
grok-code-fast-1 è il modello agentico per la programmazione focalizzato sulla velocità e conveniente nei costi di xAI, progettato per alimentare integrazioni IDE e agenti di codifica automatizzati. Enfatizza bassa latenza, comportamenti agentici (chiamate a strumenti, tracce di ragionamento passo-passo) e un profilo di costi contenuto per i workflow quotidiani degli sviluppatori.
Caratteristiche principali (in breve)
- Elevato throughput / bassa latenza: focalizzato su emissione di token molto rapida e completamenti veloci per l’uso in IDE.
- Chiamata di funzioni agentiche e strumentazione: supporta function calls e orchestrazione di strumenti esterni (esecuzione di test, linters, fetch di file) per abilitare agenti di codifica multi-step.
- Ampia finestra di contesto: progettato per gestire grandi codebase e contesti multi-file (i provider elencano finestre di contesto da 256k negli adattatori dei marketplace).
- Ragionamento/tracce visibili: le risposte possono includere tracce di ragionamento passo-passo, pensate per rendere ispezionabili e debug‑gabili le decisioni dell’agente.
Dettagli tecnici
Architettura e addestramento: xAI afferma che grok-code-fast-1 è stato costruito da zero con una nuova architettura e un corpus di pre‑addestramento ricco di contenuti di programmazione; il modello ha poi ricevuto una messa a punto post‑addestramento su dataset di pull request/codice reali e di alta qualità. Questa pipeline di ingegneria è mirata a rendere il modello pratico nei workflow agentici (IDE + uso di strumenti).
Erogazione e contesto: grok-code-fast-1 e i pattern d’uso tipici presuppongono output in streaming, chiamate di funzione e ricca iniezione di contesto (caricamenti/raccolte di file). Diversi marketplace cloud e adattatori di piattaforma lo elencano già con ampio supporto al contesto ( 256k contesti in alcuni adattatori).
Funzionalità di usabilità: tracce di ragionamento visibili (il modello espone la sua pianificazione/uso degli strumenti), indicazioni di prompt engineering e integrazioni di esempio, oltre a integrazioni con partner di lancio iniziali (ad es., GitHub Copilot, Cursor).
Prestazioni nei benchmark (punteggi)
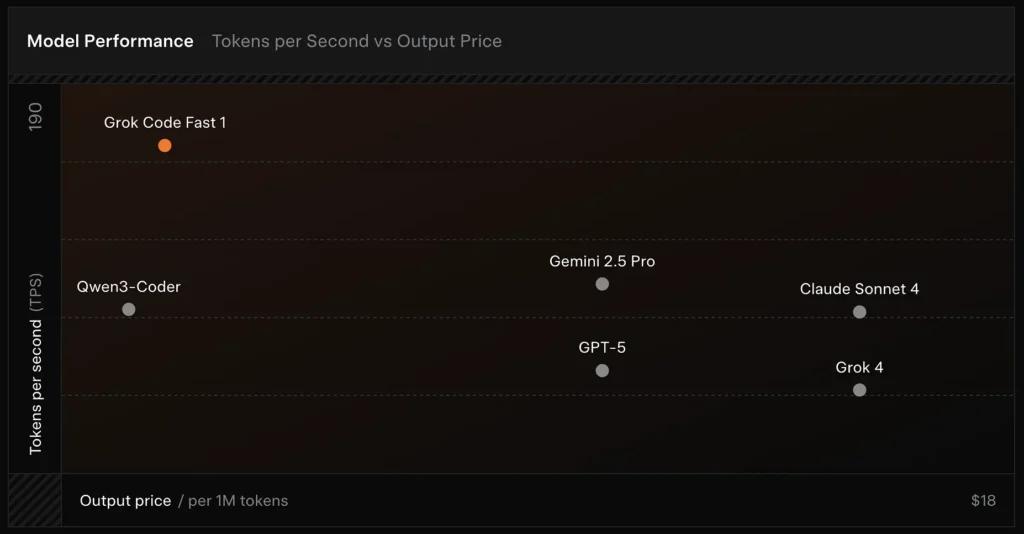
SWE-Bench-Verified: xAI riporta un punteggio del 70.8% sul proprio harness interno sul sottoinsieme SWE-Bench-Verified — un benchmark comunemente usato per confronti tra modelli di ingegneria del software. Una recente valutazione pratica ha riportato una valutazione media umana ≈ 7.6 su una suite mista di attività di coding — competitiva con alcuni modelli di alto valore (ad es., Gemini 2.5 Pro) ma dietro a modelli multimodali/“best‑reasoner” più grandi come Claude Opus 4 e lo stesso Grok 4 di xAI nei compiti di ragionamento più difficili. I benchmark mostrano anche variazione per compito: eccellente per correzioni di bug comuni e generazione di codice concisa, più debole su alcuni problemi di nicchia o specifici di libreria (esempio Tailwind CSS).
Comparison :
- vs Grok 4: Grok-code-fast-1 scambia una parte di correttezza assoluta e profondità di ragionamento per costi molto più bassi e throughput più veloce; Grok 4 rimane l’opzione a capacità più elevata.
- vs Claude Opus / GPT-class: Questi modelli spesso guidano su compiti complessi, creativi o di ragionamento difficile; Grok-code-fast-1 compete bene su attività di routine ad alto volume in cui latenza e costo contano.
Limitazioni e rischi
Limitazioni pratiche osservate finora:
- Lacune di dominio: cali di prestazione su librerie di nicchia o problemi formulati in modo inusuale (esempi includono casi limite di Tailwind CSS).
- Compromesso costo dei token di ragionamento: poiché il modello può emettere token di ragionamento interni, un ragionamento molto agentico/verboso può aumentare la lunghezza dell’output d’inferenza (e il costo).
- Accuratezza / casi limite: pur essendo forte nei compiti di routine, può allucinare o produrre codice errato per algoritmi nuovi o enunciati avversari; può rendere meno bene rispetto ai migliori modelli focalizzati sul ragionamento in benchmark algoritmici impegnativi.
Casi d’uso tipici
- Assistenza IDE e prototipazione rapida: completamenti veloci, scrittura incrementale di codice e debugging interattivo.
- Agenti automatizzati / workflow di codice: agenti che orchestrano test, eseguono comandi ed editano file (ad es., helper CI, bot reviewer).
- Attività ingegneristiche quotidiane: generazione di scheletri di codice, refactor, suggerimenti di triage bug e scaffolding di progetti multi‑file in cui la bassa latenza migliora materialmente il flusso dello sviluppatore.
Come chiamare l’API grok-code-fast-1 da CometAPI
grok-code-fast-1 API Pricing in CometAPI,20% off the official price:
- Input Tokens: $0.16/ M tokens
- Output Tokens: $2.0/ M tokens
Passaggi necessari
- Accedi a cometapi.com. Se non sei ancora nostro utente, registrati prima
- Ottieni la chiave API di credenziale di accesso dell’interfaccia. Clicca “Add Token” nella sezione API token del centro personale, ottieni la chiave del token: sk-xxxxx e inviala.
Metodo di utilizzo
- Seleziona l’endpoint “
grok-code-fast-1” per inviare la richiesta API e imposta il corpo della richiesta. Il metodo e il body della richiesta si ottengono dalla documentazione API sul nostro sito web. Il nostro sito fornisce anche test Apifox per tua comodità. - Sostituisci <YOUR_API_KEY> con la tua chiave CometAPI effettiva dal tuo account.
- Inserisci la tua domanda o richiesta nel campo content—è a questo che il modello risponderà.
- . Elabora la risposta dell’API per ottenere la risposta generata.
CometAPI fornisce una REST API pienamente compatibile — per una migrazione senza attriti. Dettagli chiave nella documentazione API:
- URL di base: https://api.cometapi.com/v1/chat/completions
- Nomi modello: “
grok-code-fast-1“ - Autenticazione: token Bearer tramite intestazione
Authorization: Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
Integrazione API ed esempi
Snippet Python per una chiamata ChatCompletion tramite CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Summarize grok-code-fast-1's main features."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Vedi anche Grok 4