

Nel panorama in rapida evoluzione dell'intelligenza artificiale, il 2025 ha visto progressi significativi nei modelli linguistici di grandi dimensioni (LLM). Tra i capofila ci sono Qwen2.5 di Alibaba, i modelli V3 e R1 di DeepSeek e ChatGPT di OpenAI. Ognuno di questi modelli offre funzionalità e innovazioni uniche. Questo articolo approfondisce gli ultimi sviluppi di Qwen2.5, confrontandone le caratteristiche e le prestazioni con DeepSeek e ChatGPT per determinare quale modello sia attualmente in testa alla corsa all'intelligenza artificiale.
Cos'è Qwen2.5?
Panoramica
Qwen 2.5 è l'ultimo modello linguistico di Alibaba Cloud, denso e decoder-only, disponibile in diverse dimensioni, da 0.5 a 72 miliardi di parametri. È ottimizzato per l'instruction-following, output strutturati (ad esempio, JSON, tabelle), la codifica e la risoluzione di problemi matematici. Con il supporto di oltre 29 lingue e una lunghezza del contesto fino a 128 token, Qwen 2.5 è progettato per applicazioni multilingue e specifiche di dominio.
Funzionalità principali
- Supporto multilingue: Supporta oltre 29 lingue, soddisfacendo le esigenze di una base di utenti globale.
- Lunghezza del contesto estesa: Gestisce fino a 128K token, consentendo l'elaborazione di documenti e conversazioni lunghi.
- Varianti specializzate: Include modelli come Qwen2.5-Coder per attività di programmazione e Qwen2.5-Math per la risoluzione di problemi matematici.
- Accessibilità: Disponibile tramite piattaforme come Hugging Face, GitHub e una nuova interfaccia web lanciata su chat.qwenlm.ai.
Come utilizzare Qwen 2.5 in locale?
Di seguito è riportata una guida passo passo per 7 B Chat checkpoint; le dimensioni maggiori differiscono solo nei requisiti GPU.
1. Prerequisiti hardware
| Modello | vRAM per 8 bit | vRAM per 4 bit (QLoRA) | Dimensione del disco |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Una singola RTX 4090 (24 GB) è sufficiente per un'inferenza di 7 B con precisione a 16 bit; due di queste schede o lo scarico della CPU più la quantizzazione possono gestire 14 B.
2. Installazione
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Script di inferenza rapida
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
. trust_remote_code=True il flag è obbligatorio perché Qwen spedisce un prodotto personalizzato Incorporamento della posizione rotante involucro.
4. Ottimizzazione con LoRA
Grazie agli adattatori LoRA con parametri efficienti, è possibile addestrare Qwen in modo specializzato su circa 50 coppie di domini (ad esempio, medici) in meno di quattro ore su una singola GPU da 24 GB:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Il file adattatore risultante (~120 MB) può essere riunito o caricato su richiesta.
Facoltativo: esegui Qwen 2.5 come API
CometAPI funge da hub centralizzato per le API di diversi modelli di intelligenza artificiale leader, eliminando la necessità di interagire separatamente con più fornitori di API. CometaAPI Offre un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti a integrare le API di Qwen: riceverai 1$ sul tuo account dopo la registrazione e l'accesso! Benvenuto nella sezione "Registrati e prova CometAPI". Per gli sviluppatori che desiderano integrare Qwen 2.5 nelle applicazioni:
Passaggio 1: installare le librerie necessarie:
bash
pip install requests
Passaggio 2: ottenere la chiave API
- Accedere a CometaAPI.
- Accedi con il tuo account CometAPI.
- Seleziona il Cruscotto.
- Fai clic su "Ottieni chiave API" e segui le istruzioni per generare la tua chiave.
Passo 3: Implementare le chiamate API
Utilizza le credenziali API per effettuare richieste a Qwen 2.5.Sostituisci con la tua chiave CometAPI effettiva dal tuo account.
Ad esempio, in Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Questa integrazione consente l'incorporazione senza soluzione di continuità delle funzionalità di Qwen 2.5 in varie applicazioni, migliorando la funzionalità e l'esperienza utente.Seleziona il “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” endpoint per inviare la richiesta API e impostarne il corpo. Il metodo e il corpo della richiesta sono reperibili nella documentazione API del nostro sito web. Il nostro sito web fornisce anche il test Apifox per vostra comodità.
Si prega di fare riferimento a API massima di Qwen 2.5 per i dettagli sull'integrazione. CometAPI ha aggiornato l'ultima versione API QwQ-32BPer ulteriori informazioni sul modello in Comet API, vedere Documento API.
Migliori pratiche e suggerimenti
| Scenario | Consigli |
|---|---|
| Domande e risposte su documenti lunghi | Suddividere i passaggi in token ≤16 K e utilizzare prompt con recupero aumentato anziché contesti semplici da 100 K per ridurre la latenza. |
| Risultati strutturati | Aggiungere al messaggio di sistema il prefisso: You are an AI that strictly outputs JSON. L'addestramento all'allineamento di Qwen 2.5 eccelle nella generazione vincolata. |
| Completamento del codice | Impostato temperature=0.0 e al top_p=1.0 per massimizzare il determinismo, quindi campionare più fasci (num_return_sequences=4) per la classifica. |
| Filtraggio di sicurezza | Come primo tentativo, utilizzare il bundle di espressioni regolari open source "Qwen-Guardrails" di Alibaba oppure text-moderation-004 di OpenAI. |
Limitazioni note di Qwen 2.5
- Suscettibilità all'iniezione rapida. Le verifiche esterne mostrano tassi di successo del jailbreak pari al 18% su Qwen 2.5‑VL, a dimostrazione del fatto che le dimensioni del modello non proteggono dalle istruzioni avversarie.
- Rumore OCR non latino. Quando viene ottimizzata per attività di linguaggio visivo, la pipeline end-to-end del modello a volte confonde i glifi cinesi tradizionali con quelli semplificati, richiedendo livelli di correzione specifici del dominio.
- Caduta della memoria della GPU a 128 K. FlashAttention‑2 compensa la RAM, ma un passaggio in avanti denso di 72 B su token da 128 K richiede comunque >120 GB di vRAM; gli utenti dovrebbero usare window-attend o KV-cache.
Roadmap ed ecosistema della comunità
Il team di Qwen ha accennato a Qwen 3.0, che punta a un backbone di routing ibrido (Dense + MoE) e a un pre-addestramento unificato di parlato, visione e testo. Nel frattempo, l'ecosistema ospita già:
- Agente Q – un agente di catena di pensiero in stile ReAct che utilizza Qwen 2.5-14B come policy.
- Alpaca finanziario cinese – un LoRA su Qwen2.5‑7B addestrato con 1 M di documenti normativi.
- Plug-in Open Interpreter – sostituisce GPT‑4 con un checkpoint Qwen locale in VS Code.
Consulta la pagina della collezione “Qwen2.5” di Hugging Face per un elenco costantemente aggiornato di punti di controllo, adattatori e imbracature di valutazione.
Analisi comparativa: Qwen2.5 vs. DeepSeek e ChatGPT
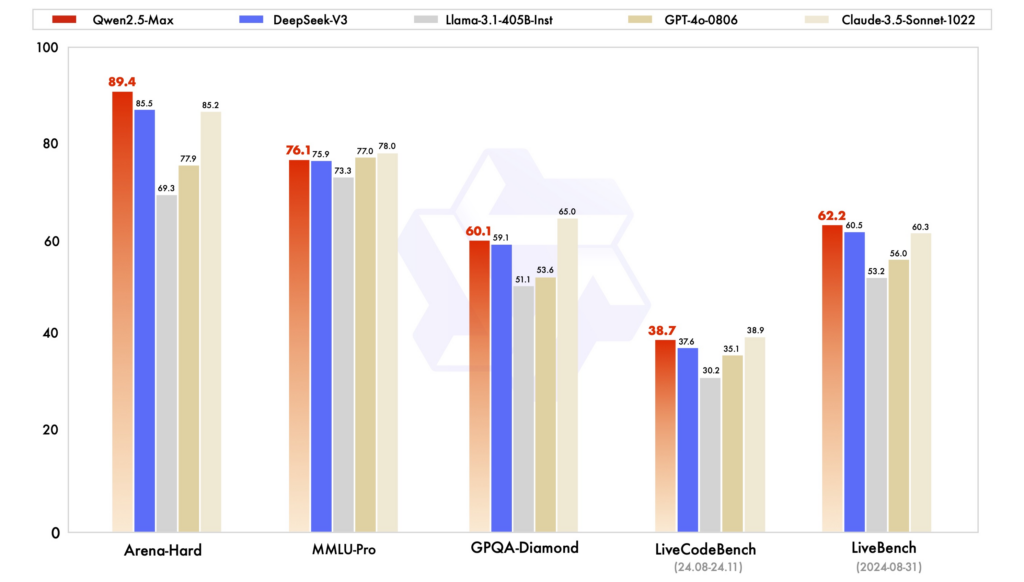
Benchmark delle prestazioni: In diverse valutazioni, Qwen2.5 ha dimostrato ottime prestazioni in attività che richiedono ragionamento, programmazione e comprensione multilingue. DeepSeek-V3, con la sua architettura MoE, eccelle in efficienza e scalabilità, offrendo prestazioni elevate con risorse computazionali ridotte. ChatGPT rimane un modello robusto, in particolare nelle attività linguistiche di uso generale.
Efficienza e costi: I modelli di DeepSeek si distinguono per l'economicità del training e dell'inferenza, sfruttando le architetture MoE per attivare solo i parametri necessari per token. Qwen2.5, pur essendo denso, offre varianti specializzate per ottimizzare le prestazioni per attività specifiche. Il training di ChatGPT ha richiesto ingenti risorse computazionali, il che si riflette sui costi operativi.
Accessibilità e disponibilità open source: Qwen2.5 e DeepSeek hanno adottato i principi open source in diversa misura, con modelli disponibili su piattaforme come GitHub e Hugging Face. Il recente lancio di un'interfaccia web da parte di Qwen2.5 ne migliora l'accessibilità. ChatGPT, pur non essendo open source, è ampiamente accessibile tramite la piattaforma e le integrazioni di OpenAI.
Conclusione
Qwen 2.5 si trova in un punto ideale tra servizi premium a peso chiuso e al modelli hobbisti completamente apertiLa combinazione di licenze permissive, solidità multilingue, competenza di lungo contesto e un'ampia gamma di scale di parametri lo rende una base convincente sia per la ricerca che per la produzione.
Mentre il panorama LLM open source avanza a gran velocità, il progetto Qwen dimostra che trasparenza e performance possono coesisterePer sviluppatori, data scientist e policy maker, padroneggiare Qwen 2.5 oggi rappresenta un investimento in un futuro dell'intelligenza artificiale più pluralistico e favorevole all'innovazione.