
.png&w=3840&q=75)
GPT-5.4 Mini e GPT-5.4 Nano sono le nuove varianti compatte della famiglia di frontiera GPT-5.4 di OpenAI: Mini punta al miglior compromesso prestazioni/latenza per coding, attività multimodali su UI e carichi di lavoro per sottoagenti; Nano punta a costi e latenza ultra-bassi per classificazione, estrazione, ranking e sottoagenti massicciamente paralleli. Mini offre un’accuratezza quasi da frontiera su molti benchmark per sviluppatori, pur eseguendo a una velocità >2× rispetto ai precedenti “mini”; Nano è significativamente più economico per token ed è ideale dove throughput e reattività contano di più. Questi modelli sono disponibili nell’API (GPT 5.4 Mini e Nano sono disponibili su CometAPI).
Che cosa sono GPT-5.4 Mini e GPT-5.4 Nano?
Definizione breve: GPT-5.4 Mini e GPT-5.4 Nano sono varianti compatte e ingegnerizzate della famiglia GPT-5.4, progettate per portare i punti di forza del grande GPT-5.4 (ragionamento, coding, percezione multimodale, uso di strumenti) in modelli più veloci e a costo inferiore, destinati a carichi di lavoro ad alto volume e bassa latenza. I modelli sono stati annunciati da OpenAI nell’ambito del lancio di GPT-5.4.
- GPT-5.4 Mini — Un modello piccolo ad alte prestazioni che “si avvicina alle prestazioni di GPT-5.4 in diverse valutazioni” pur essendo ottimizzato per velocità e costi inferiori. È messo in evidenza specificamente per coding, ragionamento, interpretazione di UI multimodali (screenshot) e come sottoagente in sistemi agentici. OpenAI riporta che funziona a oltre 2× la velocità dei precedenti varianti “mini”.
- GPT-5.4 Nano — La variante GPT-5.4 più piccola ed economica; raccomandata per classificazione, estrazione, ranking e sottoagenti “di supporto” che gestiscono compiti ristretti e ripetitivi ad altissimo throughput. Sacrifica un ragionamento più profondo in favore di latenza e risparmi sui costi.
Disponibilità e prezzo
OpenAI fornisce due punti di riferimento concreti per confrontare i costi:
- Prezzo input API di GPT-5.4 (flagship completo): $2.50 / 1M token (e prezzo output più alto sul flagship).
- Prezzo input API di GPT-5.4 mini: $0.75 / 1M token e output $4.50 / 1M token.
- Prezzo input API di GPT-5.4 nano: $0.20 / 1M e output $1.25 / 1M.
Affiancando i dati: il prezzo per token di input del mini (0,75) è il 30% del flagship (2,50), quindi circa un terzo del costo di input; il prezzo di output del mini (4,50) è circa il 32% di un prezzo di output del flagship riportato nella tabella prezzi API, ossia circa un terzo. Nano è ancora più economico: il suo costo di input è circa l’8% del costo di input del flagship, e il costo di output è inferiore al 10% di quello di output del flagship. È aumentato il prezzo del token nano da $0.05 a $0.20, e il prezzo del token mini da $0.25 a $0.75 (per i token di input).
Nella piattaforma OpenAI
GPT-5.4 mini è disponibile in tre luoghi: l’API di OpenAI, Codex (la piattaforma IDE/app per sviluppatori di OpenAI) e ChatGPT (disponibile per utenti Free e Go tramite l’opzione “Thinking” e come fallback per il rate limit per i piani a pagamento). Nell’API supporta input testo e immagini, uso di strumenti (function calling), ricerca web/file, uso del computer e skill — e offre una finestra di contesto molto ampia (400k token) per workflow con molti documenti e più screenshot. Il prezzo per l’API è $0.75 per 1M token di input e $4.50 per 1M token di output.
GPT-5.4 nano è disponibile solo tramite API. I prezzi di listino sono $0.20 per 1M token di input e $1.25 per 1M token di output — posizionandolo come l’opzione a costo più basso nella famiglia GPT-5.4. Il modello nano scambia capacità per costi e velocità.
Su piattaforme di terze parti
CometAPI è una piattaforma di aggregazione multimodale di API di IA che ha lanciato ora la GPT 5.4 Series API, inclusi GPT 5.4 Mini e GPT 5.4 Nano, con uno sconto del 20% rispetto al prezzo OpenAI.
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
Caratteristiche principali e novità
Di seguito le funzionalità di punta — perché ingegneri e team di prodotto dovrebbero interessarsene.
Codifica e supporto al lungo contesto
Finestra di contesto: GPT-5.4 mini supporta una finestra di contesto da 400k token (OpenAI indica esplicitamente il mini con un contesto da 400k). È abbastanza grande per codebase multi-file, documenti estesi o sessioni di agenti multi-turn in cui il contesto è importante. Il contesto di Nano è più piccolo rispetto al GPT-5.4 completo, ma comunque consistente per compiti brevi e veloci.
Ragionamento
Livelli di ragionamento: OpenAI espone il parametro reasoning_effort configurabile (none → xhigh); mini e nano possono operare con sforzi variabili ma mini riduce il gap con il GPT-5.4 completo su molti benchmark di ragionamento con sforzo più alto. Su diversi benchmark di intelligenza (ad es., GPQA Diamond), mini raggiunge un punteggio 88,0% contro 93,0% di GPT-5.4, e nano registra 82,8%, indicando un ragionamento rispettabile per un modello piccolo. Questi sono i risultati pubblicati da OpenAI nel post di lancio.
Comprensione multimodale (visione e UI)
Percezione visiva e attività UI: GPT-5.4 mini mostra prestazioni multimodali molto forti per compiti su UI (screenshot, immagini di documenti densi). Su OSWorld-Verified (un benchmark di uso del computer), mini ottiene 72,1%, molto vicino ai 75,0% di GPT-5.4 e ben al di sopra dei mini precedenti — motivo per cui mini è indirizzato a automazioni basate su screenshot e assistenti multimodali reattivi. Nano performa peggio sui benchmark visivi ma è comunque utile per compiti di immagini più semplici.
Invocazione di strumenti e uso del computer
Funzionalità native di strumenti/click: GPT-5.4 introduce ed estende tool nativi per l’uso del computer; mini eredita la capacità di chiamare strumenti, effettuare function call, interpretare screenshot e orchestrare sottoagenti. I benchmark di chiamata agli strumenti (Toolathlon, MCP Atlas) mostrano punteggi rispettabili per mini e nano (Toolathlon: mini 42,9%, nano 35,5%) — quantificando la loro capacità di chiamare e coordinare strumenti esterni. Queste metriche provengono dall’annuncio di OpenAI.
Allucinazioni / aderenza ai fatti / tassi di errore
OpenAI riporta che GPT-5.4 è il “modello più fattuale di sempre” e mostra riduzioni delle allucinazioni rispetto a GPT-5.2; mini e nano mostrano un’aderenza ai fatti assoluta inferiore rispetto al modello completo (ad es., HLE w/ tools: GPT-5.4 52,1%, mini 41,5%, nano 37,7%), il che suggerisce una maggiore necessità di verifica quando i modelli più piccoli vengono utilizzati in compiti ad alta factualità. Usare la verifica basata su strumenti (tool call, richiamo di citazioni) quando la correttezza è importante.
Velocità
OpenAI riporta che GPT-5.4 mini è più di 2× più veloce del precedente GPT-5 mini su stime di latenza tipiche di produzione (basate su comportamenti di produzione simulati che includono durate delle chiamate agli strumenti e token campionati). Questo aumento di velocità è un elemento centrale della nuova famiglia ed è ciò che consente a mini di essere usato come sottoagente reattivo all’interno di app interattive come gli assistenti di coding.
Come si comportano mini e nano — “si avvicinano” al GPT-5.4 completo?
OpenAI ha pubblicato un set completo di confronti benchmark su coding, uso degli strumenti, compiti multimodali di uso del computer, test di intelligenza e valutazioni a lungo contesto. I numeri principali (sforzo di ragionamento xhigh dove applicabile) includono:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | Note |
|---|---|---|---|---|---|
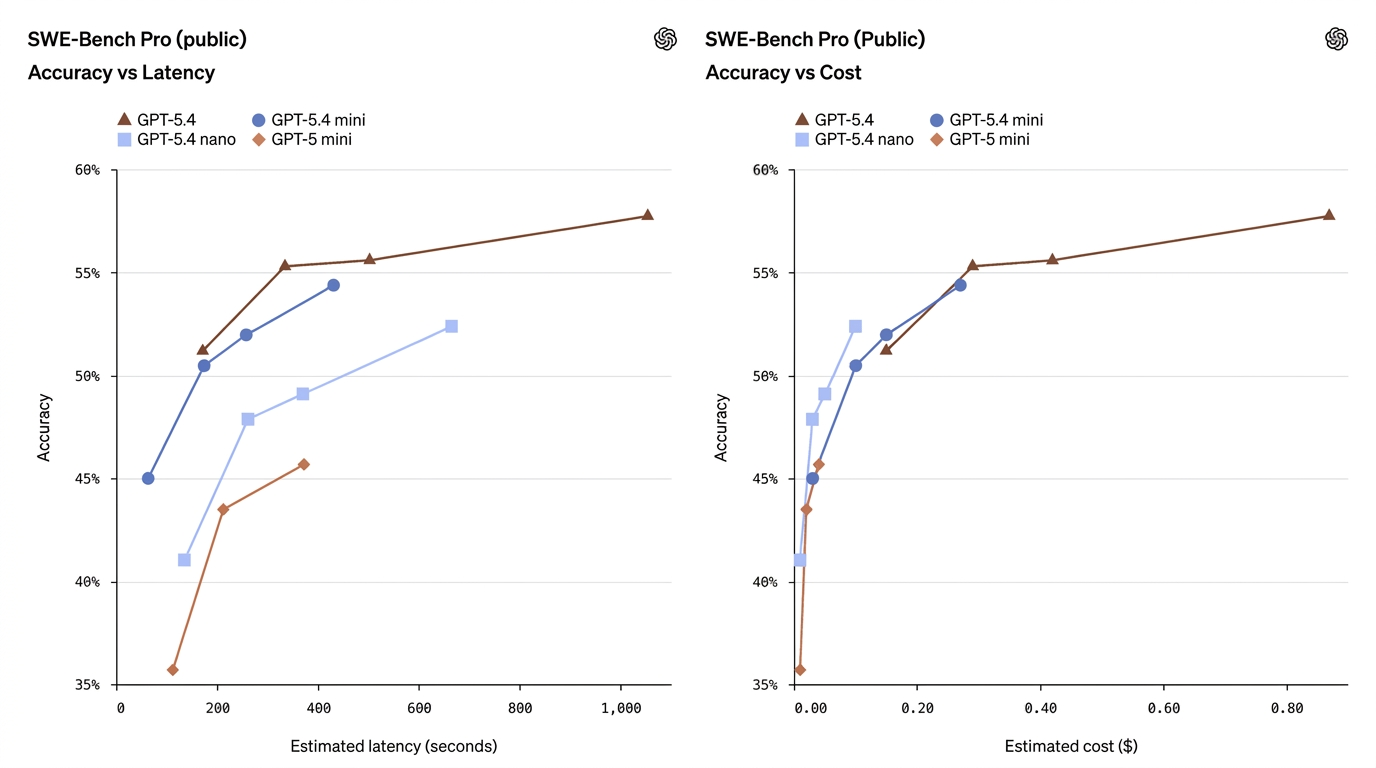
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini si avvicina alle prestazioni di coding del modello completo |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Ottima capacità di coding in tempo reale per Mini |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | Misura orchestrazione e chiamate agli strumenti |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | Benchmark di intelligenza e ragionamento |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | Capacità di UI/uso del computer |
Questi numeri mostrano che spesso mini riduce considerevolmente il divario — soprattutto su compiti di coding e uso del computer — mentre nano occupa una via di mezzo utile tra capacità e costo.
Cosa significano i numeri in parole semplici?
- GPT-5.4 Mini ≈ “quasi flagship” in molti compiti di produzione. Su SWE-Bench Pro (una metrica di pass-rate nel coding), mini ottiene 54,4% contro 57,7% del flagship — un piccolo divario relativo per molti compiti di coding reali, in particolare quando la latenza è importante. Su OSWorld (uso del computer), mini è al 72,1% rispetto al 75,0% del flagship — di nuovo, molto vicino per compiti su UI/screenshot.
- GPT-5.4 Nano scambia più capacità per velocità/costo. Il punteggio di coding di Nano (52,4% su SWE-Bench Pro) è rispettabile rispetto ai vecchi mini, ma il suo punteggio OSWorld scende a 39,0%, mostrando che per compiti che richiedono una comprensione UI multi-step complessa o sequenze agentiche di strumenti, nano è meno adatto. Nano brilla in classificazione one-shot, estrazione e piccoli compiti di supporto.
- L’uso degli strumenti migliora, ma resta sensibile. Le metriche Toolathlon e altre relative all’uso degli strumenti aumentano sostanzialmente passando da GPT-5 mini a GPT-5.4 mini/nano, mostrando che l’ingegnerizzazione di OpenAI ha migliorato l’affidabilità dell’invocazione degli strumenti nei modelli più compatti — ma il modello completo è ancora in testa nell’orchestrazione di strumenti complessi.
Come funzionano in produzione
Compressione, distillazione e ottimizzazioni ingegneristiche
Modelli compatti come mini/nano tipicamente usano una combinazione di distillazione del modello, quantizzazione e potatura architetturale per preservare capacità ad alto valore (euristiche di coding, percetti visivi) riducendo il compute d’inferenza. Il wording di OpenAI indica un’ingegnerizzazione mirata a preservare skill specifiche (coding, comprensione di UI multimodali) in footprint più piccoli.
Pattern consigliati
- Pattern orchestratore + sottoagente: Usa GPT-5.4 (grande) come planner/judge e smista il lavoro a sottoagenti GPT-5.4 mini / nano per esecuzione rapida (ricerca, parsing, editing). Questo riduce il costo totale e la latenza per l’utente. OpenAI avalla esplicitamente questo pattern.
- Fallback e gestione del rate limit: Esporre mini come fallback per il rate limit in ChatGPT o Codex in modo che le query sensibili al tempo ricevano comunque una risposta capace quando il modello completo non è disponibile.
- Architettura a livelli per il controllo dei costi: Pipeline bulk (indicizzazione, estrazione) → GPT-5.4 nano; componenti UI interattivi → GPT-5.4 mini; giudizio editoriale finale / catene complesse → GPT-5.4 completo. Questo approccio multi-tier bilancia costo e capacità.
Latenza e parallelizzazione
Mini e nano sono ottimizzati per sottoagenti paralleli, dove molti piccoli worker eseguono in contemporanea — ad es., analisi in parallelo di migliaia di PDF. Il concetto di OpenAI di “tool yields” misura come le chiamate agli strumenti in parallelo riducano la latenza wall-clock; mini/nano sono ingegnerizzati per rendere questi pattern convenienti.
Come usare mini e nano in pratica
Devo sostituire ovunque le chiamate al flagship con mini/nano?
Non automaticamente. Il pattern corretto che OpenAI raccomanda esplicitamente è la delegazione: usa un modello più grande per pianificazione, giudizio complesso o verifica finale, e smista molti sotto-compiti di supporto, più brevi, a sottoagenti mini o nano. Questo pattern riduce costi e latenza mantenendo i guardrail del modello più grande dove contano di più. Casi d’uso:
- Assistenti di coding interattivi: il flagship pianifica e revisiona; mini gestisce ricerca rapida nel codice, modifiche ed unit test brevi.
- Agenti “uso del computer” guidati da screenshot: mini può analizzare interfacce dense rapidamente; il flagship risolve pianificazioni multi-step ambigue.
- Pipeline ad alto volume per estrazione e classificazione: nano elabora input massivi in batch (moduli, log) e restituisce risultati strutturati; il flagship gestisce eccezioni e casi limite complessi.
Mini o nano possono essere usati per compiti multimodali o di immagini?
Sì — mini supporta input immagine e performa bene su benchmark multimodali/vision-driven (MMMUPro/OmniDocBench), avvicinandosi al flagship in alcuni test. La forza multimodale di nano è più limitata: pur migliorando rispetto ai nano precedenti, non è la scelta migliore per ragionamento multimodale profondo o compiti agentici basati su immagini.
La corsa alle capacità dei modelli piccoli si è intensificata
Tre mesi fa, i modelli piccoli erano considerati “abbastanza buoni”. Ora, GPT-5.4 mini si sta avvicinando ai modelli di punta sui benchmark di programmazione e li eguaglia quasi in prestazioni computazionali.
La tendenza è chiara: le capacità dei modelli di punta vengono rapidamente trasferite ai modelli più piccoli. OpenAI, Google e Anthropic stanno facendo la stessa cosa: distillare le capacità fondamentali dei grandi modelli in versioni più piccole, più veloci e più economiche.
Conclusione
Il rilascio di questi due modelli segna un cambiamento nelle applicazioni di IA: dalla focalizzazione sulla scala a quella sull’efficienza pratica. Grazie a capacità di risposta rapida, forniscono un supporto sottostante più affidabile per l’interazione AI in tempo reale e la scomposizione di flussi di compiti complessi.
Per gli sviluppatori, questo significa che la struttura dei costi dei sistemi agentici viene ridefinita. Quando i costi scendono a questo livello, molti scenari agentici che prima erano “teoricamente fattibili ma economicamente infattibili” diventano praticabili.
Gli sviluppatori possono accedere ora a GPT 5.4 Mini e a GPT-5.4 Nano tramite CometAPI (CometAPI è una piattaforma di aggregazione one-stop per API di grandi modelli come GPT APIs, Nano Banana APIs etc). Prima di accedere, assicurati di aver effettuato il login a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto inferiore a quello ufficiale per aiutarti a integrare.
Pronti a partire?