

Alibaba Wan2.7-Image, rilasciato il 1 aprile 2026, segna un grande balzo nella generazione visiva AI. Questo modello unificato integra creazione da testo a immagine, editing interattivo, composizione multi-immagine e comprensione semantica in un’unica architettura. A differenza delle pipeline tradizionali separate per generazione ed editing, elimina incoerenze come “volti AI standardizzati”, testo illeggibile e colori imprevedibili.
Creatori, designer, marketer e aziende ottengono ora risultati fotorealistici e perfettamente allineati alle istruzioni con meno iterazioni. Il modello supporta fino a 12 immagini sequenziali, 9 fusioni di riferimento, rendering di testo in 12 lingue (fino a 3,000 token) e controllo a livello di pixel.
Che cos’è Wan2.7-Image?
Wan2.7-Image è il modello di immagini unificato di punta del Tongyi Lab di Alibaba all’interno della serie Wan (Tongyi Wanxiang). Gestisce flussi visivi end-to-end: generazione da testo a immagine, trasformazione da immagine a immagine, editing basato su comandi e rifiniture interattive a livello di pixel—tutto in un unico spazio latente condiviso.
Rilasciato il 1 aprile 2026, si basa sui precedenti modelli video Wan 2.x (che hanno primeggiato nei benchmark VBench) spostando l’attenzione sulla precisione delle immagini. Affronta direttamente la “stanchezza estetica” dovuta a volti ripetitivi, colori instabili e scarsa aderenza ai prompt, comune nei vecchi strumenti AI. La famiglia di modelli include due nomi che contano di più per gli utenti: wan2.7-image e wan2.7-image-pro. La versione standard è ottimizzata per la maggiore velocità di generazione, mentre la versione Pro punta a un output professionale, con supporto 4K ad alta definizione.
Elemento distintivo chiave: architettura unificata. I modelli tradizionali usano stadi disconnessi (encoder → diffusion → decoder), richiedendo l’inpainting separato per le modifiche. Wan2.7-Image mappa la semantica direttamente in uno spazio condiviso, abilitando una vera comprensione anziché un semplice riconoscimento di pattern di pixel.
Perché Wan2.7-Image è importante (contesto di settore)
Gli strumenti di immagini AI tradizionali soffrono di:
| Problema | Spiegazione |
|---|---|
| Workflow frammentato | Strumenti separati per generazione, editing, inpainting |
| “Sindrome del volto AI” | Volti umani ripetitivi e poco realistici |
| Debole allineamento alle istruzioni | I prompt non vengono seguiti con precisione |
| Scarsa resa del testo | Testo distorto o illeggibile |
| Output multi-immagine incoerente | I personaggi cambiano tra i frame |
Wan2.7-Image affronta direttamente queste limitazioni con una architettura unificata + livello di comprensione semantica.
5 funzionalità chiave di Wan2.7-Image
1. Personalizzazione degli avatar a livello osseo per volti davvero unici
Wan2.7-Image eccelle nel “un volto unico per ogni individuo”. Supporta un controllo fine sulla struttura ossea, la forma degli occhi (a mandorla, “fenice”, incavati, gonfi, sorridenti), i contorni del viso e i dettagli sottili. Questo elimina il problema del “volto AI standardizzato” che affliggeva i modelli precedenti.

Prompt di esempio: “Photorealistic portrait of a 28-year-old East Asian woman, oval face, almond-shaped eyes, subtle smile, detailed skin texture, natural lighting.” I risultati mostrano una diversità realistica, ideale per influencer virtuali, NPC di giochi o branding personalizzato.
2. Controllo preciso della palette colori
Una delle funzionalità più pratiche è il nuovo controllo della palette colori. Alibaba afferma che gli utenti possono inserire codici colore specifici e proporzioni per replicare stili artistici o bloccare i colori del brand. La documentazione API formalizza questo con un parametro color_palette che accetta da 3 a 10 colori, con 8 consigliati. Per i team brand, questa è una delle funzionalità più chiaramente orientate all’impresa del rilascio. Niente più variazioni casuali di colore—coerenza perfetta tra campagne.
Citazione ufficiale: “Say goodbye to random color generation. Achieve precise color ratios and bring your creative vision to life.” — Tongyi Wanxiang.
3. Rendering avanzato di testo multilingue (12 lingue, 3,000 token)
Renderizza testi ultra-lunghi, tabelle, formule, grafici e infografiche con nitidezza da stampa (equivalente A4). Supporta cinese, inglese, giapponese, coreano e altre 8 lingue. Articoli accademici, poster, etichette di prodotto e banner multilingue raggiungono una leggibilità quasi perfetta—risolvendo una storica debolezza dell’AI.
4. Editing interattivo a precisione di pixel con selezione a marquee
Usa riquadri di selezione (editRegions) o strumenti marquee per modifiche mirate. Carica fino a 9 riferimenti e impartisci istruzioni come “cambia lo sfondo con un tramonto in spiaggia preservando volto, posa e abbigliamento”. L’accuratezza a livello di pixel garantisce la preservazione dell’identità.
5. Generazione compositiva multi-immagine (fino a 12 immagini sequenziali)
Il modello è progettato per andare oltre la generazione a singolo prompt. Alibaba afferma che gli utenti possono lavorare con fino a nove immagini di riferimento e generare fino a 12 immagini contemporaneamente, ideale per storyboard coerenti, architettura e serie e-commerce. Il flusso “click-to-edit” consente di selezionare aree specifiche e apportare modifiche con accuratezza a livello di pixel, e la documentazione API aggiunge editing interattivo di precisione tramite un parametro di bounding box per modifiche locali.
Come funziona Wan2.7-Image? (Approfondimento tecnico)
Alibaba descrive Wan2.7-Image come un framework che collega linguaggio e immagini addestrandosi su dataset ampi e diversificati. In parole semplici, il modello non impara solo a “disegnare” immagini; impara anche come i prompt si mappano su struttura visiva, composizione, illuminazione e posizionamento del testo. Questo è ciò che consente al modello di interpretare l’intento dell’utente in modo più accurato rispetto a un semplice sistema testo-immagine.
L’API mostra anche che il modello è costruito per input multimodali. In pratica, le richieste sono inviate tramite una struttura di messaggi a turno singolo, e il contenuto può includere sia elementi di testo sia immagini. Per l’editing, gli utenti possono fornire più immagini più istruzioni come “sposta”, “sostituisci” o “miscela” per guidare il risultato. È un chiaro segno che Wan2.7 è progettato come sistema prompt+reference piuttosto che come semplice generatore one-shot.
I documenti espongono anche un’impostazione di thinking mode. È abilitata per impostazione predefinita e può migliorare la qualità dell’output, ma Alibaba nota che aumenta i tempi di generazione. È un indizio utile sul workflow del modello: output di qualità superiore possono richiedere più tempo di inferenza interno, soprattutto quando la richiesta è ricca di testo o visivamente complessa.
Wan2.7-Image impiega un framework unificato di generazione-editing in uno spazio latente condiviso:
- Fase di input: Prompt testuale (fino a 3,000 token) + immagini di riferimento opzionali (fino a 9).
- Parsing semantico e Thinking Mode (potenziato nel Pro): un ragionamento a catena analizza composizione, relazioni spaziali, illuminazione e logica prima della generazione dei pixel.
- Mappatura nello spazio latente condiviso: La semantica si mappa direttamente sulle caratteristiche visive—senza gap disconnessi encoder/decoder.
- Inferenza unificata: Generazione o editing avviene in un flusso unico ottimizzato. Le aree di modifica usano bounding box; le palette colori impongono le proporzioni.
- Output: Immagini ad alta fedeltà (768–2048×2048 standard; 4K nel Pro), con opzioni JPG/PNG/WEBP, seed per la riproducibilità e controlli di sicurezza.
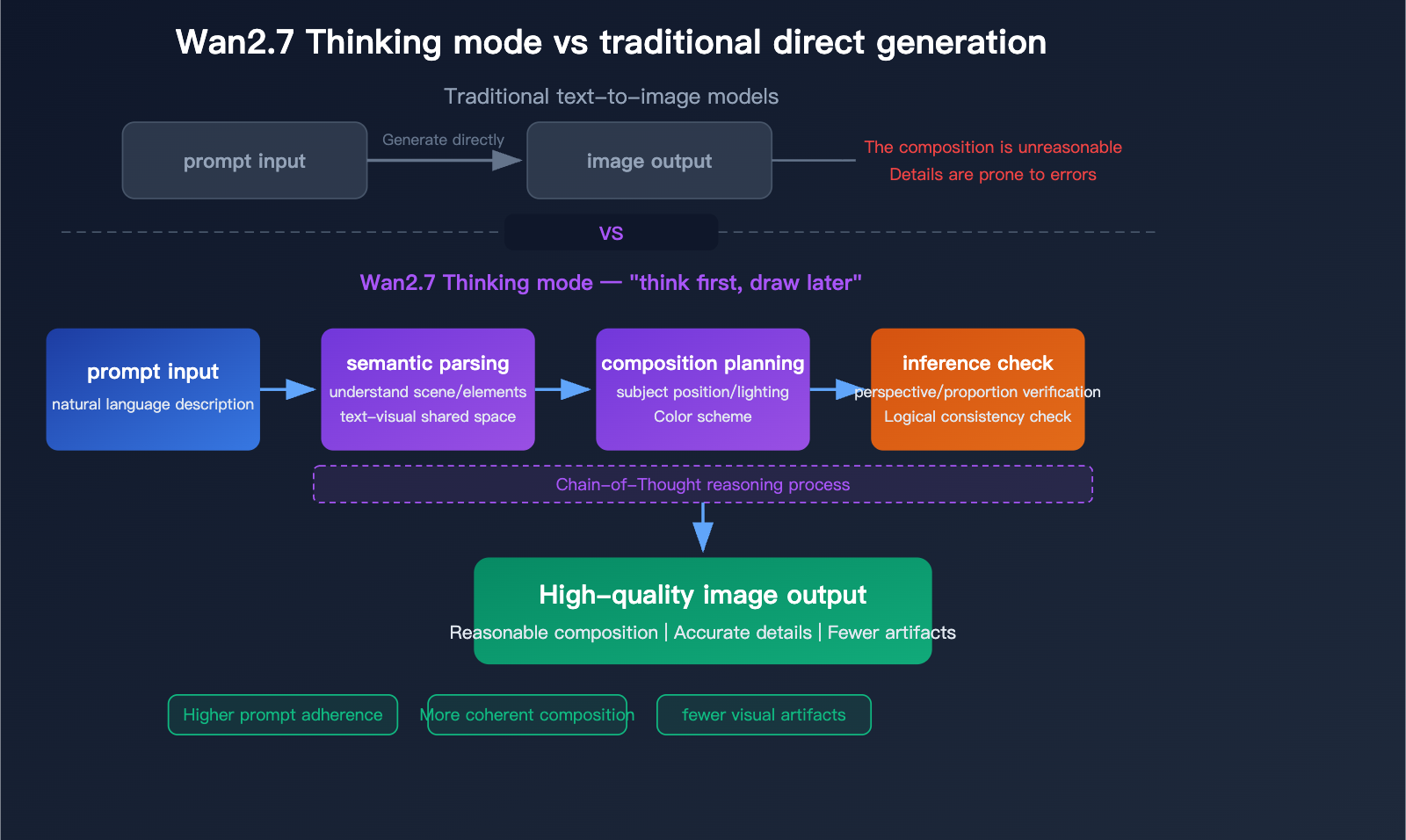
Analisi approfondita di Wan2.7-Image-Pro: un nuovo benchmark per la generazione di immagini AI con qualità 4K, modalità di ragionamento e rendering di testo in 12 lingue - Apiyi.com Blog
Il diagramma di flusso della thinking mode (Pro) mostra parsing semantico → pianificazione della composizione → verifica dell’inferenza, producendo meno artefatti e maggiore aderenza ai prompt rispetto alla generazione diretta.
L’addestramento su dataset diversificati abilita una comprensione profonda di intento, illuminazione e layout. L’apprendimento a lungo contesto (citato in studi su arXiv) alimenta la gestione estesa del testo.
Wan2.7-Image vs Wan2.7-Image-Pro: differenze principali
Entrambe le versioni vengono lanciate simultaneamente, ma Pro è pensata per esigenze professionali.
| Funzionalità | Wan2.7-Image (Standard) | Wan2.7-Image-Pro | Ideale per |
|---|---|---|---|
| Risoluzione max | 2048×2048 | 4096×4096 (4K) | Stampa/produzione (Pro) |
| Thinking Mode | Disponibile (predefinita più rapida) | Potenziata/predefinita con ragionamento più profondo | Scene complesse (Pro) |
| Stabilità compositiva | Forte | Comprensione semantica superiore | Progetti commerciali (Pro) |
| Velocità vs qualità | Iterazione più rapida | Maggiore fedeltà, tempo leggermente superiore | Prototipazione (Standard) |
| Caso d’uso | Creatori generici, contenuti social | Design enterprise, ambito accademico/stampa | Scalabilità vs precisione |
La Standard è adatta alla prototipazione rapida; la Pro offre 4K pronto per la stampa con coerenza superiore.
Come usare Wan2.7-Image (passo per passo)
1. Accedi alla piattaforma
Disponibile tramite:
- Alibaba Cloud (piattaforma BaiLian)
- Strumenti ufficiali Wanxiang
- CometAPI
2. Scegli la modalità di workflow
Modalità A: Text-to-Image
Esempio di prompt:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Modalità B: Image Editing
- Carica un’immagine
- Seleziona un’area
- Inserisci l’istruzione
Esempio:
Replace background with a futuristic city
Modalità C: Composizione multi-immagine
- Carica più riferimenti
- Definisci le regole di composizione
3. Affina i parametri
- Palette colori
- Consistenza dello stile
- Rendering del testo
4. Esporta l’output
- Immagini ad alta risoluzione
- Asset pronti per uso commerciale
Prestazioni ai benchmark e confronto con i concorrenti
Nei test in cieco di preferenza umana, Wan2.7-Image supera GPT-Image-1.5 nella qualità testo-immagine e eguaglia o supera Nano Banana Pro nel rendering del testo, fotorealismo e conoscenza del mondo.
Tabella di confronto:
| Modello | Rendering del testo | Aderenza alle istruzioni | Personalizzazione avatar | Riferimenti multi-immagine | Gen/Edit unificati | Risoluzione | Open-source/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Eccellente (12 lingue) | Superiore (Thinking Mode) | A livello osseo | 9 | Sì | 2K–4K | Sì/API |
| Midjourney V8 | Buono | Moderata | Artistica forte | Limitati | No | Alta | Solo Discord |
| FLUX | Buono | Forte (semplice) | Buona | Limitati | No | Alta | Sì |
| DALL-E 3 | Moderata | Buona | Moderata | No | No | 2K | API |
| Nano Banana Pro | Forte | Editing forte | Buona | Forte | Parziale | Alta | Chiuso |
Wan2.7-Image guida nel workflow unificato, testo multilingue e controllo preciso—particolarmente prezioso per i mercati non anglofoni e le pipeline professionali.
CometAPI è una piattaforma di aggregazione all-in-one per API di grandi modelli, che offre integrazione e gestione senza soluzione di continuità dei servizi API. Supporta più API di generazione di immagini, come GPT-image-1.5, serie Nano Banana, Midjourney e Qwen Image Series ecc., a un prezzo inferiore rispetto al sito ufficiale.
Chi dovrebbe usare Wan2.7-Image
Wan2.7-Image è particolarmente rilevante per i team che necessitano di velocità e flessibilità più che di una singola generazione artistica. Ciò include performance marketer, product designer, studi e-commerce, team social e agenzie che producono molte varianti a partire dallo stesso brief. Il supporto del modello per input multi-immagine, generazione multi-output ed editing basato su istruzioni lo rende particolarmente attraente per workflow in cui contano coerenza, velocità e controllo del prompt.
Casi d’uso reali
- Gaming/Intrattenimento: Genera 100 NPC unici in pochi minuti.
- Marketing/E-commerce: Carousel coerenti col brand con palette colori esatte.
- Istruzione/Accademia: Poster pronti per la stampa con formule e tabelle.
- Agenzie di design: Storyboard e revisioni cliente via editing interattivo.
I guadagni di produttività derivano da meno iterazioni e integrazione fluida dei riferimenti.
Conclusione:
Alibaba Wan2.7-Image ridefinisce la creatività AI unificando generazione, editing e comprensione. Le sue 5 funzionalità chiave, lo spazio latente condiviso e i miglioramenti Pro offrono risultati professionali che i concorrenti faticano ancora a eguagliare. Che si tratti di prototipare contenuti social o produrre visual accademici pronti per la stampa, offre precisione ed efficienza senza pari.
Inizia oggi su wan.video o via API su CometAPI. Per sviluppatori e aziende, la combinazione di potenza, accessibilità e superiorità supportata dai dati rende Wan2.7-Image il leader indiscusso dei modelli di immagini AI unificati per il 2026 e oltre.