

GLM-5-Turboは、Zhipu AIが新たに発表した基盤LLMで、特にエージェント型ワークフロー向けに学習・調整されています(同社は対象エコシステムを OpenClaw /「ロブスター」シナリオと呼んでいます)。非常に長いコンテキスト(最大 ~200Kトークン)、ストリーミングおよび構造化出力、より低いツール呼び出しエラー率(サードパーティテストで報告値 ~0.67%)、そして大幅に低いトークン単価を提供します。このモデルは、単一ターンでのピーク処理性能をわずかに犠牲にする代わりに、はるかに高い安定性、ツール信頼性、スケジュール/永続タスク処理、長いチェーン実行を実現することを目指しており、自律エージェント、オーケストレーションシステム、マルチツールパイプラインに有用です。
GLM-5-Turboとは?
GLM-5-Turbo は、一般的なチャットモデルやマルチモーダルモデルではなく、エージェントのオーケストレーションと複雑な自動化ワークフローのために設計された基盤モデルとしてZhipuにより提示されています。設計上の重点は次のとおりです。
- ネイティブなエージェント向け学習(ツール使用、命令追従、時間指定/永続タスク)。
- 長時間セッション、メモリ、思考連鎖の計画を支える非常に大きなコンテキストウィンドウと出力容量。
- 長い業務フローやスケジュールタスクに対応する安定した高スループット推論。
チャットや文章生成向けに最適化された従来のLLMとは異なり、GLM-5-Turboは次の特徴を持ちます。
- エージェントファースト(チャットファーストではない)
- OpenClaw(「ロブスター」)環境向けに構築
- マルチステップの自律ワークフロー向けに設計
🦞 「Lobster Agent」とは何ですか?
「ロブスター」という概念は、ZhipuのAIエージェントエコシステム OpenClaw を指し、この環境ではモデルが以下を行います。
- ツールを動的に使用する
- 長いタスクチェーンを実行する
- 永続的なメモリを維持する
- ターミナル、アプリ、APIをまたいで動作する
GLM-5-Turboはこのパラダイム向けに深く最適化されており、次のような主要なエージェント課題を解決します。
- ツール呼び出しの信頼性
- タスク分解
- 長期的な計画
- 実行安定性
主な機能とその重要性
長いコンテキスト + 巨大な出力容量(200K / 128K)
200Kトークンのコンテキストウィンドウと128Kの出力能力により、GLM-5-Turboは次のことが可能です。
- 以前のコンテキスト(会話、ツール出力、中間結果)を長期にわたって保持する。
- コンテキストの繰り返し継ぎ足しなしに、非常に長い生成物(多段階計画、長文レポート、コードベース)を出力する。
- 正確な意思決定のために完全な実行履歴を保持しなければならないマルチターンエージェントを動かす。
これはエージェントのための意図的な技術選択です。短いプロンプトにタスクを分割するのではなく、エージェントは何千もの対話ターンやステップにわたって一貫した状態を維持できます。
学習に組み込まれたエージェント・プリミティブ
汎用モデルを後付けでエージェントタスクに適応させるのではなく、GLM-5-Turboはエージェント型の目的(例:ツール呼び出し動作、コマンド/引数解析)で学習されています。その結果として主張されているのは、ツール呼び出し時のハルシネーション減少、より安定したマルチステップ計画、長時間実行時のレイテンシ改善であり、これは多数の外部APIやツールを確実に連鎖させる必要がある自動化において価値があります。
スループットと実行安定性
GLM-5-Turboバリアントは、汎用大規模モデルと比較して、長い業務フローにおける実行安定性とスループットを改善しています。マーケティング文言では、類似モデルの中で「高スループット実行」と「先進的な応答安定性」を強調しています。これは、1つの失敗したステップがパイプライン全体を壊し得る企業向けエージェント導入において重要です。独立したサードパーティベンチマークはまだ出揃っていません。
GLM-5-Turboのベンチマークデータ
注: Zhipuは内部評価を公開しており、GLM-5に関するサードパーティ/学術ベンチマークも利用可能です。GLM-5-Turboは新しくリリースされたばかりのため、独立したコミュニティベンチマークの実行結果が出るまでには時間がかかります。以下では、最も根拠が明確で公開済みの数値と文脈を示します。
GLM-5(参考)— 公表されている代表的な指標
ZhipuのGLM-5(Turboに先行するフラッグシップモデル)は、多くのエンジニアリング/ワークフロータスクで強いスコアを報告しています。例えば次のとおりです。
- SWE-bench Verified: 77.8(GLM-5ドキュメントで、主要なオープンモデルスコアとして報告)
- Terminal Bench 2.0: 56.2(対象分布におけるオープンモデル最高性能として報告)
これらの数値は、GLM-5がソフトウェアエンジニアリングおよび実行タスクにおいて高い基準を持つことを示しています。一方、GLM-5-Turboは、生のモデル規模/パラメータ重視の一部を、より高いエージェント信頼性とスループットに置き換える位置付けです。GLM-5-Turboは比較実行において ~0.67% のツール呼び出しエラーを示し、比較対象となるGLM-5提供環境の ~2.33%〜6.41% より大幅に低いとされています。
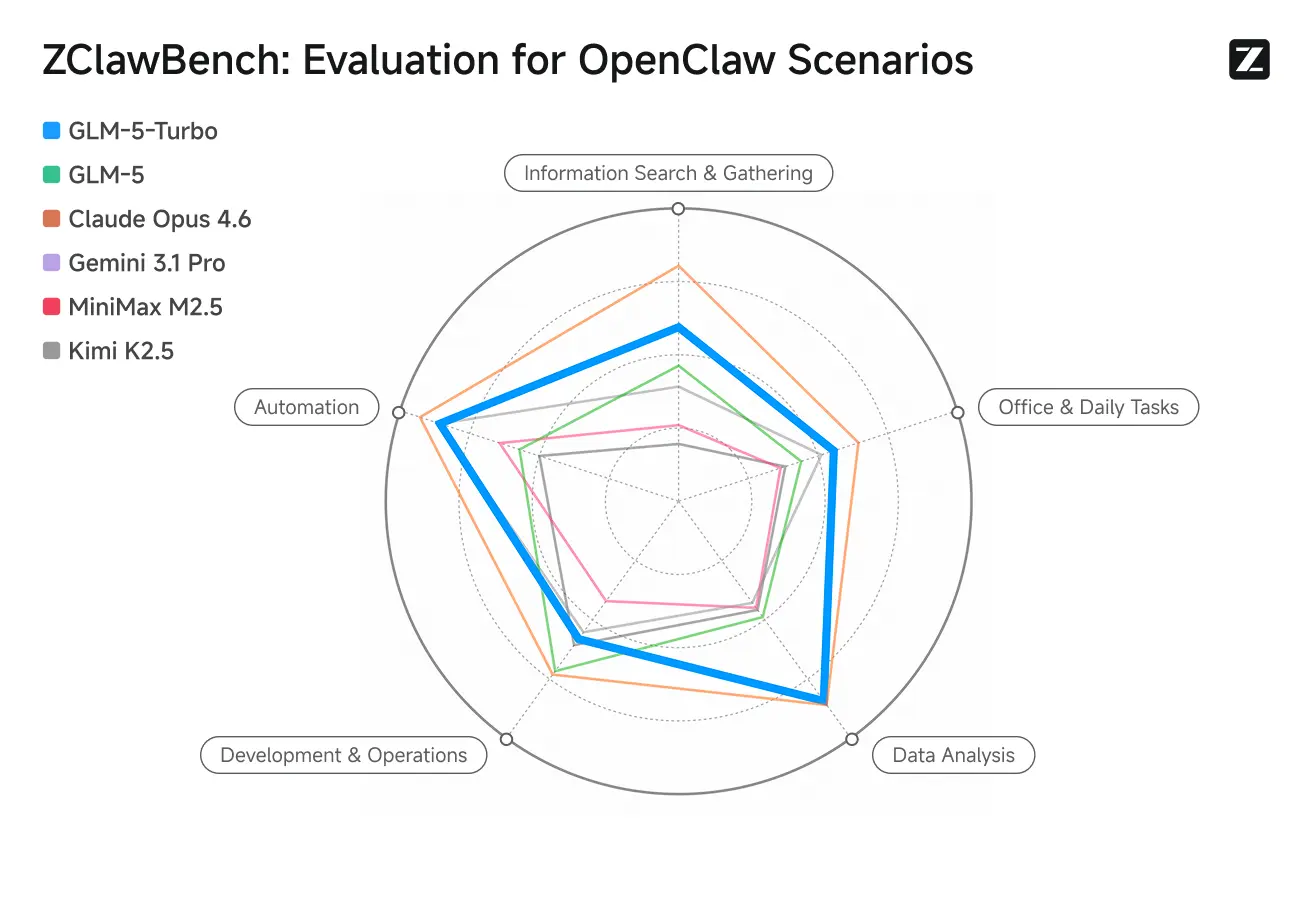
ZClawBench: OpenClawプロキシシナリオ向けベンチマークテスト
Zhipuはまた、インテリジェントエージェントを評価するためのZClawBenchベンチマークも公開しました。コード開発、データ分析、コンテンツ作成など多様な分野を対象としたブラインドテストでは、Pony-Alpha-2というコードネームの新モデルが回答者の90%から支持を得たとされています。
価格と提供状況(誰が販売し、いくらか)
Zhipuは、GLM-5-Turboのリリース時に ~20%のAPI価格引き上げ を実施し、同時にエージェント導入向けのトークン単価を平準化することを目的とした「Lobster Package」サブスクリプション層を導入しました。
報告されているサブスクリプションプラン(例)
代表的なLobsterパッケージ2種(価格は報告ベースの換算値で概算):
- Entry Lobsterプラン: ~39 CNY / 月 (~US$5.66) で 35,000,000トークン
- Mid Lobsterプラン: ~99 CNY / 月 (~US$14.36) で 100,000,000トークン
公表された数値に基づくと、100万トークンあたり のコストはおおよそ次のとおりです。
- Entryプラン: ~US$0.162 / 100万トークン
- Midプラン: ~US$0.144 / 100万トークン
これらの100万トークンあたりの数値は、公表されたサブスクリプション価格とトークン上限の単純換算であり、高ボリュームのエージェントワークロードにおける経済性を示しています。(計算は報道された通貨とトークン量に基づきます。)
API価格
代表的なマーケットプレイスである CometAPI の掲載では、GLM-5-Turbo は 入力100万トークンあたり$0.96、出力100万トークンあたり$3.20 です。
Zhipu自身の(Z.ai)開発者向け料金ページでは、GLM-5-Turboの直接料金がやや高く、入力100万トークンあたり$1.20、出力100万トークンあたり$4.00 とされています(キャッシュ済み入力料金はより低いです)。
GLM-5-Turbo vs GLM-5 — 比較一覧
大まかに言うと:
- GLM-5 = フラッグシップの汎用基盤モデル(強力な推論、コーディング、ベンチマーク性能)
- GLM-5-Turbo = GLM-5のエージェント最適化版(長いワークフロー、ツール使用、安定性に注力)
GLM-5-Turboは完全に新しいモデルアーキテクチャではなく、OpenClawのようなエージェントシステム向けに設計された、GLM-5の特化型・本番最適化バージョンです。
基本的な位置付け
| Model | Positioning |
|---|---|
| GLM-5 | 汎用フラッグシップLLM(推論、コーディング、ベンチマーク) |
| GLM-5-Turbo | エージェントファーストモデル(自動化、オーケストレーション、ツール利用) |
👉 簡単に言うと:
- GLM-5 を使う → 最大限の知能 が欲しいとき
- GLM-5-Turbo を使う → 安定した自動化 / エージェント が欲しいとき
エージェント能力の比較(最重要)
GLM-5(エージェント能力)は、すでに以下をサポートしています。
- ツール使用
- マルチステップ推論
- コーディングエージェント
ただし制限もあります。
- 長いチェーンでコンテキストを見失うことがある
- ツール呼び出し性能が時間とともに低下する場合がある
- より多くのオーケストレーションロジックを必要とする
GLM-5-Turboは明示的にエージェント向けに最適化されています。
主な改善点:
- ツール呼び出し信頼性 ↑
- タスク分解(計画) ↑
- 長いチェーンでの一貫性 ↑
- 永続的実行のサポート ↑
改善例:
- コンテキストを失うことなく 10ステップ以上 にわたって安定実行
👉 これは次にとって重要です。
- AutoGPTスタイルのシステム
- マルチエージェントワークフロー
- SaaS自動化
速度と効率
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inference speed | 中程度 | より高速 |
| Throughput | 標準 | より高い |
| Long-task latency | 低下する場合あり | 最適化済み |
GLM-5-Turboは、実際の業界課題を解決するために設計されています。
大規模モデルは長いワークフロー中に遅くなったり破綻したりする
価格比較
| Model | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turboはより高価です(~20%高い)
なぜ高いのか?
なぜなら、次を提供するためです。
- より優れたオーケストレーション信頼性
- より高い本番安定性
- エージェント専用の最適化
👉 エンタープライズでは:
- トークン単価は高くなる
- しかし 失敗コスト + 再試行 を削減できる
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primary goal | 汎用フラッグシップ基盤モデル(幅広い能力、強力なコーディング/ベンチマーク) | エージェント/“OpenClaw” / ロブスター最適化基盤モデル |
| Context window | (高水準と報告あり。GLM-5は~200Kに注力(GLM-5も長いコンテキストをサポート)) | 200,000トークン(明示的に文書化済み) |
| Maximum output tokens | (大容量、モデル依存) | 128,000トークン(文書化済み) |
| Notable benchmark scores | SWE-bench: 77.8; Terminal Bench 2.0: 56.2(GLM-5報告値) | 内部評価では、エージェントワークフロー向けに長いチェーンの安定性とスループット改善を主張。独立した公開ベンチマークは保留中。 |
| Modalities | テキスト(主)、GLMファミリーには兄弟モデルとしてビジョン版あり | テキストのみ(ドキュメントによる)— ツールベースのエージェント向けに最適化 |
| Recommended use cases | 幅広い用途: チャット、コード、推論、コンテンツ | エージェントのオーケストレーション、ツール呼び出し、長期自動化 |
| Pricing | 既存のGLM-5価格(プランにより異なる) | 新規リリース — API価格は~20%引き上げと報告、新たなLobsterサブスクリプション層を導入 |
GLM-5-Turboの使い方
CometAPI — 多数のモデルに単一APIでアクセス(OpenAI互換)
CometAPIではGLM-5-Turboが利用可能として掲載されており、OpenAI互換のベースURLとSDKが提供されています。公開されているモデル文字列を使用してください(サイトにはGLM-5-Turboが同様の価格で掲載されています)。以下はCometAPIドキュメントをもとにした例です。
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // またはCometAPI UIに表示されている正確なモデルslugを使用 "messages": [{"role":"user","content":"新入社員オンボーディングのための5ステップのチェックリストを作成してください。"}], "max_tokens": 800 }'
CometAPIの価値は、アグリゲーターとしての利便性(多くのモデルを単一統合で扱えること)にあります。呼び出し前に、CometAPIダッシュボードで正確なモデルslugを確認してください。
GLM-5-TurboでLobster / OpenClawエージェントを構築する際のベストプラクティス
- 生のレイテンシではなく信頼性を重視して設計する: Turboの利点は、長いチェーンでのツール呼び出し失敗率が低いことです。エージェント実行は、わずかな初回トークン速度よりも堅牢な完了(再試行、冪等なツール呼び出し)を優先するよう構成しましょう。
- ストリーミングと段階的なツール呼び出しを使う: ストリーミング/チャンク出力を活用して再作業を減らし、適切な場面では早期のツール呼び出しを可能にしましょう。GLM-5-Turboはストリーミングをサポートしています。
- パーサ向けに構造化出力を使う: 下流ツールで決定的に解析できるよう、JSONや整形式の結果を優先してください。Turboは構造化出力をサポートします。
- スケジューリング/永続性を前提に設計する: エージェントが定期的に確認したりバックグラウンドタスクを実行したりする必要がある場合は、Turboの優れた時間処理セマンティクスとキャッシュ機能を使って、毎サイクル再計画することを避けましょう。
- ツール呼び出しとフォールバックを計測する: ツール呼び出しをログに残し、適切なフォールバック(例: 温度を少し変えて再試行する、バックアップツールを呼ぶ)を設計してください。エージェント型ワークフローは、単一の外部API障害でも壊れやすいためです。Turboはエラー率を下げますが、外部障害そのものをなくすわけではありません。
開発者は現在、CometAPI 経由で GLM-5 および GLM-5 turbo API にアクセスできます。開始するには、詳細な手順について API guide を参照してください。アクセス前に、CometAPIにログインし、APIキーを取得していることを確認してください。CometAPI は、統合を支援するために公式価格より大幅に低い価格を提供しています。
準備はできましたか?→ 今すぐ GLM-5 と GLM-5 turbo に登録 !