

2026年4月1日にリリースされたAlibabaのWan2.7-Imageは、AIによるビジュアル生成における大きな飛躍を示す。この統合モデルは、テキストからの画像生成、インタラクティブ編集、マルチイメージ合成、セマンティック理解を単一のアーキテクチャに統合する。従来の生成と編集を分離したパイプラインとは異なり、「画一的なAI顔」、文字化けしたテキスト、予測不能な色といった不整合を排除する。
クリエイター、デザイナー、マーケター、企業は、反復回数を減らしても写実的で指示通りの結果を達成できる。モデルは最大12枚の連続画像、9枚のリファレンス融合、12言語のテキスト描画(最大3,000トークン)、ピクセルレベル制御に対応する。
Wan2.7-Imageとは?
Wan2.7-Imageは、AlibabaのTongyi Labが提供するWan(Tongyi Wanxiang)シリーズにおける統合型画像モデルのフラッグシップだ。テキストから画像生成、画像から画像への変換、コマンドベースの編集、インタラクティブなピクセルレベルの微調整まで、エンドツーエンドのビジュアルワークフローを単一の共有潜在空間で扱う。
2026年4月1日にリリースされ、VBenchベンチマークでトップを獲得したWan 2.xの動画モデルを基盤に、画像の精度へと焦点をシフトしている。以前のAIツールで見られた繰り返しの顔、色の不安定さ、プロンプト整合性の低さによる「美的疲労」を直接解消する。モデルファミリーには、ユーザーにとって特に重要な2つの名称、wan2.7-image と wan2.7-image-pro がある。スタンダード版は高速な生成速度に調整され、Pro版はプロフェッショナル品質を狙い、4K高精細に対応する。
差別化の要は、統合アーキテクチャだ。従来モデルはステージが分断されており(エンコーダ→拡散→デコーダ)、編集には別途インペインティングが必要だった。Wan2.7-Imageは共有空間でセマンティクスを直接マッピングし、ピクセルのパターンマッチングではなく真の理解を可能にする。
なぜWan2.7-Imageが重要か(業界コンテクスト)
従来のAI画像ツールの問題点:
| 課題 | 説明 |
|---|---|
| 分断されたワークフロー | 生成、編集、インペインティングが別ツール |
| 「AI顔シンドローム」 | 顔が繰り返しで非現実的 |
| 指示整合性の弱さ | プロンプトに正確に従わない |
| テキスト描画の品質不足 | 文字が歪む、読めない |
| マルチイメージ出力の不一致 | フレーム間でキャラクターが変わる |
Wan2.7-Imageは、統合アーキテクチャ+セマンティック理解レイヤでこれらの制約に直接対処する。
Wan2.7-Imageの5つの中核機能
1. 骨格レベルのアバターカスタマイズで「本当にユニークな顔」を実現
Wan2.7-Imageは「一人ひとりにユニークな顔」を得意とする。骨格、目の形(アーモンド型、フェニックス型、くぼみ目、はれぼったい、笑い目)、輪郭、微細なディテールまできめ細かく制御でき、従来モデルを悩ませた「画一的なAI顔」を解消する。

プロンプト例:「東アジア系の28歳女性のフォトリアリスティックなポートレート。卵形の顔、アーモンド型の目、控えめな微笑み、詳細な肌の質感、自然光。」結果は、バーチャルインフルエンサー、ゲームのNPC、パーソナライズド・ブランディングに理想的な、生命感ある多様性を示す。
2. 厳密なカラーパレット制御
最も実用的な機能の一つが新しいカラーパレット制御だ。Alibabaによれば、ユーザーは特定のカラーコードと比率を入力して芸術スタイルを再現したり、ブランドカラーを固定したりできる。APIドキュメントでは、color_palette パラメータが3〜10色(8色推奨)を受け入れると定義されている。ブランドチームにとって、これはリリースの中でも最も明確なエンタープライズ志向の機能だ。ランダムな色ブレはもう発生せず、キャンペーン全体を通じて完全な一貫性が得られる。
公式コメント:「ランダムな色生成に別れを告げましょう。正確な色比率を実現し、あなたのクリエイティブ・ビジョンを形にします。」— Tongyi Wanxiang
3. 高度な多言語テキスト描画(12言語、3,000トークン)
超長文のテキスト、表、数式、チャート、インフォグラフィックを、印刷品質(A4相当)の鮮明さで描画する。中国語、英語、日本語、韓国語を含む計12言語に対応。論文、ポスター、製品ラベル、多言語バナーでほぼ完璧な可読性を実現し、AIの歴史的弱点に対処する。
4. マーキー選択によるピクセル精密インタラクティブ編集
バウンディングボックス(editRegions)やマーキー選択ツールでターゲットを限定して変更できる。最大9枚のリファレンスをアップロードし、「顔、ポーズ、衣装を維持したまま背景をビーチの夕焼けに変更」といった指示を行える。ピクセルレベルの精度により、アイデンティティを確実に保持する。
5. マルチイメージの構成的生成(最大12枚の連続画像)
本モデルは単一プロンプトの生成にとどまらない。Alibabaによれば、最大9枚のリファレンス画像を用い、一度に最大12枚を生成でき、整合性のある絵コンテ、建築、ECシリーズに最適だ。「クリックで編集」のフローにより、特定領域を選択してピクセルレベルの精度で変更でき、APIドキュメントにはローカル編集のためのバウンディングボックスパラメータによるインタラクティブ精密編集が追加されている。
Wan2.7-Imageはどう機能するか(技術的深掘り)
Alibabaは、Wan2.7-Imageを言語とビジュアルを橋渡しするフレームワークとして説明しており、多様で大規模なデータセットでの学習によって成立している。平たく言えば、このモデルは単に画像の描き方を学ぶだけでなく、プロンプトが視覚構造、構図、ライティング、テキスト配置にどう対応するかを学習する。それが、単純なテキスト→画像システムよりもユーザー意図を正確に解釈できる理由だ。
APIからも、このモデルがマルチモーダル入力に対応していることがわかる。実運用では、リクエストは単一ターンのメッセージ構造で送られ、コンテンツにはテキストと画像の両方を含められる。編集では、複数画像と「move」「replace」「blend」といった指示を渡して結果を誘導できる。これは、Wan2.7が単なるワンショット生成ではなく、プロンプト+リファレンス型システムとして設計されている明確な証左だ。
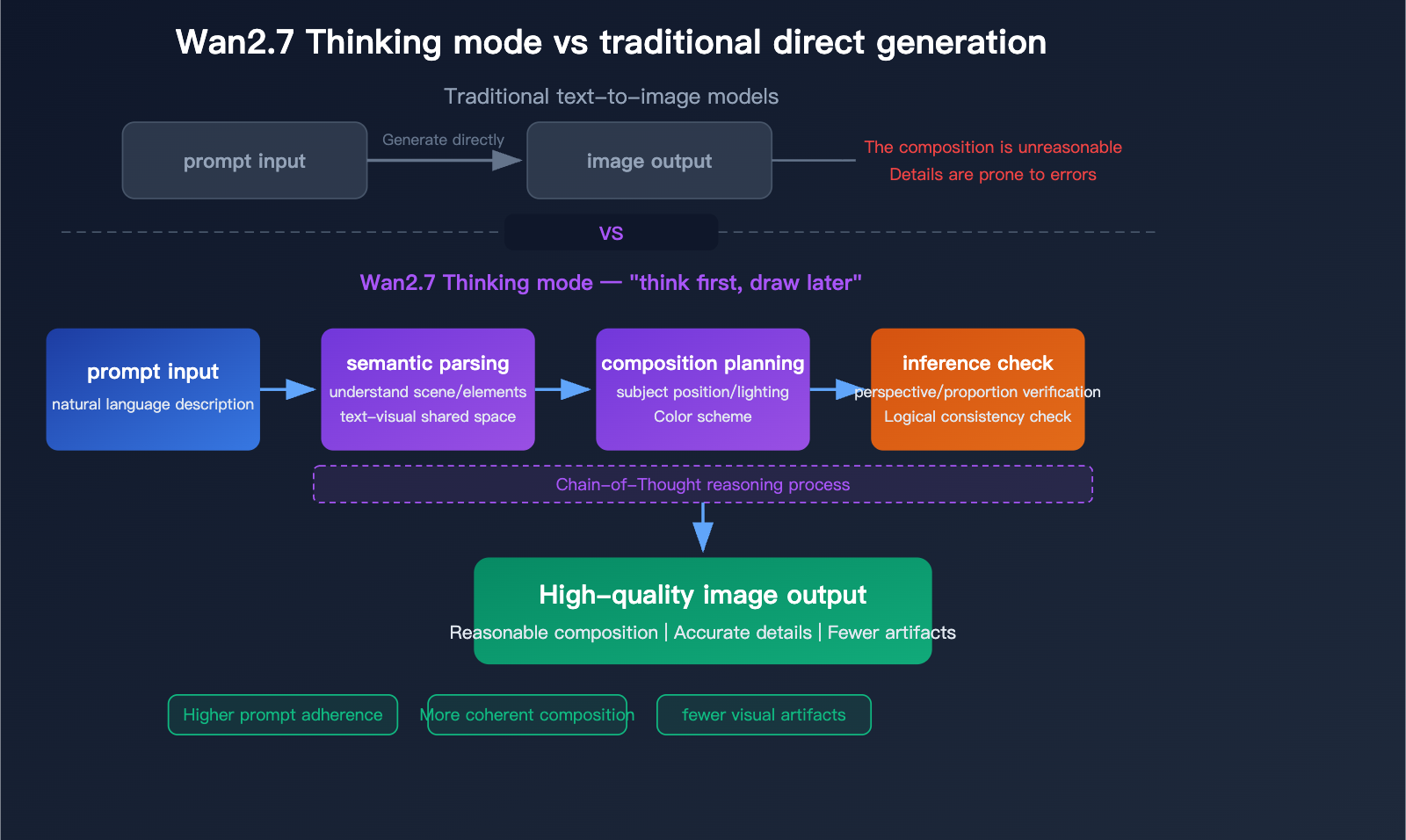
ドキュメントには思考モード設定も公開されている。デフォルトで有効で出力品質を高める一方、生成時間は増加する。これはワークフローの重要な手がかりであり、特にテキスト量が多い、視覚的に複雑なリクエストでは、高品質な出力により長い内部推論時間が必要になり得ることを示唆している。
Wan2.7-Imageは共有潜在空間での生成・編集の統合フレームワークを採用している。
- 入力段階: テキストプロンプト(最大3,000トークン)+任意のリファレンス画像(最大9枚)
- セマンティック解析&思考モード(Proで強化): 画像生成の前に、連鎖的推論で構図、空間関係、ライティング、論理を分析
- 共有潜在空間へのマッピング: セマンティクスを視覚特徴へ直接マッピング—エンコーダ/デコーダの断絶なし
- 統合推論: 生成も編集も単一の最適化フローで実行。編集領域はバウンディングボックスで指定し、カラーパレットで比率を強制
- 出力: 高忠実度の画像(標準で768–2048×2048、Proで4K)、JPG/PNG/WEBPの選択、再現性のためのシード、安全性チェック
Wan2.7-Image-Pro徹底解説: 4K品質、思考モード、12言語テキスト描画でAI画像生成の新基準 - Apiyi.com Blog
思考モードのフローチャート(Pro)は、セマンティック解析→構図計画→推論チェックという流れを示し、直接生成に比べてアーティファクトが少なく、プロンプト遵守が高い。
多様なデータセットでの学習により、意図、ライティング、レイアウトの深い理解を可能にする。長文脈学習(arXiv研究で言及)が長文テキスト処理を支える。
Wan2.7-ImageとWan2.7-Image-Proの違い
両バージョンは同時リリースだが、Proはプロフェッショナルニーズをターゲットにする。
| 機能 | Wan2.7-Image(スタンダード) | Wan2.7-Image-Pro | 最適な用途 |
|---|---|---|---|
| 最大解像度 | 2048×2048 | 4096×4096(4K) | 印刷/量産(Pro) |
| 思考モード | 利用可能(より高速なデフォルト) | 強化/デフォルト(より深い推論) | 複雑シーン(Pro) |
| 構図安定性 | 強力 | セマンティック理解がさらに優れる | 商用プロジェクト(Pro) |
| 速度と品質 | 反復が速い | 高忠実度、やや時間が長い | プロトタイピング(標準) |
| 想定用途 | 一般クリエイター、SNS向け | エンタープライズデザイン、学術/印刷 | スケール vs 精密さ |
スタンダードは迅速なプロトタイピングに適し、Proは一貫性に優れた印刷対応4Kを提供する。
Wan2.7-Imageの使い方(ステップバイステップ)
1. プラットフォームにアクセス
- Alibaba Cloud(BaiLian platform)
- Wanxiang公式ツール
- CometAPI
2. ワークフローモードを選択
モードA: テキストから画像
プロンプト例:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
モードB: 画像編集
- 画像をアップロード
- 領域を選択
- 指示を入力
例:
Replace background with a futuristic city
モードC: マルチイメージ構成
- 複数のリファレンスをアップロード
- 構成ルールを定義
3. パラメータを微調整
- カラーパレット
- スタイル一貫性
- テキスト描画
4. 出力をエクスポート
- 高解像度画像
- 商用利用可能なアセット
ベンチマーク性能と競合比較
ブラインドの人間評価テストにおいて、Wan2.7-Imageはテキスト→画像の品質でGPT-Image-1.5を上回り、テキスト描画、フォトリアリズム、世界知識でNano Banana Proと同等かそれ以上を示した。
比較表:
| モデル | テキスト描画 | 指示追従性 | アバターカスタマイズ | マルチ画像参照 | 生成/編集の統合 | 解像度 | オープンソース/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | 優秀(12言語) | 優れている(思考モード) | 骨格レベル | 9 | あり | 2K–4K | あり/API |
| Midjourney V8 | 良い | 中程度 | 強いアーティスティック性 | 限定的 | なし | 高い | Discordのみ |
| FLUX | 良い | 強い(シンプルなケースで) | 良い | 限定的 | なし | 高い | あり |
| DALL-E 3 | 中程度 | 良い | 中程度 | なし | なし | 2K | API |
| Nano Banana Pro | 強い | 強力な編集 | 良い | 強い | 部分的 | 高い | クローズド |
Wan2.7-Imageは、統合ワークフロー、多言語テキスト、精密制御で先行し、特に非英語市場やプロフェッショナルなパイプラインで価値が高い。
CometAPIは大規模モデルAPIを一元的に統合・管理できるプラットフォームで、APIサービスのシームレスな連携を提供する。公式サイトより低価格で、GPT-image-1.5、Nano Banana series、Midjourney、Qwen Image Series など複数の画像生成APIをサポートする。
Wan2.7-Imageを使うべきユーザー
Wan2.7-Imageは、単発のアート生成だけでなく、スピードと柔軟性を必要とするチームに特に有用だ。これには、パフォーマンスマーケター、プロダクトデザイナー、ECスタジオ、ソーシャルコンテンツチーム、同一ブリーフから多数のバリアントを制作するエージェンシーが含まれる。マルチイメージ入力、マルチ出力生成、指示ベース編集への対応により、整合性、スピード、プロンプト制御が重要なワークフローで特に魅力的だ。
実運用のユースケース
- ゲーム/エンタメ: 数分で100体のユニークなNPCを生成
- マーケティング/EC: 正確なカラーパレットでブランド一貫のカルーセル
- 教育/アカデミア: 数式や表を含む印刷対応ポスター
- デザインエージェンシー: クリック編集で絵コンテとクライアント修正
参照統合のシームレスさと反復回数の削減が生産性を押し上げる。
結論:
Alibaba Wan2.7-Imageは、生成・編集・理解を統合することでAIクリエイティビティを再定義する。5つの中核機能、共有潜在空間、Proの強化により、競合がまだ苦戦するプロフェッショナル品質を実現する。SNS向けのプロトタイピングから、印刷対応の学術ビジュアル制作まで、比類ない精度と効率を提供する。
今すぐwan.video、またはCometAPIのAPI経由で開始しよう。開発者と企業にとって、パワー、アクセス性、データに裏打ちされた優位性の組み合わせにより、Wan2.7-Imageは2026年以降の統合型AI画像モデルの決定的リーダーとなる。