

La serie Claude di Anthropic è diventata una pietra miliare nel panorama in rapida evoluzione dei modelli linguistici di grandi dimensioni, in particolare per aziende e sviluppatori alla ricerca di funzionalità di intelligenza artificiale all'avanguardia. Con il rilascio di Claude Opus 4.1 il 5 agosto 2025, Anthropic offre un aggiornamento incrementale ma di grande impatto rispetto al suo predecessore, Claude Opus 4 (rilasciato il 22 maggio 2025). Questo articolo esamina le principali differenze tra Opus 4.1 e Opus 4.0 in termini di prestazioni, architettura, sicurezza e applicabilità nel mondo reale, basandosi su annunci ufficiali, benchmark indipendenti e feedback del settore.
Claude Opus 4.1 è ora disponibile tramite API (ID modello claude-opus-4-1-20250805), Amazon Bedrock, Vertex AI di Google Cloud e nelle interfacce Claude a pagamento. Come aggiornamento incrementale, mantiene la piena compatibilità con Opus 4: stessi prezzi, stessi endpoint e tutte le integrazioni esistenti continuano a funzionare senza modifiche.
Cos'è Claude Opus 4.0 e perché è importante?
Claude Opus 4.0 ha segnato un balzo in avanti sostanziale nella ricerca di Anthropic di "intelligenza di frontiera", combinando ragionamento robusto, gestione estesa del contesto e solide competenze di programmazione in un unico modello. Ha raggiunto:
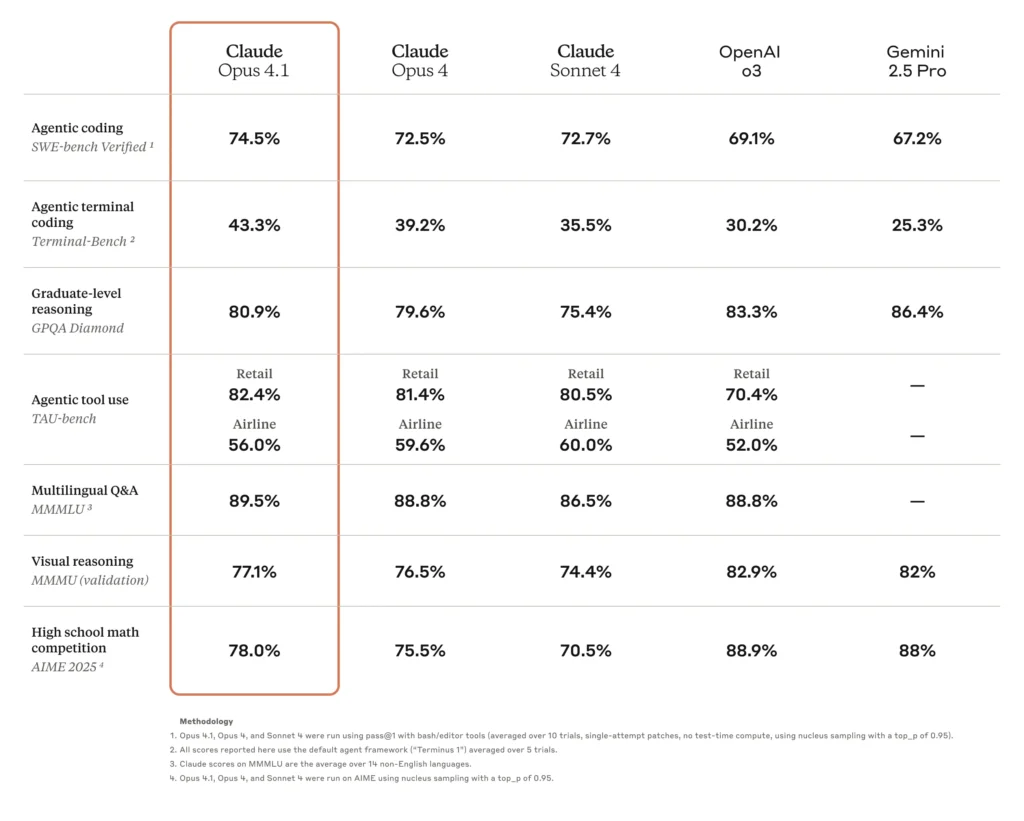
- Elevata precisione di codifica: Opus 4.0 ha ottenuto un punteggio del 72.5% su SWE-bench Verified, un benchmark per le sfide di codifica del mondo reale, dimostrando una significativa applicabilità nel mondo reale alle attività di sviluppo software.
- Capacità agentiche avanzate: Il modello eccelleva nell'esecuzione di attività autonome in più fasi, consentendo ad agenti di intelligenza artificiale sofisticati di gestire flussi di lavoro, dall'orchestrazione del marketing all'assistenza alla ricerca.
- Capacità creativa e analitica:Oltre alla codifica, Opus 4.0 ha offerto prestazioni all'avanguardia nella scrittura creativa, nell'analisi dei dati e nel ragionamento complesso, rendendolo uno strumento versatile per i settori sia aziendali che tecnici.
La combinazione di ampiezza e profondità di Opus 4.0 ha fissato un nuovo standard per l'intelligenza artificiale aziendale, favorendone una rapida adozione nei piani Claude Pro, Max, Team ed Enterprise, nonché l'integrazione in Amazon Bedrock e Vertex AI di Google Cloud.
Quali sono le novità di Claude Opus 4.1?
Miglioramenti di riferimento nelle attività di codifica
Uno degli aggiornamenti principali di Opus 4.1 è la maggiore accuratezza della codifica. Nel test SWE-bench Verified, Opus 4.1 ottiene i seguenti punteggi: 74.5%, in aumento rispetto al 4.0% di Opus 72.5. Questo guadagno di 2 punti, sebbene apparentemente modesto, equivale a riduzioni significative nei cicli di debug e a una maggiore precisione nella sintesi e nel refactoring del codice.
In che modo i compiti agentici sono più affidabili?
Opus 4.1 offre capacità di ragionamento a lungo termine più avanzate, consentendo agli agenti di intelligenza artificiale di supportare processi complessi e articolati in più fasi con maggiore coerenza. Secondo AWS, il modello ora funge da "collaboratore virtuale ideale" per attività che richiedono catene di pensiero estese, come la gestione autonoma delle campagne e l'orchestrazione di flussi di lavoro interfunzionali.
Precisione del refactoring multi-file
Una delle caratteristiche più distintive di Opus 4.1 è il suo approccio conservativo alle modifiche al codice su larga scala. Laddove Opus 4.0 talvolta introduceva modifiche non necessarie su file interconnessi, Opus 4.1 eccelle nell'isolare le modifiche minime necessarie, individuando le correzioni esatte senza modifiche collaterali.
Come si confrontano nei benchmark chiave?
Benchmark di codifica
| Modello | SWE-bench verificato (%) | Punteggio di refactoring multi-file |
|---|---|---|
| Opus 4.0 | 72.5 | Linea di base |
| Opus 4.1 | 74.5 | guadagno +1.2 σ |
Fonte: scheda di sistema Anthropic e benchmark indipendenti
Ricerca e ricerca agentica
Opus 4.1 mostra un 15% Miglioramento delle valutazioni agentiche TAU-bench, che riflette una migliore conservazione del contesto e una maggiore iniziativa nelle attività di ricerca. Gli utenti segnalano una convergenza più rapida sulle informazioni rilevanti e riepiloghi multi-documento più coerenti.
I confronti di benchmark sulle attività di "ricerca agentica" mostrano che Opus 4.1 ottiene punteggi più elevati in termini di pianificazione, utilizzo degli strumenti e risoluzione dinamica dei problemi. La valutazione interna della ricerca agentica di Anthropic indica un miglioramento del 5-7% nell'accuratezza del ragionamento multi-step rispetto a Opus 4.0, consentendo un'esecuzione più affidabile di flussi di lavoro come pipeline di analisi dati automatizzate e generazione di report di ricerca. Questi progressi derivano in parte dalla migliore tracciabilità del ragionamento intermedio, una funzionalità che garantisce agli utenti finali una migliore visibilità sui percorsi decisionali del modello.
Quali attività di codifica specifiche registrano i maggiori miglioramenti?
- Refactoring multi-file: Opus 4.1 mostra una maggiore coerenza durante l'attraversamento di moduli interdipendenti, riducendo gli errori tra file di oltre il 15% nei test interni.
- Localizzazione e riparazione di bug: Il modello identifica in modo più affidabile la causa principale dei casi di test falliti, riducendo del 25% il tempo medio di risoluzione.
- Generazione di documentazione: La fluidità migliorata del linguaggio naturale supporta docstring API e commenti in linea più completi e contestuali.
In che modo Opus 4.1 gestisce le attività multi-step?
- Euristica di pianificazione migliorata, riducendo dell'10% gli errori di pianificazione nelle catene di attività da 8 fasi.
- Integrazione avanzata dell'uso degli strumenti, consentendo chiamate API più precise con meno errori di formato.
- Suggerimenti per il ragionamento provvisorio, consentendo agli sviluppatori di verificare e adattare il ragionamento interno del modello in "punti di controllo" regolabili.
Metriche di conformità alle istruzioni
Le valutazioni a singolo turno mostrano che Opus 4.1 ha raggiunto un tasso di risposta innocua del 98.76% sulle richieste in violazione, in aumento rispetto al 97.27% di Opus 4.0, indicando un rifiuto più forte dei contenuti proibiti (). I tassi di rifiuto eccessivo sulle query innocue rimangono relativamente bassi (0.08% contro 0.05%), garantendo che il modello mantenga la reattività quando appropriato.
Quali miglioramenti sono stati introdotti in termini di sicurezza e allineamento?
Miglioramenti nella valutazione a turno singolo
Gli audit di sicurezza abbreviati di Anthropic per Opus 4.1 hanno confermato prestazioni costanti o migliorate nei parametri di riferimento relativi a sicurezza dei minori, pregiudizi e allineamento. Ad esempio, i tassi di risposta innocua nell'ambito del pensiero esteso sono aumentati dal 97.67% al 99.06%.
Bias e robustezza
Nel benchmark BBQ Bias, il punteggio di bias disambiguato di Opus 4.1 si attesta a -0.51 contro -0.60 di Opus 4.0, con un'accuratezza superiore al 90% per le query disambiguate e quasi perfetta per quelle ambigue. Questi scostamenti marginali indicano una neutralità sostenuta e un'elevata fedeltà in contesti sensibili.
Cosa sta alla base degli aggiornamenti architettonici?
Ottimizzazione del modello e aggiornamenti dei dati
Il team di Anthropic ha implementato protocolli di messa a punto raffinati incentrati su:
- Corpora di codice espansi: Incorporazione di più repository multi-file annotati.
- Scenari agentici aumentati: Curare catene di attività più lunghe durante la formazione per potenziare il ragionamento a lungo termine.
- Cicli di feedback umano migliorati: Sfruttare l'apprendimento tramite rinforzo mirato dal feedback umano (RLHF) su prompt di casi limite per attenuare le allucinazioni.
Queste modifiche producono guadagni misurabili senza alterare l'architettura principale di Transformer, garantendo la compatibilità immediata con le API Anthropic esistenti.
Infrastruttura e latenza
Mentre la latenza dell'inferenza grezza rimane paragonabile a Opus 4.0, Anthropic ha ottimizzato la sua infrastruttura di servizio per ridurre i tempi di avvio a freddo 12%, migliorando la reattività per applicazioni interattive come le integrazioni Claude Chat e Copilot.
Quali sono le implicazioni per gli sviluppatori e le imprese?
Prezzi e disponibilità
Claude Opus 4.1 è offerto al stesso prezzo come Opus 4.0 su tutti i canali (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Non sono richieste modifiche al codice per l'aggiornamento: gli utenti devono semplicemente selezionare "Opus 4.1" nel selettore del modello.
Espansione dei casi d'uso
- Ingegneria software: Debug più rapido, generazione di test più accurata, integrazione migliorata della pipeline CI/CD.
- Agenti AI: Flussi di lavoro autonomi più affidabili nel marketing, nella finanza e nella ricerca.
- Intelligenza aziendale: Riepilogo migliorato, generazione di report e analisi approfondite per un processo decisionale basato sui dati.
Questi aggiornamenti si traducono in una riduzione dei costi di sviluppo e in un ROI più elevato per le iniziative basate sull'intelligenza artificiale.
Cosa riserva il futuro a Claude Opus?
Anthropic segnala che Opus 4.1 è solo un passo di una roadmap più ampia. Il team anticipa "miglioramenti sostanzialmente più ampi" nelle prossime versioni, probabilmente mirati a:
- Finestre di contesto ancora più lunghe (oltre 200K token).
- Capacità multimodali per la comprensione integrata di immagini, audio e codice.
- Maggiore interpretabilità strumenti per tracciare i percorsi decisionali durante le azioni agentiche.
Le aziende e gli sviluppatori dovrebbero monitorare i canali di Anthropic per gli aggiornamenti, poiché ogni aggiornamento incrementale consolida la posizione di Claude tra gli assistenti AI più capaci e sicuri disponibili.
Iniziamo
CometaAPI è una piattaforma API unificata che aggrega oltre 500 modelli di intelligenza artificiale provenienti dai principali fornitori.Claude Opus 4.1 è effettivamente accessibile tramite CometAPI. Elenchi CometAPI anthropic/claude-opus-4.1 tra i modelli supportati, in modo da poter indirizzare le richieste tramite l'API di CometAPI, sono disponibili anche modelli specifici per il codice cursore.
Per iniziare, esplora le capacità del modello in Parco giochi e consultare il Claude Opus 4.1 per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API.
URL di base: https://api.cometapi.com/v1/chat/completions
Parametro del modello:
"claude-opus-4-1-20250805"→ standard Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 con ragionamento esteso abilitatocometapi-opus-4-1-20250805→Esclusiva CometAPI. Versione standard progettata specificamente per cursore integrazionecometapi-opus-4-1-20250805-thinking→ Esclusiva CometAPI. Versione di ragionamento estesa specificatamente per cursore integrazione
In sintesiClaude Opus 4.1 si basa sui punti di forza di Opus 4.0 offrendo miglioramenti mirati in termini di accuratezza della codifica, ragionamento agentico e prestazioni dell'infrastruttura, senza aumentare i costi o alterare i percorsi di integrazione. Che si tratti di perfezionare basi di codice complesse, orchestrare flussi di lavoro di agenti autonomi o generare insight aziendali di alta qualità, Opus 4.1 offre un aggiornamento interessante che bilancia precisione e versatilità. Con la continua accelerazione del panorama dell'intelligenza artificiale, la cadenza costante dei miglioramenti di Anthropic posiziona Claude Opus come la scelta ideale per le organizzazioni che mirano a sfruttare le funzionalità all'avanguardia dei modelli linguistici.