

Uni-1 di Luma AI è più di un nuovo modello testo-immagine. Nella definizione di Luma, è un “modello di ragionamento multimodale che può generare pixel”, costruito su “Unified Intelligence” così da poter comprendere l’intenzione, rispondere alla direzione e “pensare con te”. Il rapporto tecnico dell’azienda afferma che il modello utilizza un trasformatore autoregressivo solo decoder in cui testo e immagini sono rappresentati in un’unica sequenza intercalata, e che Uni-1 può eseguire ragionamenti interni strutturati prima e durante la sintesi dell’immagine. Questa combinazione è ciò che rende Uni-1 una delle uscite di modelli di immagini più interessanti del 2026.
Che cos’è il modello di immagini UNI-1?
Uni-1 è il nuovo modello di immagini di Luma AI per attività che richiedono comprensione e generazione in un unico sistema. Luma lo presenta come un modello di ragionamento multimodale, piuttosto che un classico motore d’immagini basato solo su diffusione, il che è rilevante perché il modello è pensato per fare più che produrre output visivamente gradevoli: è progettato per interpretare le istruzioni, preservare i vincoli dei riferimenti e ragionare sulla logica della scena come parte della generazione. Il rapporto tecnico dell’azienda descrive Uni-1 come il suo primo modello unificato di comprensione e generazione nel percorso verso un’intelligenza multimodale generale.
Perché Uni-1 è diverso
La vecchia pipeline ha un limite: la generazione d’immagini senza comprensione può arrivare solo fino a un certo punto. Uni-1 viene presentato come un passo verso una “intelligenza unificata”, in cui linguaggio, percezione, immaginazione, pianificazione ed esecuzione sono gestiti all’interno di un’unica architettura. Questo è più di un semplice branding. Uni-1 può passare dalla somiglianza visiva alla composizione intenzionale, alla plausibilità e alla logica della scena.
La storia più ampia è che i modelli di immagini stanno diventando più orientati all’azione. L’ultimo stack di immagini di Google ora enfatizza l’editing conversazionale, l’ancoramento alla ricerca, la fusione multi-immagine e la coerenza dei personaggi; la famiglia GPT Image di OpenAI enfatizza la multimodalità nativa e il rispetto delle istruzioni. Uni-1 si unisce a questo cambiamento, ma spinge più a fondo sull’idea che il modello debba “pensare” all’immagine prima di disegnarla. Ciò rende Uni-1 particolarmente interessante per workflow in cui precisione e ripetibilità contano quanto l’estro visivo.
Come funziona realmente Uni-1?
🔬 Processo di tokenizzazione
- Testo → sequenza di token
- Immagine → patch tokenizzati
- Combinati in un’unica sequenza intercalata
🔁 Processo di generazione
- Prompt di input + riferimenti
- Il modello esegue ragionamento interno
- Pianifica la composizione
- Genera token in modo sequenziale
Matematicamente: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Livello di ragionamento interno
Uni-1:
- Scompone le istruzioni
- Risolve i vincoli
- Pianifica il layout prima del rendering
👉 Questo è un grande passo avanti rispetto ai modelli di diffusione.
Generazione autoregressiva solo decoder
Il dettaglio tecnico più importante è che Uni-1 è autoregressivo, non basato sulla diffusione. Il rapporto tecnico di Luma afferma che si tratta di un trasformatore autoregressivo solo decoder e che testo e immagini sono codificati in un’unica sequenza intercalata. In parole semplici, il modello non parte semplicemente dal rumore per “denoizzare” progressivamente fino a un’immagine. Invece, genera token passo dopo passo, consentendo al modello di ragionare sul prompt, risolvere i vincoli e pianificare la composizione prima e durante il rendering.
🔬 Processo di tokenizzazione
- Testo → sequenza di token
- Immagine → patch tokenizzati
- Combinati in un’unica sequenza intercalata
Diffusione vs Autoregressivo
| Caratteristica | Modelli di diffusione | Uni-1 (Autoregressivo) |
|---|---|---|
| Generazione | Rumore → Immagine | Token per token |
| Ragionamento | Limitato | Forte |
| Editing | Debole | Multi-turno |
| Rendering del testo | Scarso | Forte |
| Controllo | Basso | Alto |
Architettura di base
Uni-1 è:
- Trasformatore autoregressivo solo decoder
- Spazio di token condiviso per testo + immagini
Questa architettura è importante perché offre al modello la possibilità di mantenere coerenza quando il prompt è complicato. Luma afferma che Uni-1 può scomporre le istruzioni, risolvere vincoli in conflitto e pianificare l’immagine prima che inizi il rendering. Questo è particolarmente utile per attività come il completamento strutturato della scena, il posizionamento di più soggetti, la raffinazione multi-turno e le modifiche che richiedono che l’output resti fedele a un’immagine di riferimento pur obbedendo a nuove istruzioni.
Cosa il modello sembra progettato per fare meglio
Imparare a generare immagini migliora la comprensione. Luma afferma che l’addestramento alla generazione di immagini migliora in modo significativo la comprensione visiva fine-grained, in particolare su regioni, oggetti e layout. Ecco perché Uni-1 non è un generatore a senso unico, ma un sistema unificato in cui generazione e comprensione si rafforzano a vicenda. In fase di inferenza, ciò significa che Uni-1 cerca di colmare il divario tra “vedere” e “realizzare”. Questo è un grande passo avanti rispetto ai modelli di diffusione.
Processo di generazione:
- Prompt di input + riferimenti
- Il modello esegue ragionamento interno
- Pianifica la composizione
- Genera token in modo sequenziale
Matematicamente: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Quali funzionalità e vantaggi principali offre Uni-1?
Forte capacità di seguire le istruzioni e direzionabilità
Il punto di forza principale di Uni-1 è il controllo. Il modello è costruito per l’editing di precisione, l’uso strutturato dei riferimenti e workflow ripetibili. Per i creatori, ciò significa meno scommesse sui prompt e output più ripetibili.
Uno dei vantaggi pratici di Uni-1 è che è costruito per l’iterazione controllata. I seed consentono agli utenti di riprodurre i risultati, mentre i ruoli dei riferimenti aiutano il modello a capire se un’immagine debba guidare l’identità del personaggio, il mood, la palette o la composizione. Questo rende Uni-1 più facile da dirigere rispetto a un modello guidato unicamente dai prompt, soprattutto per team che producono annunci, storyboard, mockup di prodotto o asset di brand in cui la coerenza è fondamentale.
Generazione basata su riferimenti che preserva l’identità
Un vantaggio importante è la gestione dei riferimenti. Luma afferma esplicitamente che Uni-1 utilizza controlli ancorati alle fonti e può preservare identità, composizione e vincoli visivi chiave da uno o più riferimenti. Questo lo rende attraente per workflow commerciali come personaggi di brand, mockup di prodotto, asset di campagna e qualsiasi progetto in cui un soggetto debba rimanere riconoscibile tra le varianti. È uno dei modi più chiari in cui Uni-1 differisce dai sistemi di immagini più puramente estetici.
Competenza culturale e ampiezza di stili
Luma sottolinea anche la generazione attenta alla cultura. La sezione “Cultured” mostra meme, manga, look cinematografici, foto casual, sport e immagini di animali, indicando che il modello è pensato per operare attraverso linguaggi visivi, non un unico stile generico. Questo è importante perché un buon modello d’immagini moderno non deve solo rendere una scena realistica; deve anche comprendere le convenzioni visive della cultura internet, del design editoriale, dell’illustrazione stilizzata e dei contenuti social.
Pensiero multimodale come scelta di design
Il vero elemento distintivo non è solo che Uni-1 genera immagini, ma che Luma inquadra la generazione di immagini come un compito di ragionamento. Uni-1 può eseguire ragionamenti interni strutturati e l’apprendimento a generare immagini migliora la comprensione visiva fine-grained su regioni, oggetti e layout. Ciò suggerisce un modello pensato per comprendere la scena prima di renderizzarla, invece di approssimare semplicemente il prompt in modo statistico.
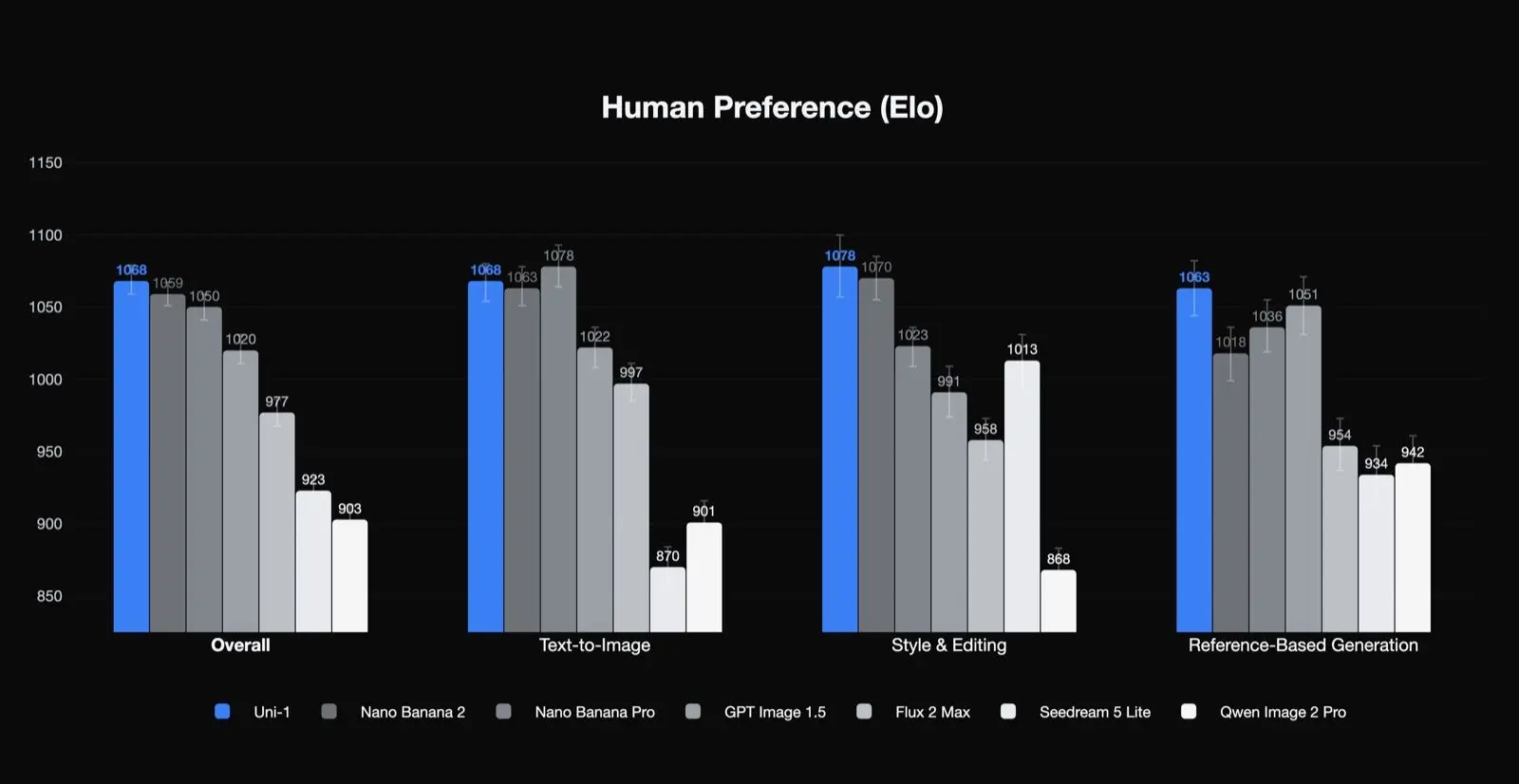
Benchmark di prestazioni
I risultati di Luma basati su preferenze umane
Uni-1 risulta primo nell’Elo di preferenza umana per qualità complessiva, stile ed editing, e generazione basata su riferimenti, e secondo nel testo-immagine. È un risultato significativo perché suggerisce che il modello è particolarmente forte nei tipi di compiti che interessano ai team di produzione: editing, coerenza e trasformazione guidata. Suggerisce anche che i suoi casi d’uso migliori potrebbero non essere la semplice generazione testo-immagine one-shot.
RISEBench: editing visivo guidato dal ragionamento
Il benchmark più appariscente è RISEBench, che valuta l’editing visivo informato dal ragionamento attraverso dimensioni temporali, causali, spaziali e logiche. Report di terze parti sul lancio di Luma affermano che Uni-1 ottiene 0,51 complessivo su RISEBench, davanti a Nano Banana 2 di Google a 0,50, Nano Banana Pro a 0,49 e GPT Image 1.5 di OpenAI a 0,46. Sul ragionamento spaziale, Uni-1 risulta a 0,58 contro 0,47 di Nano Banana 2. Sul ragionamento logico, Uni-1 è riportato a 0,32, più del doppio rispetto a 0,15 di GPT Image 1.5. I margini non sono enormi nel complesso, ma sono ampi nelle categorie di ragionamento più difficili.

ODinW-13 e l’affermazione “la generazione migliora la comprensione”
Uni-1 ottiene risultati forti anche su ODinW-13, un benchmark di rilevamento denso a vocabolario aperto. Report sui dati tecnici di Luma affermano che il modello completo ottiene 46,2 mAP, quasi al pari di Gemini 3 Pro di Google a 46,3. Gli stessi report dicono che una variante solo di comprensione ottiene 43,9 mAP, il che implica che l’addestramento alla generazione migliora la comprensione di 2,3 punti. È un risultato notevole perché supporta la tesi centrale di Luma: generazione d’immagini e comprensione d’immagini possono essere obiettivi che si rafforzano a vicenda, non in competizione.
Prezzo dell’API di Uni-1
| Prezzo input (testo) | $0.50 |
|---|---|
| Prezzo input (immagini) | $1.20 |
| Prezzo output (testo e ragionamento) | $3.00 |
| Prezzo output (immagini) | $45.45 |
Dal lato consumer, la pagina dei prezzi di Luma elenca Plus a $30/mese, Pro a $90/mese e Ultra a $300/mese, con crediti di prova gratuiti inclusi in tutti i piani. Ciò significa che essenzialmente ci sono due livelli di prezzo da considerare: l’abbonamento consumer alla piattaforma e i prezzi a livello di API del modello per l’uso in produzione.
Per ora, l’API Uni-1 di CometAPI è disponibile a breve, con uno sconto promesso al lancio. Attualmente, CometAPI offre anche ottimi modelli di immagini grezze, come Midjourney e Nano Banana 2.
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 rispetto a Nano Banana 2 di Google
Nano Banana 2 sembra più forte per ampiezza nella gestione dei riferimenti e integrazione dell’ecosistema. Google enfatizza l’ancoramento alla ricerca nelle immagini, l’iterazione conversazionale e workflow ricchi di riferimenti con fino a 14 riferimenti. Uni-1, per contro, è incorniciato più esplicitamente attorno al ragionamento, alla plausibilità della scena e all’editing di precisione in un’architettura di modello unificata. In termini pratici, Google appare ottimizzato per velocità, scala produttiva mainstream e grounding nativo di Google; Luma appare ottimizzata per ragionamento visivo strutturato e editing d’immagini diretto.
Nelle comparazioni pubbliche su Uni-1, il compromesso è chiaro: Nano Banana 2 sembra rimanere molto forte per qualità e velocità nella pura generazione testo-immagine, mentre Uni-1 spinge più forte su editing orientato al ragionamento, controllo dei riferimenti e fedeltà alle istruzioni.
Uni-1 rispetto a GPT Image di OpenAI
Nei report di benchmark, Uni-1 supera di poco GPT Image 1.5 su RISEBench complessivo e più nettamente sul ragionamento logico. Rispetto alla famiglia GPT Image di OpenAI, Uni-1 è posizionato in modo più ristretto e aggressivo attorno al ragionamento visivo e all’editing controllato. La documentazione di OpenAI enfatizza conoscenza del mondo, comprensione multimodale e consapevolezza del contesto; la documentazione di Luma enfatizza ragionamento interno strutturato, controllo ancorato ai riferimenti e abilità di editing visivo verificate dai benchmark. Quindi, pur essendo entrambi multimodali, Uni-1 è il più evidentemente “modello specialista di immagini orientato al ragionamento”, mentre GPT Image appare più come un sistema multimodale generale che sa anche generare immagini molto bene.
Confronto prezzi tra i tre
Sul prezzo, il confronto dipende dalla dimensione dell’output e dal tier di prodotto, quindi non è perfettamente sovrapponibile. L’equivalente 2048px pubblicato di Uni-1 è circa $0.0909 per immagine. L’ultima pagina di pricing dei modelli immagine di Google elenca $0.134 per immagine 1K/2K e $0.24 per immagine 4K per l’ultima preview di Gemini image, mentre la pagina prezzi di GPT Image di OpenAI elenca prezzi per immagine in output di $0.011 a bassa qualità per 1024x1024, $0.042 a qualità media e $0.167 ad alta qualità, con output ad alta qualità più grandi a $0.25. In altre parole, OpenAI può essere molto più economica al livello basso, Google è aggressiva su velocità e scala, e Uni-1 si colloca nel mezzo con un forte profilo prezzo-prestazioni orientato ai 2K.
Differenze filosofiche
| Modello | Approccio |
|---|---|
| Uni-1 | Intelligenza multimodale unificata |
| GPT Image | LLM + generazione di immagini |
| Nano Banana 2 | Diffusione ottimizzata per la produzione |
Tabella di confronto dettagliata
| Caratteristica | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Architettura | Autoregressiva | Ibrida | Diffusione |
| Unificazione multimodale | ✅ Nativa | Parziale | ❌ |
| Capacità di ragionamento | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Qualità dell’immagine | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Rendering del testo | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Workflow di editing | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Velocità | Media | Veloce | Veloce |
| Controllo | Alto | Medio | Medio |
CometAPI fornisce immagini raw interattive per GPT Image 1.5, Nano Banana 2, e il prossimo Uni-1, oltre ad API per la programmazione. Prezzi scontati e opzioni pay-as-you-go lo rendono una scelta preferita per gli sviluppatori.
Per cosa è migliore Uni-1
Uni-1 sembra particolarmente forte nei casi in cui servono ripetibilità, coerenza dei personaggi o controllo multi-riferimento. Ciò include campagne di brand, mockup di prodotto, concept editoriali, storyboard, varianti localizzate e modifiche d’immagine in cui la composizione deve restare intatta ma stile o ambiente devono cambiare. Gli esempi di Luma puntano molto su questi casi d’uso, e lo split “Create vs Modify” del modello è sostanzialmente una risposta diretta ai comuni punti dolenti della produzione.
Se il tuo lavoro è per lo più “crea qualcosa di bello da un singolo prompt”, il differenziatore può sembrare meno eclatante. Ma se il tuo workflow è “fai cinque versioni correlate, mantieni lo stesso personaggio, preserva l’inquadratura, cambia le luci e rendilo riproducibile la prossima settimana”, il design di Uni-1 inizia ad avere molto senso. È un’inferenza, ma segue naturalmente dalle funzionalità di controllo che Luma enfatizza.
Best practice per ottenere risultati migliori con Uni-1
Inizia usando la modalità corretta. La guida di Luma è semplice: Create quando vuoi una nuova scena, Modify quando vuoi preservarne una esistente. Mescolare queste intenzioni rende gli output più instabili.
Usa etichette di riferimento come un professionista. Luma raccomanda frasi come “Usa IMAGE1 come riferimento di STILE” o “Usa IMAGE2 come ILLUMINAZIONE.” Il modello rende meglio quando ogni riferimento ha un compito, invece di una vaga “ispirazione”.
Blocca il seed dopo che trovi qualcosa di buono. Luma raccomanda esplicitamente di esplorare prima senza seed, poi salvare il seed una volta ottenuto un risultato forte. Da lì, cambia una variabile alla volta. È il modo più semplice per trasformare la generazione in un sistema di produzione controllato.
Sii specifico e concreto. Luma sconsiglia parole vaghe come “beautiful” o “amazing” e incoraggia estetiche nominate come “poster di un film giallo italiano degli anni ’70” o indicazioni esatte sullo stile della camera. In pratica, i prompt specifici battono di solito quelli poetici perché il modello può ancorarsi a una struttura reale.
Usa la catena Create → Modify. Luma afferma esplicitamente che questo è uno dei workflow più potenti: esplora in Create, poi affina in Modify. È il punto dolce per il lavoro di produzione serio, perché riduce i backtracking e preserva le parti buone di una composizione mentre si stringono i dettagli.
Verdetto finale
Uni-1 è l’affermazione più chiara di Luma che la generazione d’immagini stia passando da “prompt in, immagine out” alla creazione visiva guidata dal ragionamento. I suoi punti di forza pubblici sono controllo, gestione dei riferimenti, riproducibilità e un’architettura di modello che tiene linguaggio e pixel nello stesso sistema.
Per creatori e team che tengono a un output visivo ad alto tasso di clic, personaggi coerenti, modifiche precise e chiarezza di prezzo ad alta risoluzione, Uni-1 è davvero un modello da tenere d’occhio. Se il rollout dell’API andrà liscio, potrebbe diventare una delle alternative più interessanti a Nano Banana 2 di Google e a GPT Image 1.5 di OpenAI nel 2026.
Stai pianificando di iniziare a creare immagini grezze? CometAPI, una piattaforma unica di aggregazione per API di modelli multimodali, ti dà il benvenuto!