

xAI rilasciato silenziosamente Grok4.1 (17-18 novembre 2025) — un aggiornamento mirato a Grok 4 che dà priorità intelligenza emotiva, espressione creativa e riduzione delle allucinazioni pur mantenendo la logica tagliente delle precedenti versioni di Grok. Disponibile in due modalità (Riflessione/Non-Riflessione), è stato lanciato silenziosamente all'inizio di novembre, mostra i risultati migliori in classifica su LMArena ed è disponibile tramite grok.com, le app Grok e l'API.
Cos'è Grok 4.1?
Grok 4.1 è il successore incrementale e focalizzato sulla produzione di Grok 4: un membro della famiglia costruito sulla stessa base di apprendimento per rinforzo su larga scala, ma perfezionato e riqualificato con significative ottimizzazioni post-addestramento mirate a stile, personalità, allineamento e affidabilità nel mondo reale. Si posiziona come un passo avanti pragmatico e "utilizzabile": più intelligente nei test di preferenza umana in cieco, più emotivamente intelligente, migliore nella scrittura creativa e significativamente meno incline al tipo di "allucinazioni" sicure ma sbagliate che hanno tormentato i precedenti LLM ad alte prestazioni.
Grok 4.1 realizza cambiamenti qualitativi nelle seguenti quattro dimensioni:
- Creatività: dimostra uno stile linguistico più forte e immaginazione nella scrittura, nella narrazione e nei contesti sociali;
- Intelligenza emotiva: riconosce il tono e i cambiamenti emotivi, rispondendo con una logica emotiva più simile a quella umana e generando risposte confortanti e comprensive;
- Coerenza della personalità: mantiene un tono e una personalità coerenti nelle conversazioni lunghe, senza più mostrare il comportamento incoerente dei modelli precedenti;
- Collaborativo: mantiene la coerenza e la consapevolezza degli obiettivi nei dialoghi multi-turni o nella collaborazione sui compiti.
xAI riassume le sue caratteristiche in una frase: "È più percettivo, più empatico e più simile a una persona coerente".
Come funziona Grok 4.1 sotto il cofano?
Grok 4.1 è meglio compreso come lo stesso backbone pre-addestrato utilizzato nella famiglia Grok 4 più una pipeline di post-addestramento a strati che si concentra su modellazione della ricompensa, allineamento dello stile e valutatori agenti.
Quali sono le fasi di formazione e allineamento?
Grok 4.1 funziona su una pipeline multistadio tipica dei moderni LLM di frontiera, adattata con due importanti cambiamenti per la versione 4.1:
- Pre-allenamento + metà allenamento: Pre-addestramento di un ampio corpus su dati web + addestramento intermedio mirato per potenziare la conoscenza del dominio e le capacità multimodali.
- Fine-tuning supervisionato (SFT): Dimostrazioni umane di comportamenti desiderati (risposte, strategie di rifiuto).
- Modellazione della ricompensa (nuova applicazione): I modelli di ricompensa addestrati da xAI non solo si basano sulle etichette delle preferenze umane, ma sono anche utilizzati modelli di ragionamento agentico di frontiera come valutatori di ricompensa, consentendo di fatto a valutatori ad alta capacità basati su modelli di valutare i risultati dei candidati su larga scala. Ciò ha consentito l'ottimizzazione di attributi non verificabili come stile, coesione della personalità, empatia e disponibilità senza richiedere un budget per l'etichettatura umana incredibilmente elevato.
- Ottimizzazione delle policy (RLHF / RL da ricompense modello): Ottimizzazione della politica standard utilizzando i segnali di ricompensa appresi per produrre la politica implementata (il modello con cui interagiscono i consumatori).
Quali sono le novità nell'approccio alla modellazione delle ricompense?
Nel RLHF tradizionale si raccolgono le etichette di preferenza umana (A/B), si addestra un modello di ricompensa per predire tali etichette e quindi si ottimizza il modello di base con RL (o campionamento di rifiuto) rispetto alla ricompensa appresa. Ma xAI evidenzia due innovazioni pratiche:
- Modelli di ricompensa agentica: Invece di giudici puramente umani, xAI ha utilizzato modelli di ragionamento "agentici" capaci come valutatori per valutare proprietà più sottili (tono, sfumature emotive, creatività). I valutatori possono eseguire rapidamente migliaia di confronti a coppie, consentendo agli ingegneri di iterare più velocemente. Questo è il meccanismo per importanti miglioramenti nello stile e nell'intelligenza emotiva.
- Allineamento post-addestramento per segnali non verificabili: per gli attributi che non è possibile misurare con una metrica deterministica (ad esempio, "calore" o "personalità coerente") hanno introdotto obiettivi di ricompensa specializzati e programmi di studio di scalabilità in modo che il modello impari stile di output senza sacrificare l'accuratezza fattuale fondamentale.
Come funziona tecnicamente il concetto di "pensare" e "non pensare"?
- Grok 4.1 Thinking (nome in codice
quasarflux) — espone passaggi di ragionamento espliciti (token di pensiero) prima di produrre la risposta finale; ottimizzato per compiti complessi e punteggi Elo più elevati in LMArena. I token aggiuntivi richiedono tempo di inferenza, ma aiutano con attività di ragionamento multi-step, debug e spiegabilità. - Grok 4.1 Non-pensiero (nome in codice
tensor) bypassa i token intermedi espliciti per una singola risposta finale immediata. Ciò riduce la latenza e il costo dei token, pur beneficiando degli stessi pesi delle policy raffinati. La modalità non-thinking è stata ottimizzata per offrire una latenza estremamente bassa e comunque altamente efficiente.
Ottimizzazione dell'allineamento di sentimento e stile
Oltre ai semplici segnali di "veridicità", Grok 4.1 include un'ottimizzazione mirata dell'allineamento per sentiment, tono e stile interpersonale. Ciò significa che la pipeline di addestramento include componenti di ricompensa o perdita che puniscono esplicitamente un tono non corrispondente (ad esempio, essere inutilmente bruschi quando l'empatia è appropriata) e premiano le risposte che corrispondono a uno stile o a un profilo di sentiment desiderati. In Grok 4.1, l'intelligenza artificiale ha introdotto per la prima volta l'obiettivo di ottimizzazione dell'"Allineamento della Personalità".
L'obiettivo è aiutare il modello a mantenere un senso di identità coerente e stabile. Rispetto a Grok 4, 4.1 aggiunge i seguenti obiettivi formativi:
- Ricompense positive per la dimensione dell'espressione emotiva (ricompensa dell'allineamento emotivo);
- Una metrica di coerenza della personalità.
Come è stato valutato Grok 4.1 e quali sono state le sue prestazioni?
Cosa hanno dimostrato i test sulle preferenze umane in cieco?
Durante un lancio silenzioso, Grok 4.1 è stato preferito nel 64.78% dei casi rispetto al precedente modello di produzione nel traffico live: un forte segnale di preferenza umana che indica risultati conversazionali migliori in natura.
Grok 4.1 è in cima alle classifiche?
xAI segnala che Grok 4.1 Pensiero la modalità si trova a #1 su Text Arena di LMArena, con un Elo segnalato di 1483e la sua modalità non ragionata (veloce) si classifica al 2° posto con 1465 Elo, un ottimo piazzamento nella classifica pubblica sia per accuratezza che per presentazione (il controllo dello stile gioca un ruolo).
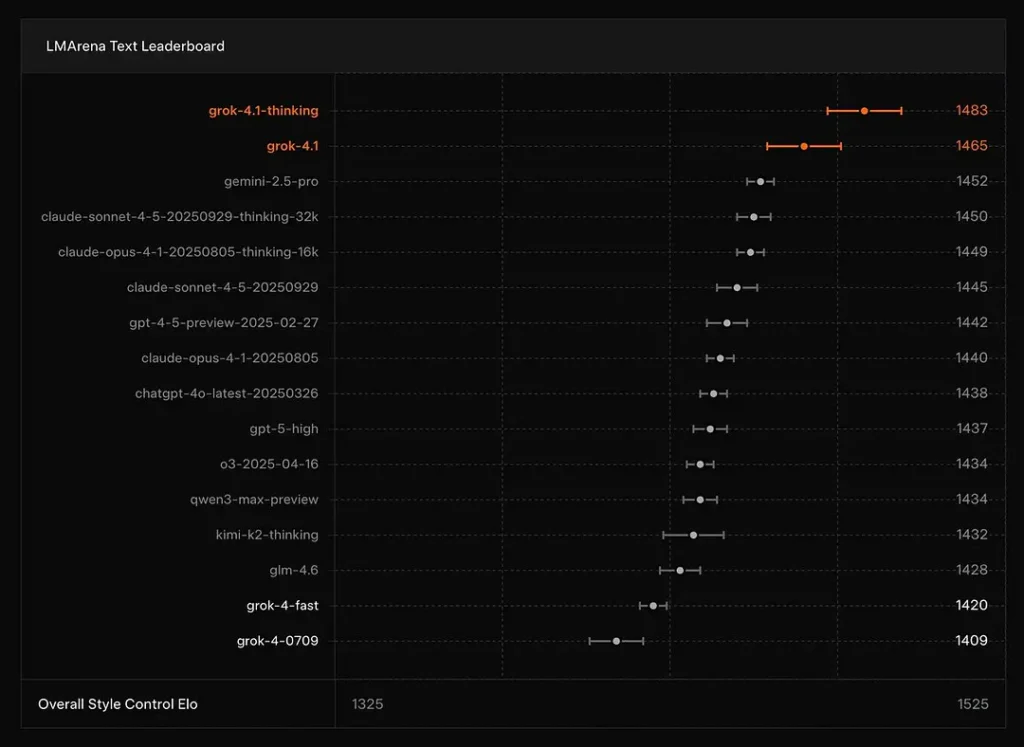
Conclusione: Grok 4.1 supera i modelli tradizionali GPT-4.5 e Claude in termini di comprensione del testo, generazione e qualità complessiva, secondo solo alla versione GPT-5 Advanced Preview.
Intelligenza Emotiva
xAI ha eseguito EQ-Bench3, un test specializzato per l'intelligenza emotiva che copre 45 scenari di gioco di ruolo impegnativi, e ha riferito che Grok 4.1 mostra notevoli miglioramenti in termini di empatia, ritmo e intuizione interpersonale. Grok 4.1 ha ottenuto il punteggio più alto nella comprensione di contesti di tristezza, empatia e conforto.

Scrittura creativa: è davvero più fantasiosa?
Grok 4.1 è stato valutato su Scrittura creativa v3 (32 prompt in 3 iterazioni con punteggio Elo + rubrica). xAI afferma che lo stile di scrittura, la coerenza vocale e la creatività narrativa della versione 4.1 sono migliorati notevolmente, posizionandola in cima alle recenti classifiche per le attività creative (il comunicato include esempi di prompt). I report indipendenti hanno rispecchiato questi risultati: i revisori hanno notato una "voce distintiva" notevolmente maggiore e una migliore coerenza nella forma estesa. In termini di qualità di scrittura, Grok 4.1 è secondo solo ai modelli della serie GPT-5 e supera l'intera gamma di prodotti Claude, Gemini e Kimi.

Riduzione delle allucinazioni/onestà
xAI afferma una notevole riduzione dei tassi di allucinazioni: hanno riferito (nell'annuncio e nei post sui social) che Grok 4.1 è ~3 volte meno probabilità di avere allucinazioni Rispetto ai precedenti modelli Grok, che citavano analisi del traffico di produzione e valutazioni in stile FActScore (ad esempio, set di domande bio/biografia, un punteggio più basso è meglio). Soprattutto nella "modalità non ragionata", dove sono disponibili strumenti di ricerca esterni, la coerenza dei fatti è più stabile.

Perché Grok 4.1 “sconfigge” gli altri modelli? È un'iperbole?
"Crushes" è un termine di marketing, ma dietro questa affermazione ci sono affermazioni oggettive:
- Classifiche: Grok 4.1 occupa le prime posizioni nelle classifiche pubbliche di LMArena per la generazione di testo (1483 Elo per la modalità Pensiero) e vanta ottimi risultati in termini di creatività e EQ-bench, secondo la versione di xAI. Si tratta di parametri competitivi comparabili utilizzati dall'intera community.
- Vince la preferenza per il traffico reale: xAI segnala un incremento delle preferenze umane nei confronti ciechi (~65% di preferenza rispetto al modello di produzione precedente) a partire da un'implementazione silenziosa sul traffico live. Ciò riflette i miglioramenti degli utenti reali, non solo i benchmark cartacei.
- Nuova capacità pratica: La combinazione di classificatori di modelli, RL su segnali non verificabili e filtri di input più rigorosi rappresenta un passo ingegneristico pragmatico che migliora direttamente l'esperienza dell'utente in attività conversazionali, empatiche e creative in cui i concorrenti storicamente hanno prestazioni inferiori.
Quindi, mentre “cotta” è un modo colorito per dire “è leader in molteplici valutazioni pubbliche e interne”, le metriche pubbliche sottostanti pubblicate da xAI supportano questa conclusione.
Come accedere a Grok 4.1
Accesso consumatore/app
xAI ha reso periodicamente Grok 4.1 accessibile in modalità "Auto" gratuitamente o come finestra promozionale, ma i livelli premium (SuperGrok, SuperGrok Heavy) e l'accesso API con quote più elevate esistono e persistono come offerte a pagamento.
Grok 4.1 è disponibile per tutti gli utenti on grok.com, **X (precedentemente Twitter)**e le app Grok per iOS e Android, che verranno lanciate immediatamente in modalità Auto e saranno anche selezionabili esplicitamente come "Grok 4.1" nel selettore del modello.
Accesso API e piani per sviluppatori
Gli endpoint Grok 4.1 sono disponibili tramite l'API xAI. Alla data di pubblicazione di questo articolo, l'API ufficiale GPT 4.1 non è stata ancora rilasciata.
CometaAPI promette di tenere traccia delle ultime dinamiche del modello, tra cui API di Grok 4.1, che verrà rilasciato contemporaneamente al rilascio ufficiale. Non perdete l'occasione e continuate a seguire CometAPI. Nell'attesa, potete dare un'occhiata agli altri modelli di Grok come Grok-codice-veloce-1 e al Grok4, esplora le loro capacità nel Playground e consulta la guida API per istruzioni dettagliate su come chiamare . Prima di accedere, assicurati di aver effettuato l'accesso a CometAPI e di aver ottenuto la chiave API.
Consigli pratici per l'utilizzo di Grok 4.1 in produzione
Come ridurre il rischio di allucinazioni
- Abilita la ricerca in tempo reale o una catena di strumenti verificata per le query di ricerca di informazioni.
- Fornire passaggi di verifica: chiedi al modello di restituire fonti e prove per affermazioni fattuali; usa il
responsemetadati per ispezionare le citazioni (se disponibili). - Eseguire controlli deterministici (LLM di fact-checking, validatori di dati strutturati) come fase di post-elaborazione per output ad alto rischio.
Come controllare il tono e lo stile
- Utilizzare prompt di sistema espliciti per correggere la voce ("Sei formale ed empatico").
- Utilizza prompt supervisionati e piccoli modelli locali per una voce coerente in tutte le applicazioni.
- Se disponibile, sfrutta l'opzione di controllo dello stile di xAI e le manopole dello sterzo basate sulle ricompense.
Verdetto finale: Grok 4.1 è un cambiamento radicale?
Grok 4.1 lo è non è un un'architettura completamente nuova; piuttosto, è un'architettura sofisticata e ponderata post-allenamento / allineamento comunicato che si concentra su ciò che interessa realmente agli esseri umani nella chat: personalità, intelligenza emotiva, creatività e meno errori fattuali. Guadagni misurabili nelle classifiche, preferenze di traffico reale su larga scala e strumenti di sicurezza migliorati. Per le applicazioni che si basano su conversazioni di alta qualità, collaborazione creativa o assistenza basata sul tono, Grok 4.1 rappresenta un importante passo avanti e, in diversi benchmark della community, si è rivelato il migliore al momento del rilascio.
CometAPI è una piattaforma commerciale di aggregazione di API che offre agli sviluppatori un accesso REST unificato, in stile OpenAI, a centinaia di modelli di intelligenza artificiale di diversi fornitori (LLM di testo, generatori di immagini/video, embedding e altro ancora) tramite un'unica interfaccia coerente. Invece di collegare SDK separati o endpoint personalizzati per OpenAI, Anthropic, Google, Meta o provider di modelli specializzati più piccoli, CometAPI consente di richiamare modelli diversi modificando le stringhe del modello e alcuni parametri.
Pronti a provare?→ Iscriviti oggi a CometAPI !
Se vuoi conoscere altri suggerimenti, guide e novità sull'IA seguici su VK, X e al Discordia!