

Gemini Embedding 2 adalah model embedding pertama Google yang multimodal secara native yang memetakan teks, gambar, audio, video, dan PDF ke dalam satu ruang vektor semantik berdimensi 3.072 (dengan ukuran keluaran yang dapat dikonfigurasi). Model ini memperkenalkan Matryoshka Representation Learning untuk menyediakan embedding bertingkat/terpotong, peningkatan performa multibahasa (100+ bahasa), serta kontrol yang dioptimalkan untuk embedding spesifik tugas (misalnya, task:search, task:code).
Apa itu Gemini Embedding 2?
Gemini Embedding 2 adalah model embedding terpadu dari Google yang memetakan berbagai modalitas input — teks, gambar, audio, video, dan dokumen — ke dalam satu ruang vektor semantik. Setiap embedding (secara default) adalah vektor floating point berdimensi 3.072 yang merepresentasikan makna semantik dari input sehingga item yang secara semantik mirip (terlepas dari modalitasnya) berdekatan di ruang vektor. Kemampuan utama meliputi:
- Cakupan bahasa dan format yang luas: satu model yang menerima teks, gambar, audio, video, dan dokumen, lalu menempatkannya dalam satu ruang vektor semantik. Gemini Embedding 2 terdokumentasi mampu menangkap maksud semantik lintas 100+ bahasa dan menerima format file umum (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), dengan batas konkret per permintaan (misalnya hingga beberapa gambar atau puluhan detik audio/video per permintaan — lihat “Cara menggunakan” di bawah).
- Multimodal sejati: satu model yang menerima teks, gambar, audio, video, dan dokumen, lalu menempatkannya dalam satu ruang vektor semantik sehingga Anda dapat membandingkan atau melakukan retrieval lintas modalitas (misalnya, teks → gambar, audio → teks).
- Dimensionalitas default besar dengan pemangkasan fleksibel: model ini menghasilkan vektor berdimensi 3072 secara default, namun menggunakan Matryoshka Representation Learning (MRL) untuk memusatkan konten semantik terpenting pada dimensi awal sehingga Anda dapat memangkas ke 1536, 768 (atau lebih rendah) dengan penurunan kualitas retrieval yang moderat. Ini mengurangi trade-off biaya penyimpanan dan komputasi.
Mengapa ini penting. Secara historis, embedding kebanyakan hanya mendukung teks atau memerlukan encoder terpisah per modalitas dengan lapisan penyelarasan lintas-modal yang kompleks. Gemini Embedding 2 menghilangkan hambatan itu dengan mendukung banyak format secara native — sehingga kueri teks dapat melakukan retrieval gambar atau klip pendek berdasarkan kemiripan semantik tanpa transkripsi perantara atau pemetaan manual. Ini menyederhanakan RAG (retrieval-augmented generation), penelusuran semantik, dan pipeline retrieval multimodal.
Fitur & kapabilitas utama (apa yang baru)
1. Multimodal native sejati (satu ruang embedding)
Satu model yang menerima teks, gambar, audio, video, dan dokumen serta menempatkannya dalam satu ruang vektor semantik. Gemini Embedding 2 memetakan teks, gambar, audio, video, dan dokumen ke dalam ruang embedding yang sama sehingga retrieval lintas modal (teks→gambar, audio→teks) berjalan langsung tanpa penyelarasan lintas-model. Ini mengurangi kompleksitas pipeline dan menyederhanakan stack RAG (Retrieval-Augmented Generation).
2. Vektor default 3.072 dimensi dengan keluaran yang dapat disesuaikan
Gemini Embedding 2 menghasilkan vektor berdimensi 3072 secara default, namun menggunakan Matryoshka Representation Learning (MRL) untuk memusatkan konten semantik terpenting pada dimensi awal sehingga Anda dapat memangkas ke 1536, 768 (atau lebih rendah) dengan penurunan kualitas retrieval yang moderat. Ini mengurangi trade-off biaya penyimpanan dan komputasi.
3. Matryoshka Representation Learning (MRL)
MRL menghasilkan embedding “bersarang” — seperti boneka sarang Rusia — sehingga potongan berdimensi lebih rendah tetap mempertahankan semantik tingkat lebih tinggi. Ini memungkinkan sistem memilih titik operasi (kompromi penyimpanan/akurasi) tanpa harus mempertahankan beberapa model embedding terpisah. Analisis blog awal dan dokumentasi menggambarkan teknik ini sebagai inovasi inti untuk fleksibilitas.
4. Petunjuk tugas / tujuan embedding yang disesuaikan
API menerima petunjuk task (misalnya, task:search, task:code retrieval, task:semantic-similarity) sehingga model dapat mengoptimalkan geometri embedding untuk relasi hilir tertentu — mirip dengan conditioning tugas pada sistem embedding sebelumnya tetapi diperluas ke input multimodal.
5. Luasnya bahasa dan modalitas
Gemini Embedding 2 terdokumentasi mampu menangkap maksud semantik lintas 100+ bahasa dan menerima format file umum (PNG/JPEG, MP4/MOV, MP3/WAV, PDF), dengan batas konkret per permintaan (misalnya hingga beberapa gambar atau puluhan detik audio/video per permintaan — lihat “Cara menggunakan” di bawah).
Tolok ukur performa
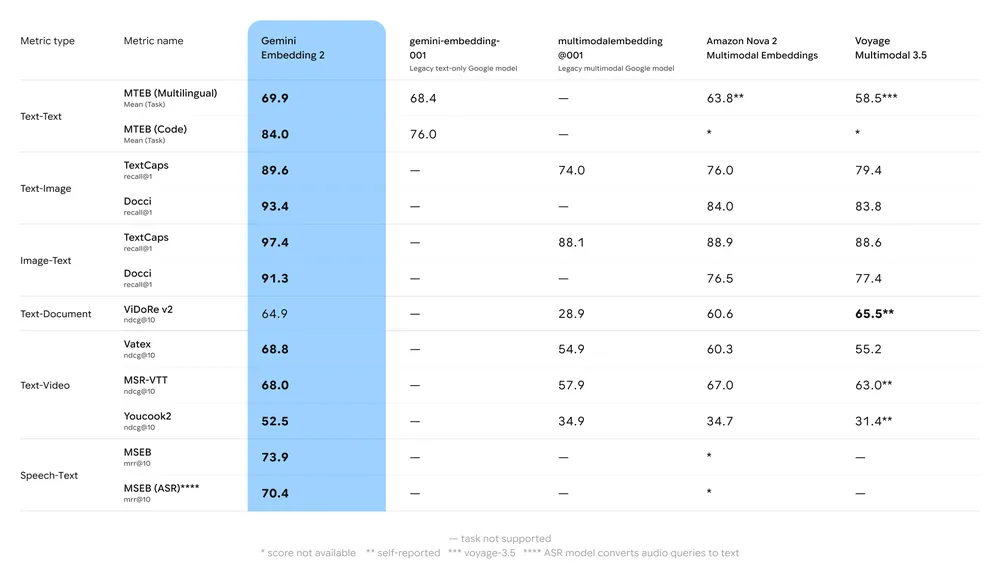
Ringkasan tolok ukur utama:
- MTEB (Massive Text Embedding Benchmark): Dilaporkan menempati posisi kuat pada papan peringkat MTEB multibahasa untuk tugas bahasa Inggris dan multibahasa; analisis menunjukkan peningkatan bermakna dibandingkan model embedding Gemini sebelumnya dan banyak alternatif proprietari.
- Retrieval multimodal: Melampaui atau menyamai embedding single-modal terkemuka saat digunakan untuk kemiripan lintas modal (misalnya, retrieval teks→gambar), berkat pelatihan multimodal native.
- Latensi & throughput: Pembuatan embedding yang di-host di cloud, tetapi use case yang sensitif terhadap latensi mungkin lebih memilih vektor terpotong atau model embedding ringan alternatif untuk kebutuhan on-edge.
Gemini Embedding 2 vs gemini-embedding-001 dan text-embedding-3-large
| Atribut | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Rilis / ketersediaan | Mar 10, 2026 — pratinjau publik (Gemini API / Vertex AI). | Gemini embedding sebelumnya (varian hanya teks) — GA lebih dulu. | Diumumkan Jan 2024 (hanya teks GA). |
| Modalitas yang didukung | Teks, gambar, audio, video, dokumen (PDF) — ruang vektor terpadu. | Teks (utama). | Hanya teks (multibahasa berkualitas tinggi). |
| Dimensi embedding default | 3072 (MRL / pemangkasan direkomendasikan: 1536, 768). | 3072 (untuk versi besar) — hanya teks. | 3072 (text-embedding-3-large). |
| MTEB yang dilaporkan (contoh) | Tinggi-60an pada MTEB; menunjukkan 68,17 pada 1536 di tabel vendor (lihat doks). | gemini-embedding-001 dilaporkan ~68,32 rata-rata di beberapa papan peringkat. | ~64,6 (rata-rata MTEB yang dilaporkan oleh OpenAI untuk text-embedding-3-large). |
| Dukungan audio/video native | Ya (embedding audio/video langsung). | Tidak (hanya teks). | Tidak (hanya teks). |
| Use case umum | Retrieval multimodal, RAG, penelusuran semantik lintas jenis file, retrieval ucapan, pencarian video. | Retrieval teks, RAG multibahasa. | Retrieval teks, penelusuran semantik, RAG — performa teks multibahasa kuat. |
Spesifikasi teknis & batasan
Ukuran embedding default & dapat disesuaikan
- Default: 3.072 dimensi.
- Dapat disesuaikan: parameter
output_dimensionalitymemungkinkan permintaan keluaran berdimensi lebih rendah untuk menghemat penyimpanan/CPU. Use case dengan gudang vektor masif sering menurunkan dimensi ke 512–1.024 demi biaya, dengan menerima trade-off akurasi tertentu.
Modalitas yang didukung dan batas per permintaan
- Gambar: PNG, JPEG — hingga 6 gambar per permintaan (batas yang dilaporkan vendor).
- Video: MP4, MOV — vendor melaporkan hingga ~128 detik per video untuk embedding satu permintaan.
- Audio: MP3, WAV — vendor melaporkan hingga ~80 detik per input audio.
- Dokumen: PDF — hingga 6 halaman per permintaan (pelaporan vendor).
- Batas token untuk konten tekstual: model mendukung input token besar; terdapat batas token praktis per permintaan (cek dokumen API dan kuota Vertex AI).
Ketersediaan & akses
- Pratinjau publik: Gemini Embedding 2 dirilis sebagai pratinjau publik dan tersedia melalui Gemini API dan Google Cloud Vertex AI untuk penggunaan eksperimental segera
Pertanyaan yang sering diajukan (FAQ)
Q1: Modalitas apa yang didukung Gemini Embedding 2?
A: Teks, gambar (PNG/JPEG), video (MP4/MOV), audio (MP3/WAV), dan dokumen PDF — semua dipetakan ke ruang vektor semantik yang sama.
Q2: Berapa ukuran vektor default untuk Gemini Embedding 2?
A: Defaultnya 3.072 dimensi. Anda dapat meminta keluaran berdimensi lebih kecil melalui API.
Q3: Apakah Gemini Embedding 2 sudah tersedia sekarang?
A: Ya — diumumkan sebagai pratinjau publik dan tersedia melalui Gemini API dan Vertex AI (cek model id gemini-embedding-2-preview dan changelog terkini).
Q4: Bagaimana perbandingannya dengan embedding dari penyedia lain?
A: Uji vendor independen melaporkan Gemini Embedding 2 berada di antara model proprietari teratas untuk teks multibahasa dan menunjukkan performa state-of-the-art untuk beberapa tugas multimodal. Peringkat tepat bervariasi menurut tugas dan dataset; uji pada data Anda sendiri.
Q5: Apakah saya perlu melakukan transkripsi audio untuk menggunakan Gemini Embedding 2?
A: Tidak — Gemini Embedding 2 dapat menerima audio secara langsung dan menghasilkan embedding tanpa terlebih dulu mentranskripsikannya ke teks, sehingga memungkinkan retrieval semantik audio end-to-end.
Q6: Bagaimana cara menurunkan biaya penyimpanan untuk vektor 3.072 dimensi?
A: Opsi termasuk meminta output_dimensionality yang lebih rendah, menggunakan float16/quantization/PQ, dan menyimpan representasi terkompresi di DB vektor. Postingan vendor menyediakan alur kerja dan praktik terbaik.
Apa selanjutnya — apakah saya harus mengadopsinya sekarang?
Gemini Embedding 2 adalah langkah besar dalam menyatukan retrieval multimodal dan menyederhanakan arsitektur yang sebelumnya memerlukan retriever terpisah untuk teks, visi, dan ucapan. Poin keputusan utama untuk adopsi:
- Adopsi lebih cepat jika produk Anda membutuhkan retrieval lintas modal yang andal (teks↔gambar/video/audio), atau jika mempertahankan beberapa retriever single-modal mahal dan kompleks.
- Uji coba sekarang jika Anda ingin mengevaluasi pemangkasan MRL dan mengukur biaya vs. kualitas (pertahankan deployment hibrida: 1536 sebagai utama, 3072 untuk re-ranking).
- Tunggu jika beban kerja Anda sangat sensitif terhadap biaya dan hanya membutuhkan retrieval teks — model khusus teks teratas (misalnya, OpenAI text-embedding-3-large) tetap kompetitif dan terkadang lebih murah tergantung pipeline dan kontrak Anda.
Developer dapat mengakses Gemini Embedding 2 dan OpenAI text-embedding-3 API melalui CometAPI sekarang. Untuk memulai, jelajahi kapabilitas model di Playground dan lihat Panduan API untuk instruksi terperinci. Sebelum mengakses, pastikan Anda sudah login ke CometAPI dan memperoleh kunci API. CometAPI menawarkan harga jauh lebih rendah daripada harga resmi untuk membantu integrasi Anda.
Siap Mulai?→ Daftar cometapi hari ini !
Jika Anda ingin mengetahui lebih banyak tips, panduan, dan berita tentang AI, ikuti kami di VK, X, dan Discord!