sumber terbuka, teknologi ini menawarkan potensi luar biasa bagi pengembang dan pengguna AI untuk bereksperimen, mengoptimalkan, dan menerapkannya dalam aplikasi dunia nyata.
Cara memanggil API Qwen2.5-VL-32B dari CometAPI
1.Masuk untuk cometapi.comJika Anda belum menjadi pengguna kami, silakan mendaftar terlebih dahulu
2.Dapatkan kunci API kredensial akses antarmuka. Klik “Tambahkan Token” pada token API di pusat personal, dapatkan kunci token: sk-xxxxx dan kirimkan.
-
Dapatkan url situs ini: https://api.cometapi.com/
-
Pilih titik akhir Qwen2.5-VL-32B untuk mengirim permintaan API dan atur badan permintaan. Metode permintaan dan badan permintaan diperoleh dari dokumen API situs web kamiSitus web kami juga menyediakan uji coba Apifox demi kenyamanan Anda.
-
Memproses respons API untuk mendapatkan jawaban yang dihasilkan. Setelah mengirim permintaan API, Anda akan menerima objek JSON yang berisi penyelesaian yang dihasilkan.